Python 官方文档:入门教程 => 点击学习
目录前沿AlexNet(2012)VGG(2014)GoogleNet(2014)ResNet(2015)MobileNet v1MobileNet v2MobileNet v3Sh
在CV领域,我们需要熟练掌握最基本的知识就是各种卷积神经网络CNN的模型架构,不管我们在图像分类或者分割,目标检测,NLP等,我们都会用到基本的CNN网络架构。
CNN从最初的2012年AlexNet横空出世到2014年VGG席卷世界以及2015年ResNet奠定了该领域的霸主地位,网络模型变得越变越深,而且也得到证明,越深的网络拟合效果越好,但网络相应的参数量计算量都极速增加,不利于技术的推广和应用。
因此,一些轻量级的网络结构也慢慢随之出现,比如MobileNet系列,ShuffleNet系列,以及ResNext、DenseNet、EfficenceNet等模型,他们都互相吸取彼此的优点,不但降低了参数量或者计算量,同时分类精度更高,因而受到了更多的关注。
接下来我们就对CNN的各种网络结构以及他们的优缺点进行一次详细的解读!
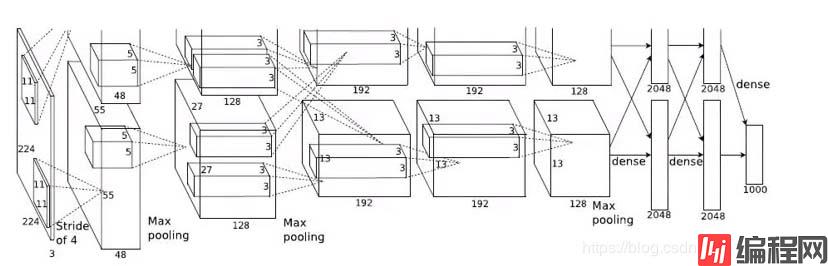
1、增加了relu非线性激活函数,增强了模型的非线性表达能力。成为以后卷积层的标配。
2、dropout层防止过拟合,成为以后fc层的标配。
3、通过数据增强,来减少过拟合。
4、引入标准化层(Local Response NORMalization):通过放大那些对分类贡献较大的神经元,抑制那些对分类贡献较小的神经元,通过局部归一的手段,来达到作用。
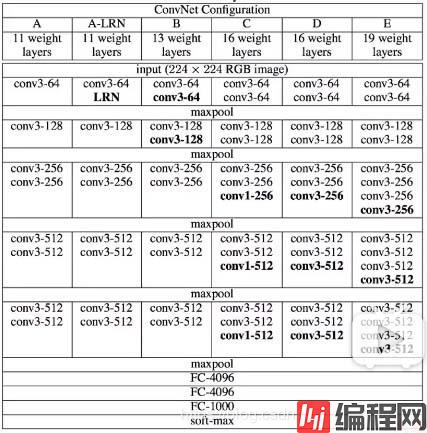
论文的主要创新点在于:
1、用3x3小卷积核代替了5x5或者7x7的卷积核
2、基于ALexnet加深了网络深度,证明了更深的网络,能更好的提取特征。

在设计网络结构时,不仅仅考虑网络的深度,也会考虑网络的宽度,并将这种结构定义为Inception结构。
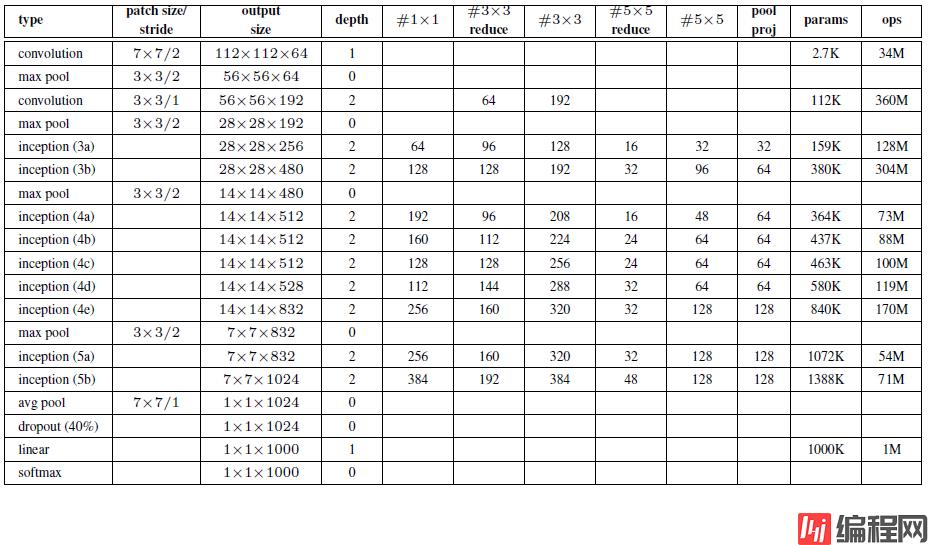
1、引入1x1卷积的主要目的是为了减少维度,还用于修正线性激活(ReLU)
2、网络最后采用了average pooling(平均池化)来代替全连接层
后面的Inception v2/v3都是基于v1的这种方法在扩展,主要目标有:
1、参数量降低,计算量减少。
2、网络变深,网络非线性表达能力更强
问题:
1、增加深度带来的首个问题就是梯度爆炸/消散的问题,这是由于随着层数的增多,在网络中反向传播的梯度会随着连乘变得不稳定,变得特别大或者特别小。这其中经常出现的是梯度消散的问题。
2、为了克服梯度消散也想出了许多的解决办法,如使用BatchNorm,将激活函数换为ReLu,使用Xaiver初始化等,可以说梯度消散已经得到了很好的解决
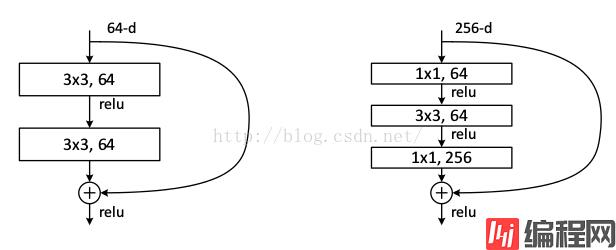
已知有网络degradation的情况下,不求加深度能提高准确性,能不能至少让深度网络实现和浅层网络一样的性能,即让深度网络后面的层至少实现恒等映射的作用,根据这个想法,作者提出了residual模块来帮助网络实现恒等映射。
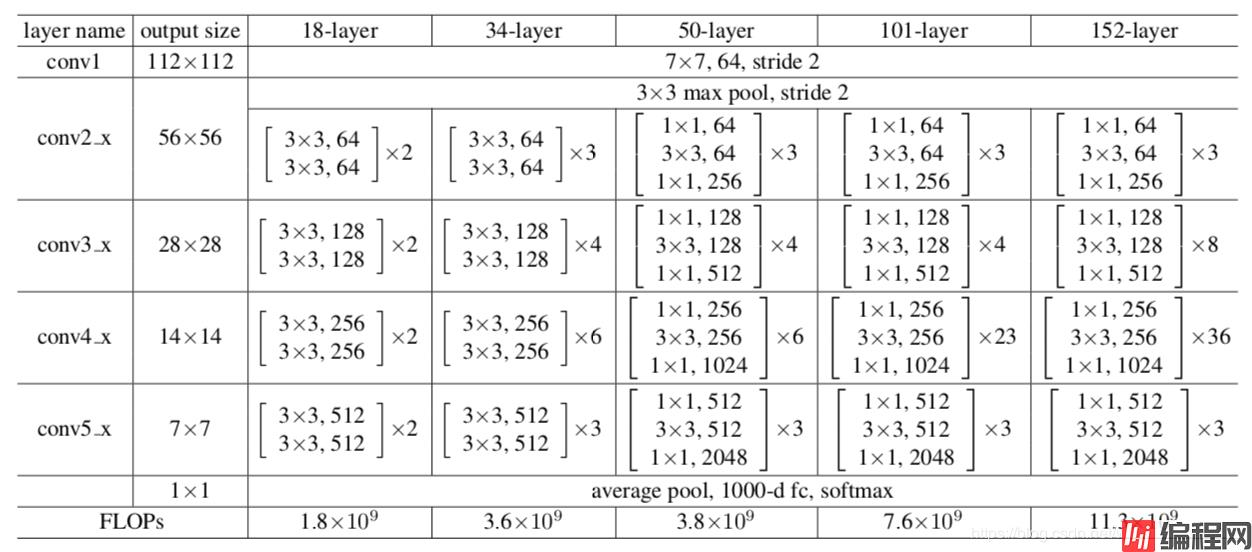
ResNet的设计特点:
1、核心单元模块化,可进行简单堆叠。
2、Shortcut方式解决网络梯度消失问题。
3、Average Pooling层代替fc层。
4、引入BN层加快网络训练速度和收敛时的稳定性。
5、加大网络深度,提高模型的特征抽取能力。
谷歌在2017年提出专注于移动端或者嵌入式设备中的轻量级CNN网络:MobileNet。最大的创新点是深度可分离卷积。
通过将标准卷积分解为深度卷积核逐点卷积,能够显著的降低参数量和计算量。引入Relu6激活函数。

参数量计算量的计算

网络结构如下:
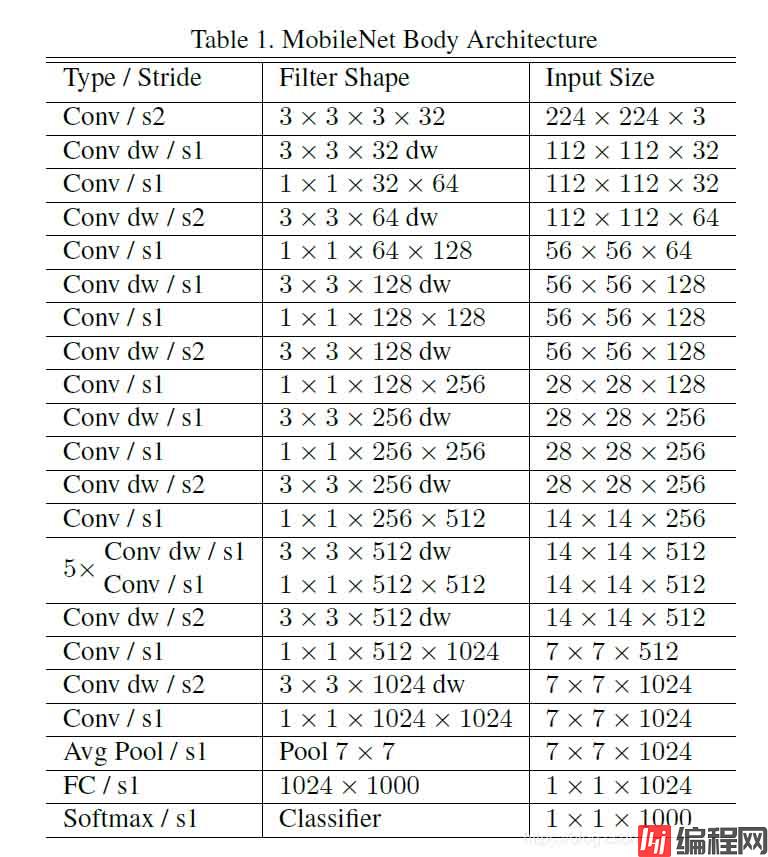
改进点主要有以下几个方面:
1、引入残差结构,先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用
Inverted Residuals:
残差模块:输入首先经过1x1的卷积进行压缩,然后使用3x3的卷积进行特征提取,最后在用1x1的卷积把通道数变换回去。整个过程是“压缩-卷积-扩张”。这样做的目的是减少3x3模块的计算量,提高残差模块的计算效率。

倒残差模块:输入首先经过1x1的卷积进行通道扩张,然后使用3x3的depthwise卷积,最后使用1x1的pointwise卷积将通道数压缩回去。整个过程是“扩张-卷积-压缩”。
对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。
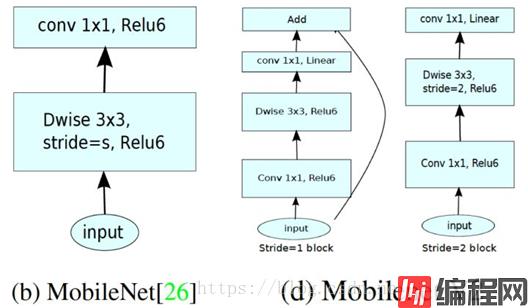
Linear Bottleneck
这个模块是为了解决一开始提出的那个低维-高维-低维的问题,即将最后一层的ReLU6替换成线性激活函数,而其他层的激活函数依然是ReLU6。
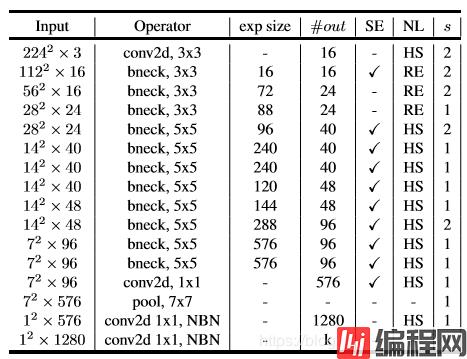
V3结合了V1的深度可分离卷积,V2的Inverted Residuals 和 Linear Bottleneck,以及加入SE模块、利用NAS(神经结构的搜索)来搜索网络参数。

互补搜索技术 —— NAS & NetAdapt
h-swish激活函数
out = F.relu6(x + 3., self.inplace) / 6.
return out * x
改进一:下图是MobileNet-v2的整理模型架构,可以看到,网络的最后部分首先通过1x1卷积映射到高维,然后通过GAP收集特征,最后使用1x1卷积划分到K类。所以其中起抽取特征作用的是在7x7分辨率上做1x1卷积的那一层。
而V3是先进行池化然后再进行1x1卷积提取特征,V2是先1X1卷积提取特征再池化。
组卷积
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection),而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
depthwise convolution,这是一种比较特殊的group convolution,此时分组数恰好等于通道数,意味着每个组只有一个特征图。分组卷积的会带来一个矛盾就是特征通信。group convolution层另一个问题是不同组之间的特征图需要通信。所以MobileNet等网络采用密集的1x1 pointwise convolution,因为要保证group convolution之后不同组的特征图之间的信息交流。
为达到特征通信目的,我们不采用dense pointwise convolution,考虑其他的思路:channel shuffle
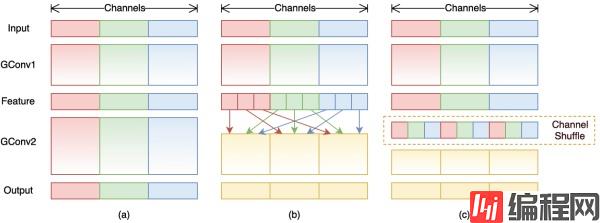
ShuffleNet的核心是采用了两种操作:pointwise group convolution和channel shuffle,这在保持精度的同时大大降低了模型的计算量。
其基本单元则是在一个残差单元的基础上改进而成。

以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: 卷积神经网络的发展及各模型的优缺点及说明
本文链接: https://www.lsjlt.com/news/193834.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0