Python 官方文档:入门教程 => 点击学习
转载请注明作者和出处:Http://blog.csdn.net/john_bh/ 一、简介二、FastText原理2.1 模型架构2.2 层次SoftMax2.3 N-gram特征三、 基于fastText实现文本分类3.1 fast
转载请注明作者和出处:Http://blog.csdn.net/john_bh/
fasttext是facebook开源的一个词向量与文本分类工具,在2016年开源,典型应用场景是“带监督的文本分类问题”。提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
fastText结合了自然语言处理和机器学习中最成功的理念。这些包括了使用词袋以及n-gram袋表征语句,还有使用子字(subword)信息,并通过隐藏表征在类别间共享信息。我们另外采用了一个softmax层级(利用了类别不均衡分布的优势)来加速运算过程。
这些不同概念被用于两个不同任务:
举例来说:fastText能够学会“男孩”、“女孩”、“男人”、“女人”指代的是特定的性别,并且能够将这些数值存在相关文档中。然后,当某个程序在提出一个用户请求(假设是“我女友现在在儿?”),它能够马上在fastText生成的文档中进行查找并且理解用户想要问的是有关女性的问题。
fastText方法包含三部分,模型架构,层次SoftMax和N-gram特征。
fastText的架构和word2vec中的CBOW的架构类似,因为它们的作者都是Facebook的科学家Tomas Mikolov,而且确实fastText也算是words2vec所衍生出来的。
Continuous Bog-Of-Words:
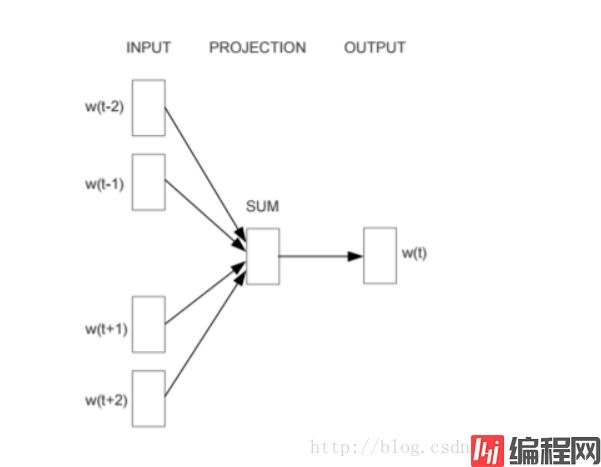
fastText
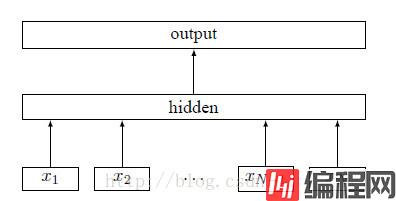
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。 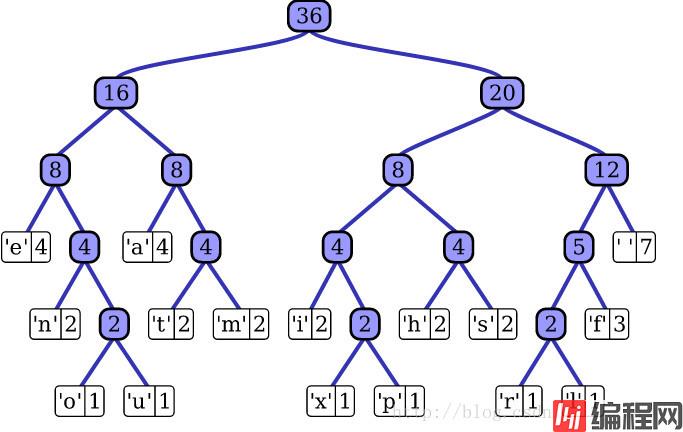
fastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然啦,为了提高效率,我们需要过滤掉低频的 N-gram。
fastText做文本分类要求文本是如下的存储形式:
__label__2 , birchas chaim , yeshiva birchas chaim is a orthodox jewish mesivta high school in lakewood township new jersey . it was founded by rabbi shmuel zalmen stein in 2001 after his father rabbi chaim stein asked him to open a branch of telshe yeshiva in lakewood . as of the 2009-10 school year the school had an enrollment of 76 students and 6 . 6 classroom teachers ( on a fte basis ) for a student–teacher ratio of 11 . 5 1 .
__label__6 , motor torpedo boat pt-41 , motor torpedo boat pt-41 was a pt-20-class motor torpedo boat of the united states navy built by the electric launch company of bayonne new jersey . the boat was laid down as motor boat submarine chaser ptc-21 but was reclassified as pt-41 prior to its launch on 8 july 1941 and was completed on 23 july 1941 .
__label__11 , passiflora picturata , passiflora picturata is a species of passion flower in the passifloraceae family .
__label__13 , naya din nai raat , naya din nai raat is a 1974 bollywood drama film directed by a . bhimsingh . the film is famous as sanjeev kumar reprised the nine-role epic perfORMance by sivaji ganesan in navarathri ( 1964 ) which was also previously reprised by akkineni nageswara rao in navarathri ( telugu 1966 ) . this film had enhanced his status and reputation as an actor in hindi cinema .其中前面的label是前缀,也可以自己定义,label后接的为类别。
具体代码:
# -*- coding:utf-8 -*-
import pandas as pd
import random
import fasttext
import jieba
from sklearn.model_selection import train_test_split
cate_dic = {'technology': 1, 'car': 2, 'entertainment': 3, 'military': 4, 'sports': 5}
"""
函数说明:加载数据
"""
def loadData():
#利用pandas把数据读进来
df_technology = pd.read_csv("./data/technology_news.csv",encoding ="utf-8")
df_technology=df_technology.dropna() #去空行处理
df_car = pd.read_csv("./data/car_news.csv",encoding ="utf-8")
df_car=df_car.dropna()
df_entertainment = pd.read_csv("./data/entertainment_news.csv",encoding ="utf-8")
df_entertainment=df_entertainment.dropna()
df_military = pd.read_csv("./data/military_news.csv",encoding ="utf-8")
df_military=df_military.dropna()
df_sports = pd.read_csv("./data/sports_news.csv",encoding ="utf-8")
df_sports=df_sports.dropna()
technology=df_technology.content.values.tolist()[1000:21000]
car=df_car.content.values.tolist()[1000:21000]
entertainment=df_entertainment.content.values.tolist()[:20000]
military=df_military.content.values.tolist()[:20000]
sports=df_sports.content.values.tolist()[:20000]
return technology,car,entertainment,military,sports
"""
函数说明:停用词
参数说明:
datapath:停用词路径
返回值:
stopwords:停用词
"""
def getStopWords(datapath):
stopwords=pd.read_csv(datapath,index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
stopwords=stopwords["stopword"].values
return stopwords
"""
函数说明:去停用词
参数:
content_line:文本数据
sentences:存储的数据
cateGory:文本类别
"""
def preprocess_text(content_line,sentences,category,stopwords):
for line in content_line:
try:
segs=jieba.lcut(line) #利用结巴分词进行中文分词
segs=filter(lambda x:len(x)>1,segs) #去掉长度小于1的词
segs=filter(lambda x:x not in stopwords,segs) #去掉停用词
sentences.append("__lable__"+str(category)+" , "+" ".join(segs)) #把当前的文本和对应的类别拼接起来,组合成fasttext的文本格式
except Exception as e:
print (line)
continue
"""
函数说明:把处理好的写入到文件中,备用
参数说明:
"""
def writeData(sentences,fileName):
print("writing data to fasttext format...")
out=open(fileName,'w')
for sentence in sentences:
out.write(sentence.encode('utf8')+"\n")
print("done!")
"""
函数说明:数据处理
"""
def preprocessData(stopwords,saveDataFile):
technology,car,entertainment,military,sports=loadData()
#去停用词,生成数据集
sentences=[]
preprocess_text(technology,sentences,cate_dic["technology"],stopwords)
preprocess_text(car,sentences,cate_dic["car"],stopwords)
preprocess_text(entertainment,sentences,cate_dic["entertainment"],stopwords)
preprocess_text(military,sentences,cate_dic["military"],stopwords)
preprocess_text(sports,sentences,cate_dic["sports"],stopwords)
random.shuffle(sentences) #做乱序处理,使得同类别的样本不至于扎堆
writeData(sentences,saveDataFile)
if __name__=="__main__":
stopwordsFile=r"./data/stopwords.txt"
stopwords=getStopWords(stopwordsFile)
saveDataFile=r'train_data.txt'
preprocessData(stopwords,saveDataFile)
#fasttext.supervised():有监督的学习
classifier=fasttext.supervised(saveDataFile,'classifier.model',lable_prefix='__lable__')
result = classifier.test(saveDataFile)
print("P@1:",result.precision) #准确率
print("R@2:",result.recall) #召回率
print("Number of examples:",result.nexamples) #预测错的例子
#实际预测
lable_to_cate={1:'technology'.1:'car',3:'entertainment',4:'military',5:'sports'}
texts=['中新网 日电 2018 预赛 亚洲区 强赛 中国队 韩国队 较量 比赛 上半场 分钟 主场 作战 中国队 率先 打破 场上 僵局 利用 角球 机会 大宝 前点 攻门 得手 中国队 领先']
lables=classifier.predict(texts)
print(lables)
print(lable_to_cate[int(lables[0][0])])
#还可以得到类别+概率
lables=classifier.predict_proba(texts)
print(lables)
#还可以得到前k个类别
lables=classifier.predict(texts,k=3)
print(lables)
#还可以得到前k个类别+概率
lables=classifier.predict_proba(texts,k=3)
print(lables)
# -*- coding:utf-8 -*-
import pandas as pd
import random
import fasttext
import jieba
from sklearn.model_selection import train_test_split
cate_dic = {'technology': 1, 'car': 2, 'entertainment': 3, 'military': 4, 'sports': 5}
"""
函数说明:加载数据
"""
def loadData():
#利用pandas把数据读进来
df_technology = pd.read_csv("./data/technology_news.csv",encoding ="utf-8")
df_technology=df_technology.dropna() #去空行处理
df_car = pd.read_csv("./data/car_news.csv",encoding ="utf-8")
df_car=df_car.dropna()
df_entertainment = pd.read_csv("./data/entertainment_news.csv",encoding ="utf-8")
df_entertainment=df_entertainment.dropna()
df_military = pd.read_csv("./data/military_news.csv",encoding ="utf-8")
df_military=df_military.dropna()
df_sports = pd.read_csv("./data/sports_news.csv",encoding ="utf-8")
df_sports=df_sports.dropna()
technology=df_technology.content.values.tolist()[1000:21000]
car=df_car.content.values.tolist()[1000:21000]
entertainment=df_entertainment.content.values.tolist()[:20000]
military=df_military.content.values.tolist()[:20000]
sports=df_sports.content.values.tolist()[:20000]
return technology,car,entertainment,military,sports
"""
函数说明:停用词
参数说明:
datapath:停用词路径
返回值:
stopwords:停用词
"""
def getStopWords(datapath):
stopwords=pd.read_csv(datapath,index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
stopwords=stopwords["stopword"].values
return stopwords
"""
函数说明:去停用词
参数:
content_line:文本数据
sentences:存储的数据
category:文本类别
"""
def preprocess_text(content_line,sentences,stopwords):
for line in content_line:
try:
segs=jieba.lcut(line) #利用结巴分词进行中文分词
segs=filter(lambda x:len(x)>1,segs) #去掉长度小于1的词
segs=filter(lambda x:x not in stopwords,segs) #去掉停用词
sentences.append(" ".join(segs))
except Exception as e:
print (line)
continue
"""
函数说明:把处理好的写入到文件中,备用
参数说明:
"""
def writeData(sentences,fileName):
print("writing data to fasttext format...")
out=open(fileName,'w')
for sentence in sentences:
out.write(sentence.encode('utf8')+"\n")
print("done!")
"""
函数说明:数据处理
"""
def preprocessData(stopwords,saveDataFile):
technology,car,entertainment,military,sports=loadData()
#去停用词,生成数据集
sentences=[]
preprocess_text(technology,sentences,stopwords)
preprocess_text(car,sentences,stopwords)
preprocess_text(entertainment,sentences,stopwords)
preprocess_text(military,sentences,stopwords)
preprocess_text(sports,sentences,stopwords)
random.shuffle(sentences) #做乱序处理,使得同类别的样本不至于扎堆
writeData(sentences,saveDataFile)
if __name__=="__main__":
stopwordsFile=r"./data/stopwords.txt"
stopwords=getStopWords(stopwordsFile)
saveDataFile=r'unsupervised_train_data.txt'
preprocessData(stopwords,saveDataFile)
#fasttext.load_model:不管是有监督还是无监督的,都是载入一个模型
#fasttext.skipgram(),fasttext.cbow()都是无监督的,用来训练词向量的
model=fasttext.skipgram('unsupervised_train_data.txt','model')
print(model.words) #打印词向量
#cbow model
model=fasttext.cbow('unsupervised_train_data.txt','model')
print(model.words) #打印词向量
相似处:
不同处:
两者本质的不同,体现在 h-softmax的使用:
总的来说,fastText的学习速度比较快,效果还不错。fastText适用与分类类别非常大而且数据集足够多的情况,当分类类别比较小或者数据集比较少的话,很容易过拟合。
可以完成无监督的词向量的学习,可以学习出来词向量,来保持住词和词之间,相关词之间是一个距离比较近的情况;
也可以用于有监督学习的文本分类任务,(新闻文本分类,垃圾邮件分类、情感分析中文本情感分析,电商中用户评论的褒贬分析)
--结束END--
本文标题: fasttext的python实现---
本文链接: https://www.lsjlt.com/news/184376.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0