目录Mysql join查询优化1. 那什么是驱动表呢?2. 复杂的sql怎么识别驱动表呢?3. 关联查询原理是怎样的?4. 该如如何优化?5. 实例mysql优化(关联查询优化)准
在日常的开发中,我们经常遇到这样情况:select * from TableA inner join TableB...它响应速度一直很快的,随着数据的增长,突然有一天开始很慢了。那该怎么破?
对,驱动表是突破口,
如果你搞不清楚该让谁做驱动表、谁 join 谁,就别指定谁 left/right join 谁了,请交给 MySQL优化器 运行时决定吧。
按经验谈,使用EXPLaiN, 第一行出现的表就是驱动表。
MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
//例: user表10000条数据,class表20条数据
select * from user u left join class c u.userid=c.userid上面sql的后果就是需要用user表循环10000次才能查询出来,而如果用class表驱动user表则只需要循环20次就能查询出来。
优化的目标是尽可能减少JOIN中Nested Loop的循环次数,以此保证:永远用小结果集驱动大结果集。
排序的字段也有影响,有条原则:对驱动表可以直接排序,对非驱动表(的字段排序)需要对循环查询的合并结果(临时表)进行排序!
explain select * from user u left join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id
WHERE 1=1 ORDER BY u.create_time DESC limit 0,10够复杂吧。假如,user表有千万级记录,class表要少得多,从执行计划的得知驱动表(数据到千万级)。由于动用了“LEFT JOIN”,所以相当于已经指定了驱动表。
如何优化?
//优化第一步:LEFT JOIN改为JOIN,对,直接 join!
explain select * from user u join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id
WHERE 1=1 ORDER BY u.create_time DESC limit 0,10
//优化第二步:从上面执行计划得知, 有Using temporary(临时表);Using filesort,解决方法是调整排序字段(借助前面讲过排序的原则)
explain select * from user u join class c on u.userid=c.userid INNER JOIN subject s on c.subjectId=s.id
WHERE 1=1 ORDER BY c.id DESC limit 0,10总之,sql优化中explain工具是非常重要的武器。
#分类
CREATE TABLE IF NOT EXISTS `class` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));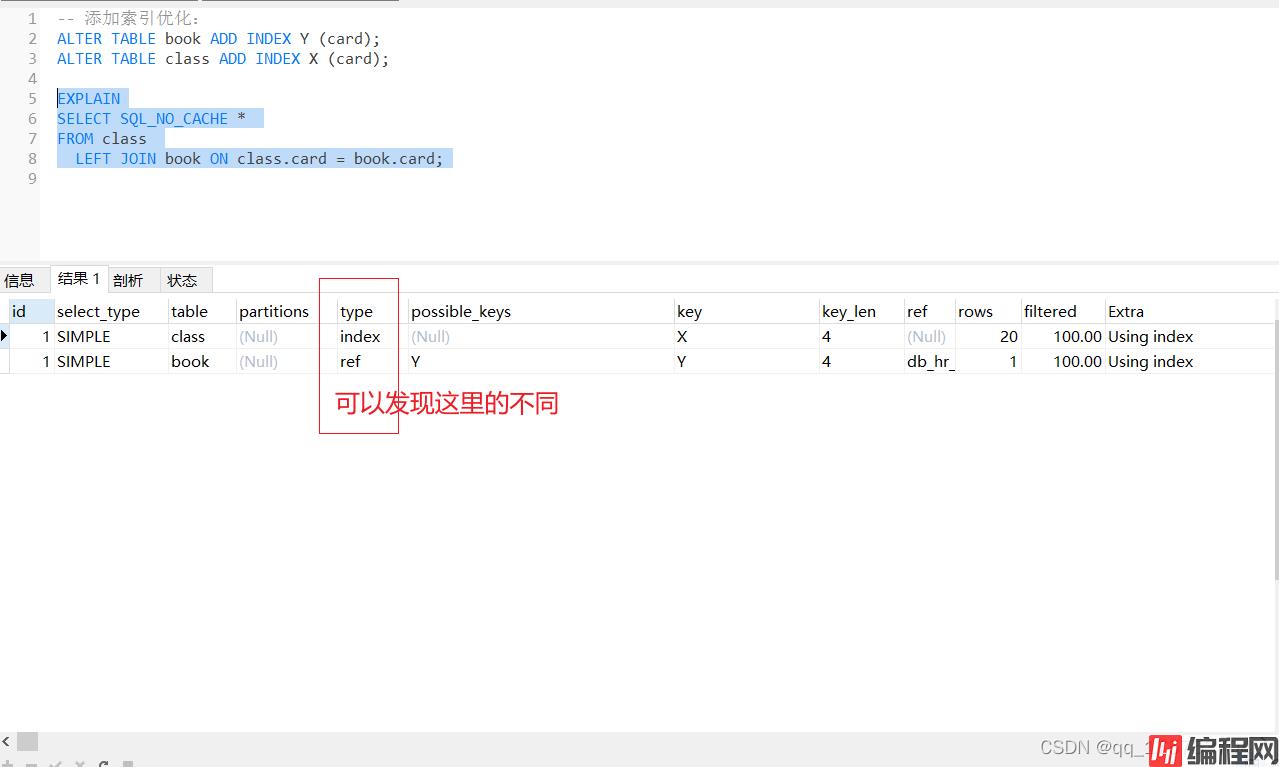
看这个分析结果发现:在 class 表上添加的索引起的作用不大。
结论:
- **小表驱动大表**
- 驱动方式识别
- 加索引的方式:通常建议在大表(被驱动)的表加索引,效率提升更明显。
- 原因:

小结:
- 保证被驱动表的 join 字段被索引。join 字段就是作为连接条件的字段。
- left join 时,选择小表作为驱动表(放左边),大表作为被驱动表(放右边)
- inner join 时,mysql 会自动将小结果集的表选为驱动表。
- 子查询尽量不要放在被驱动表,衍生表建不了索引
- 能够直接多表关联的尽量直接关联,不用子查询
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程网。
--结束END--
本文标题: MySQL之join查询优化方式
本文链接: https://www.lsjlt.com/news/199459.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0