Python 官方文档:入门教程 => 点击学习
前言 你有没有想过,当我们在某个网站上登陆时,网站是如何通过验证的,我们都提交给了网站哪些信息,浏览器都发起了哪些请求? 下图是某个网站的登陆界面,接下来就让我们通过命令行模拟浏览器实现登陆操作,看看一个简单的登陆操作,具
下图是某个网站的登陆界面,接下来就让我们通过命令行模拟浏览器实现登陆操作,看看一个简单的登陆操作,具体是如何实现的。
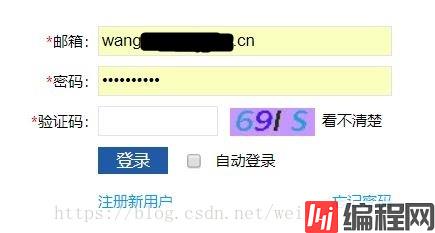
首先,我们先来明确登陆该网站的所有步骤:
import requests
import time
from io import BytesIO
from PIL import Image
import re
from lxml import etreepython-requests字样,使服务器一眼就能识别我们是爬虫程序。为了更加完美的模拟浏览器,我们不妨多写几行代码。# http请求头
header = {
"accept":"*text()")
myCollection**都是我自己取的。
subsite_html = s.get(subsite_url)
re.compile("myCollection\\d+").findall(subsite_html.text)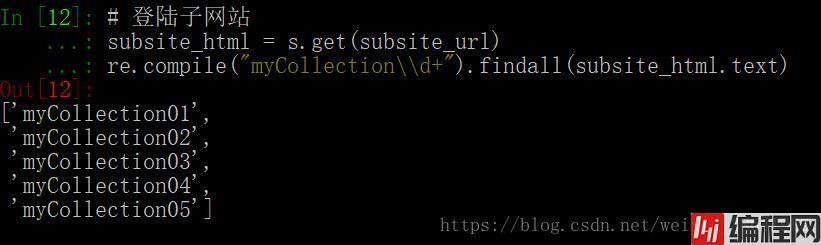
loGout_url网址就可以了。此时我们再去请求子网站就不能获得收藏的信息了,而是被跳转到登陆页面。最后,不要忘记关闭hui’hsession。s.get(logout_url)
s.close()
本帖仅供学习交流,请勿用于其它用途。
--结束END--
本文标题: 使用python模拟浏览器实现登陆
本文链接: https://www.lsjlt.com/news/191459.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0