Python 官方文档:入门教程 => 点击学习
正则表达式解释:符合某个模式(规则)的文本在线测试工具:https://tool.oschina.net/regex详细的正则表达式规则,可见:Http://www.runoob.com/python3/python3-reg-expre
正则表达式
解释:符合某个模式(规则)的文本
在线测试工具:https://tool.oschina.net/regex
详细的正则表达式规则,可见:Http://www.runoob.com/python3/python3-reg-expressions.html
re模块
概述:re为正则表达式提供了很多api,对正则表达式的使用提供了便利。
修饰符:
1、re.I:忽略大小写
2、re.M:多行匹配
3、re.S:是.匹配包括换行在内的所有字符
方法:match()
参数:正则表达式,待匹配的字符串,修饰符,返回一个SRE.Match对象
代码演示:content = 'Hello World Python3.6' pattern = '^\w{5}\s\w{5}\s[p]+\w{5}\d\S\d' result = re.match(pattern,content,re.I) print(result.group())SRE.Match对象的方法有:
group():返回匹配的内容
span():匹配的范围
贪婪模式和非贪婪模式
贪婪匹配:.*会匹配尽可能多的字符
非贪婪匹配:格式是.?,或匹配尽可能少的字符
re模块其他方法
search():和match()类似,但match从字符串开头就开始匹配,若匹配不到就会返回None,而search则不会;
findall():获得所有匹配的内容
sub():修改文本
compile():将正则表达式编译成对象,可重复使用
代码演示:content = 'birthday:19970704' result = re.sub('\d','5',content)#参数:正则表达式,被替换字符串,被修改文本 print(result)
爬取虎扑网球员得分榜
首先打开虎扑网,切到得分榜页面:https://nba.hupu.com/stats/players/pts
点击下一页,查看得分榜51-100的球员,发现此时链接变成:https://nba.hupu.com/stats/players/pts/2 ,多点几页就会发现得分榜链接的构造是:https://nba.hupu.com/stats/players/pts/ + 页数
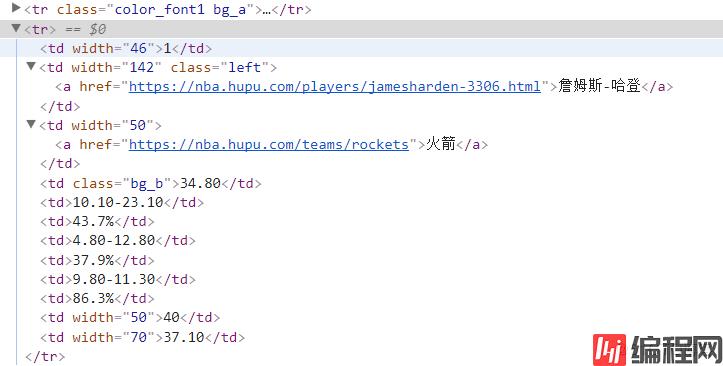
再查看元素(按F12),发现表格的每一行是这么组成的:
于是就可以写正则表达式了,需要获取的内容用括号括起来
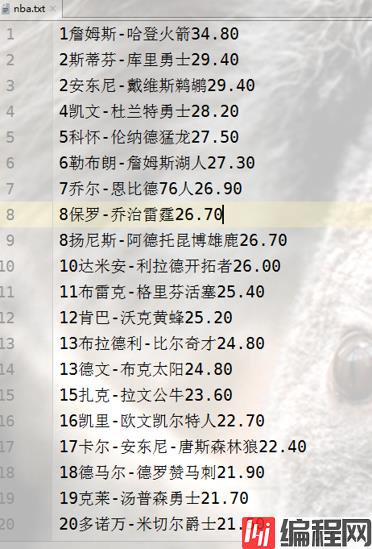
代码如下:import requests import re def get_Page(url): #获取网页内容 headers = { 'User-Agent': 'Mozilla/5.0 (windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6' } response = requests.get(url,headers=headers) if response.status_code == 200: return response.text else: print('您输入的网址错误!') def parse_page(html): #解析网页 pattern = '<tr>.*?<td.*?>(.*?)</td>.*?<td.*?><a.*?>(.*?)</a></td>.*?<td.*?><a.*?>(.*?)</a></td>.*?<td.*?>(.*?)</td>.*?' items = re.findall(pattern, html,re.S) # for item in items: # print(item[0],item[1],item[2],item[3]) return items def save(content): with open('nba.txt','a',encoding='utf-8') as f: for item in content: f.writelines(item) f.write('\n') if __name__ == '__main__': #保存前得分榜150名 base_url = 'https://nba.hupu.com/stats/players/pts/' for i in range(1,4): url = base_url + str(i) html = get_Page(url) reslut = parse_page(html) save(reslut)结果展示:
--结束END--
本文标题: 利用requests和正则表达式爬取虎扑
本文链接: https://www.lsjlt.com/news/185554.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0