Python 官方文档:入门教程 => 点击学习
通过python程序模拟访问北京预约挂号统一平台,包括验证码识别、登陆、按医院、时间、科室查询可约号等。 本程序仅为学习使用,请勿用于其他用途。 1.获取验证码图片 def getCodePic(): randNum = rando
通过python程序模拟访问北京预约挂号统一平台,包括验证码识别、登陆、按医院、时间、科室查询可约号等。
本程序仅为学习使用,请勿用于其他用途。
def getCodePic():
randNum = random.random()
url = "Http://www.bjguahao.Gov.cn/comm/code.PHP?id="+str(randNum)
resp = urllib2.urlopen(url)
tmp_pic="c:\\tmp.gif"
open(tmp_pic,"wb").write(resp.read())
return tmp_pic#识别 ”http://www.bjguahao.gov.cn/comm/logon.php“验证码
#验证码特征如下:
#1.验证码图片大小为38*15(宽*高);
#2.验证码包为4个1-9的数字;
#3.数字大小为6*8(宽*高),数字区域据距图片(左上右下)的边距分别为(5,4,6,3),每个数字间隔1个像素;
#4.数字颜色为红色,有粉色干扰噪点。
#
#识别方法:
#1.由于验证码比较简单且固定,可先获取1-9每个数字的样本;
#2.提取验证码中的每个数字,与样本进行比对,获取具体的数字。
#1-9的数据样本
yzm_keys={
1:"001100011100101100001100001100001100001100111111",
2:"011110110011110011000011001110011000110000111111",
3:"011110110011000011011110000011000011110011011110",
4:"000011000111001111011011110011111111000011000011",
5:"111111110000111110110011000011000011110011011110",
6:"011110110011110000111110110011110011110011011110",
7:"111111000011000110000110001100001100011000011000",
8:"011110110011110011011110110011110011110011011110",
9:"011110110011110011110011011111000011110011011110",
}
#识别一个数字
def reg_one(im):
ss=""
for y in range(0,8):
for x in range(0,6):
v = im.getpixel((x,y))
if v==3:
ss+="1"
else:
ss+='0'
for i in range(1,10):
if yzm_keys[i] == ss:
return i
print "reg failed."
#传入验证码图片,识别4位验证码
def reg_yzm(f):
im = Image.open(f)
im1 = im.crop(( 5,4,11,12))
im2 = im.crop((12,4,18,12))
im3 = im.crop((19,4,25,12))
im4 = im.crop((26,4,32,12))
return "%d%d%d%d" %(reg_one(im1),reg_one(im2),reg_one(im3),reg_one(im4))需要事先注册。然后通过身份证,名字和验证码登陆。这里需要考虑Cookies问题,在后面说明。
def login(code):
url = "http://www.bjguahao.gov.cn/comm/logon.php"
req = urllib2.Request(url,urllib.urlencode({"sfzhm":"0000000000000000","truename":"张三","yzm":code})) #身份证和名字需要按实际情况填写
resp = urllib2.urlopen(req)
res = resp.read()
if len(res)==0:
print "login success."
else:
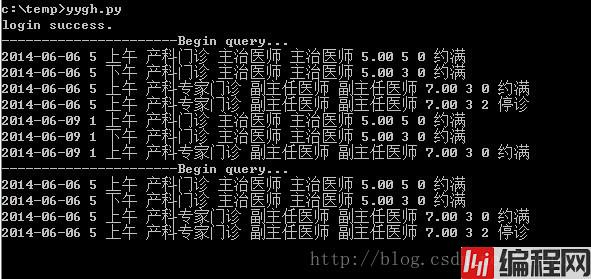
print "error:",res以下代码查询指定日期,航空总医院的产科门诊和产科专家门诊的预约情况。返回值为html。
def query(riqi):
hpid='166' #航空总医院
keid1='050142' #产科门诊
keid2='050143' #产科专家
url = "http://www.bjguahao.gov.cn/comm/ghao.php"
req1 = "%s?hpid=%s&keid=%s&date1=%s" %(url,hpid,keid1,riqi)
resp1 = urllib2.urlopen(req1)
req2 = "%s?hpid=%s&keid=%s&date1=%s" %(url,hpid,keid2,riqi)
resp2 = urllib2.urlopen(req2)
return resp1.read(),resp2.read()通过解析查询结果的HTML,输出信息。
def parse_print(html1,html2):
#print "%10s %4s %4s %16s %16s %16s %4s %4s %4s %4s %4s" %('日期','星期','时间','科室','医生','职称','费用','专长','可挂','剩余','状态')
seq1,seq2=parse_html.parse(html1)
if len(seq1) == 11 :
seq1.remove(seq1[7])
for i in seq1:
print i,
print ""
if len(seq2) == 11 :
seq2.remove(seq2[7])
for i in seq2:
print i,
print ""
seq1,seq2=parse_html.parse(html2)
if len(seq1) == 11 :
seq1.remove(seq1[7])
for i in seq1:
print i,
print ""
if len(seq2) == 11 :
seq2.remove(seq2[7])
for i in seq2:
print i,
print ""parse_html.py如下
#!/usr/bin/Python
# -*- coding: utf-8 -*-
def parse_struct(s):
stru=[]
while len(s)>3:
i1 = s.find("<td>")
i2 = s.find("</td>")
if i1<0 or i2<0:
break
t = s[i1+4:i2]
stru.append(t)
#print t
s = s[i2+5:]
return stru
def parse(ss):
tr_end_1 = ss.rfind("</tr>")
tr_beg_1 = ss.rfind("<tr>")
tr_end_2 = ss.rfind("</tr>",0,tr_beg_1)
tr_beg_2 = ss.rfind("<tr>",0,tr_end_2)
s1 = ss[tr_beg_2+5:tr_end_2]
s2 = ss[tr_beg_1+5:tr_end_1]
seq1= parse_struct(s1)
seq2= parse_struct(s2)
#for i in seq1:
# print i
return seq1,seq2
if __name__ == "__main__":
parse(open("c:\\2014-04-23.html","rb").read())这一部分还没写,原理基本差不多,生成要预约人的url,进行请求。会向手机发送一个验证码,然后输入验证码,预约成功。
Cookies是啥?为啥需要Cookies?这里就不细说了,感兴趣的可以baidu之。这里就说怎么设置。
其实也很简单,Python的urllib2模块本身就支持设置Cookies的功能。
cj = cookielib.Cookiejar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [
#('Host','www.bjguahao.gov.cn'),
('User-Agent','Mozilla/5.0 (windows NT 6.1; rv:27.0) Gecko/20100101 Firefox/27.0'),
#('Accept','image/png,image*;q=0.5'),
#('Accept-Language','zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3'),
#('Accept-Encoding','gzip,deflate'),
('Referer','http://www.bjguahao.gov.cn/comm/index.html'),
#('Connection','keep-alive'),
#('Cookie','Hm_lvt_13e29334f151c8514bf6cf2533b9d9af=1395393461,1396936299,1397179537,1397461271; __c_review_45359=3; __c_last_45359=1397465208535; __c_visitor=1395393460566784; __c_sesslist_45359=drcwufogsr_cha%252Cdr9bf2510a_ch7%252Cch4; __c_today_45359=1; PHPSESSID=67003ba345132df2ef80474312c7b669; __c_pv_45359=21; __c_session_45359=1397461271515659; __c_session_at_45359=1397466158924; Hm_lpvt_13e29334f151c8514bf6cf2533b9d9af=1397465209')
]
urllib2.install_opener(opener)--结束END--
本文标题: Python程序访问北京预约挂号平台
本文链接: https://www.lsjlt.com/news/190755.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0