Python 官方文档:入门教程 => 点击学习
python利用百度做url采集pip install tableprintparamiko==2.0.8语法:Python url_collection.py -h输出帮助信息python url_collection.py 要采集的信息
python利用百度做url采集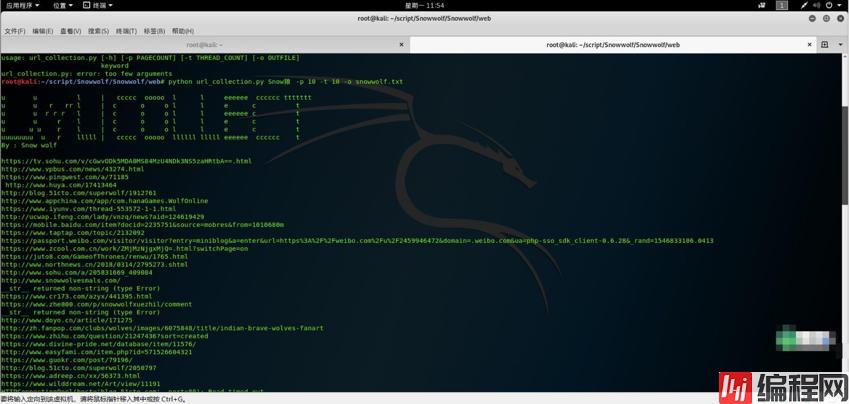
pip install tableprint
paramiko==2.0.8
语法:Python url_collection.py -h输出帮助信息
python url_collection.py 要采集的信息 -p 页数 -t 进程数 -o 保存的文件名以及格式
新建文件touch url_collection.py
写入代码正式部分
#coding: utf-8
import requests
from bs4 import BeautifulSoup as bs
import re
from Queue import Queue
import threading
from argparse import ArgumentParser
loGo="""
u u l | ccccc ooooo l l eeeeee cccccc ttttttt
u u r rr l | c o o l l e c t
u u r r r l | c o o l l eeeeee c t
u u r l | c o o l l e c t
u u u r l | c o o l l e c t
uuuuuuuu u r lllll | ccccc ooooo llllll lllll eeeeee cccccc t
By : Snow wolf
"""
print(logo)
arg = ArgumentParser(description='baidu_url_collect py-script by snowwolf')
arg.add_argument('keyWord',help='keyword like inurl:.?id= for searching sqli site')
arg.add_argument('-p','--page', help='page count', dest='pagecount', type=int)
arg.add_argument('-t','--thread', help='the thread_count', dest='thread_count', type=int, default=10)
arg.add_argument('-o','--outfile', help='the file save result', dest='outfile', default='result.txt')
result = arg.parse_args()
headers = {'User-Agent':'Mozilla/5.0 (windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'}
class Bd_url(threading.Thread):
def init(self, que):
threading.Thread.init(self)
self._que = que
def run(self):
while not self._que.empty():
URL = self._que.get()
try:
self.bd_url_collect(URL)
except Exception,e:
print e
pass
def bd_url_collect(self, url):
r = requests.get(url, headers=headers, timeout=3)
soup = bs(r.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for bq in bqs:
r = requests.get(bq['href'], headers=headers, timeout=3)
if r.status_code == 200:
print r.url
with open(result.outfile, 'a') as f:
f.write(r.url + '\n')def main():
thread = []
thread_count = result.thread_count
que = Queue()
for i in range(0,(result.pagecount-1)*10,10):
que.put('https://www.baidu.com/s?wd=' + result.keyword + '&pn=' + str(i))
for i in range(thread_count):
thread.append(Bd_url(que))
for i in thread:
i.start()
for i in thread:
i.join()if name == 'main':
main()
代码结束
--结束END--
本文标题: python url采集
本文链接: https://www.lsjlt.com/news/189849.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0