目录lsm简析提问开始lsm 小结看看与b+tree的区别lsm简析 lsm 更像是一种设计索引的思想。它把数据分为两个部分,一部分放在内存里,一部分是存放在磁盘上,内存里面的数据检索方式可以利用红黑树,跳表这种时间复
lsm 更像是一种设计索引的思想。它把数据分为两个部分,一部分放在内存里,一部分是存放在磁盘上,内存里面的数据检索方式可以利用红黑树,跳表这种时间复杂度低的数据结构进行检索。
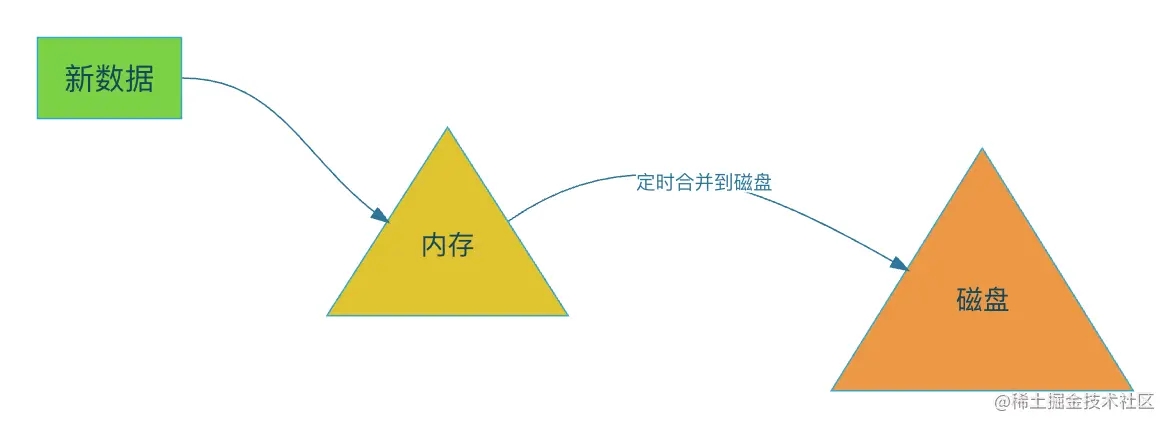
而当内存数据到达一定阀值的时候则会将数据同步到一个新的磁盘文件上。此时写入磁盘的方式是顺序写,这也是为什么lsm写入性能高的原因。
打住,你说写入性能高,但是我们知道内存中的数据如果在处于正在同步到磁盘的过程中,如果此时有新数据的插入,则会带来并发读写问题,要想解决就要给这片内存区域加锁了。加锁会导致写入过程阻塞,这样性能会高吗?
业界一般是这样解决的,当内存到达某个阀值后,就将这片内存标记为可读,然后新的数据插入将会写到新的内存区域,而旧的内存因为是只读的原因,便可以不加锁的进行同步到磁盘的过程。
再来思考,由于每次同步是生成一个新的磁盘文件,那么lsm是如何再多个磁盘文件范围里进行数据检索的呢? 由于内存容量有限,每次生成的磁盘文件必然不会过大,这样会不会产生大量的小容量的磁盘文件?
我来回答下, 查找数据的时候是从多个磁盘文件中读取数据,然后对结果进行合并,只取最新的数据。
这里已经可以看到和b+tree比较明显的区别了,b+tree是插入的时候进行原地合并,而lsm则是读取时进行数据合并。
由于数据在内存中是有序的,所以在写入磁盘时,也保证了每个小的磁盘文件是有序的。我们将这些小的磁盘文件称作sstable。
但是这样的设计还有没有问题,如果仅仅保证sstable文件有序,不同sstable文件索引的范围有重叠的话,我们查找一个值的时候就可能会在多个sstable文件里寻找,最差的情况可能要找所有的sstable文件,如图:
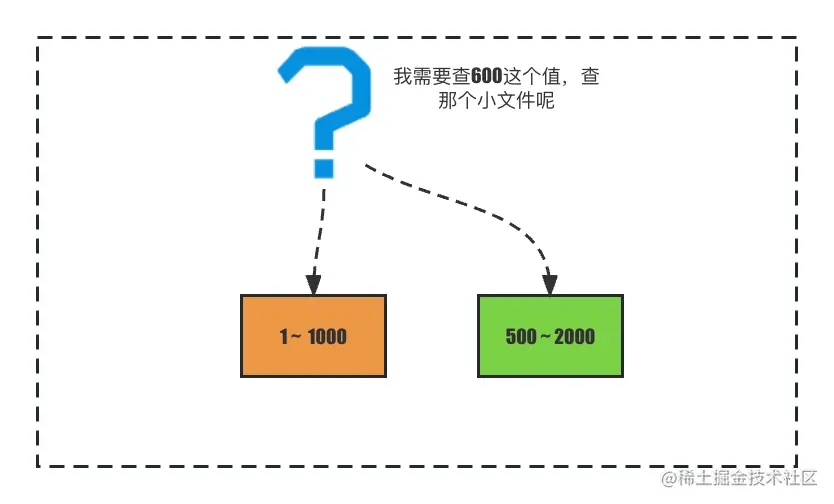
有个索引范围是1-1000的sstable,和值范围为500-2000的sstable,当我们查找600时,无法一开始就知晓600在哪个sstable里。
因此,业界一般是这样做,对多个小文件进行合并,让磁盘文件之间不再有覆盖关系。
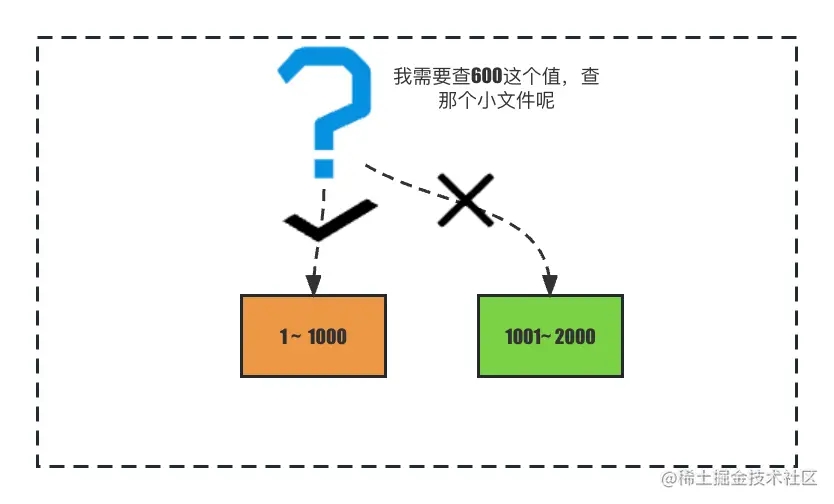
将索引范围合并后,两个sstable之间将不再重叠,便能快速检索到 查询的值所在的sstable了。
还没完,刚才提到了合并sstable文件,合并既能让sstable文件之间不会产生索引范围覆盖,又能减少大量小体积的sstable,但是在什么时候进行合并呢?
如果在新增sstable时进行合并,新增一个sstable,发现现有的sstable和和新增的sstable索引的范围都有重合关系,是不是要将新增的sstable全部与现有的sstable进行多路归并排序,然后再生成新的一个或多个sstable。
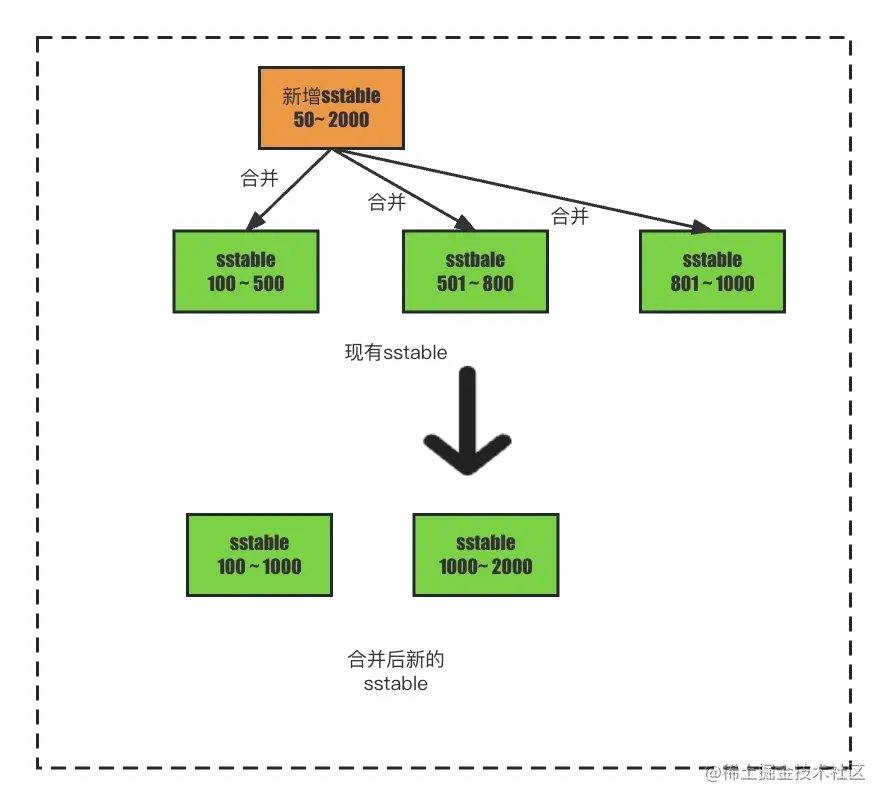
这样的效率真的会高吗? 新增的索引体积是比较小的,如果新增一个比较小的数量级的sstable文件就去合并所有的sstable文件显然是不合理的,并且由于新增的sstable体积小,产生较为频繁,如果每次都全量合并将会导致磁盘io在较长时间都处于一个比较高的值。
所以,最后业界的实现一般采用下面的多层次合并的方式。每一层的容量是上一层容量的10倍。

level0层 是标记为可读的那片内存直接顺序写入磁盘形成的sstable 文件的集合,只有4个文件,注意由于level0是内存直接写入生成的,所以level0层索引范围是有重合的,而其他层的索引范围将不会有重合产生。
当再有新的的sstable文件生成时,那么新的sstable就会和当前层有重合的sstable合并到下一层。
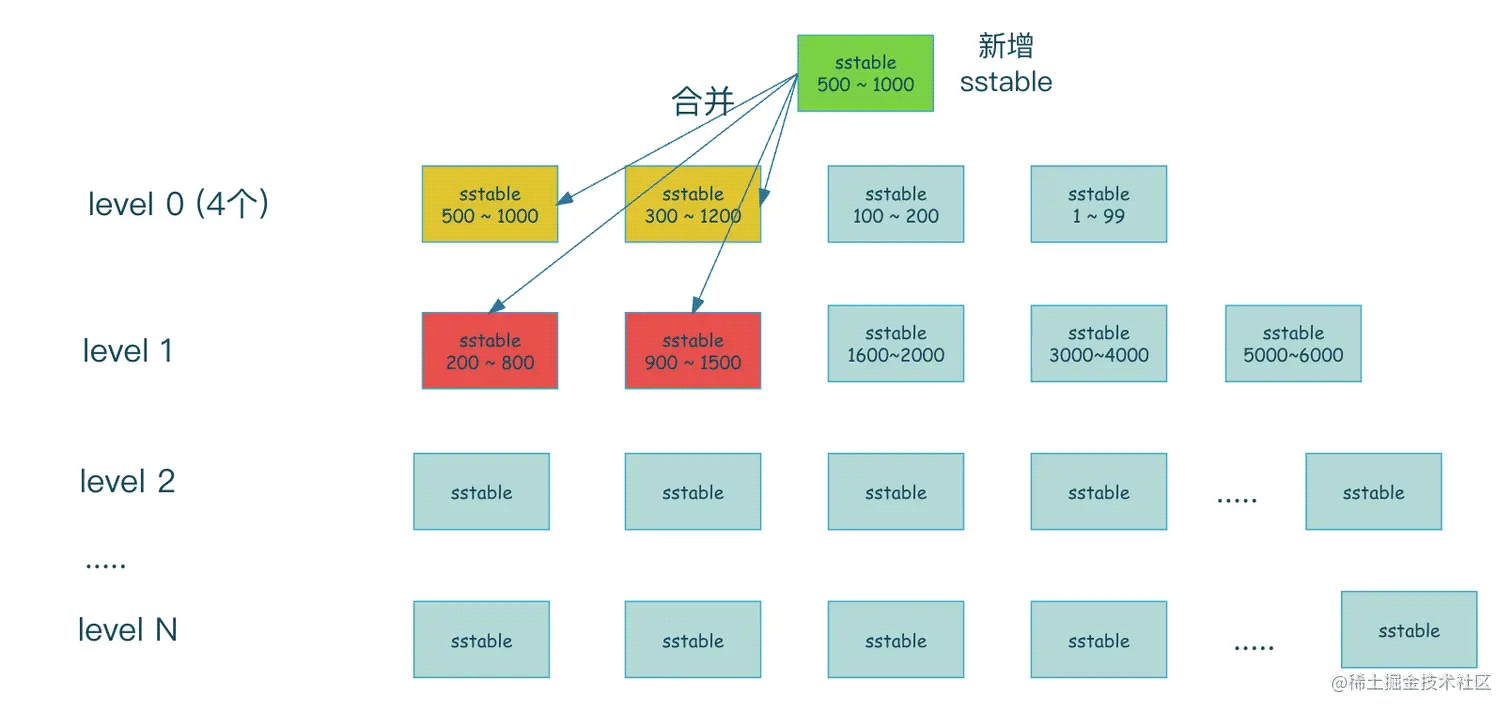
当新增一个sstable时,sstable的范围是500 ~ 1000 ,那么这个范围中level0层有500 ~ 1000的sstable和300 ~ 1200的sstable都和新增的sstable有重合,所以需要将这3个sstable一起合并到下一层,而合并到下一层时,发现上一层需要合并的索引范围是500 ~ 1200,所以找出level1层中与此索引范围有重合的sstable,即level1 中标记为红色的sstable,然后再与它们进行合并产生新的sstable。
这样多层滚动合并的设计能很好的解决每次新的sstable产生可能引发的高磁盘io的情况,因为它将之前的一次性合并按层次分摊到了多次,将整个合并过程分摊到了不同的时间段,缓解了写放大问题。
从lsm的实现上来看,已经能够明白它的一个数据写入和检索过程。这里再来总结一下。 lsm 写入时,会先写入到内存,内存里数据的检索一般是比较高效的数据结构,类似跳表,红黑树等,内存中的数据是有序。 内存到达某个阀值后,会将这片内存标记为只读,后续新的写入将在新的内存区域上进行,而只读的内存会将有序的数据写入到磁盘level0层,形成sstable文件。当level0层的sstable文件超过4个后,将会与level1层sstable产生合并行为,level0层以后的层级的索引范围都是没有重合的。
lsm读取数据时,同样先从内存中读取,如果读取不到则会从磁盘由低层到高层进行读取,读取到则返回,读取不到则直至最后一层为止。由于level0层以后的 每层 sstable数据都是有序且不重合的,在快速检索到数据所在的sstable 后,便能快速通过二分查找判断数据是否在该层中,真实实现,在sstable还用上了布隆过滤,来快速判断元素不在sstable的情况。如果该层找不到,则继续往下一层寻找。
可以看到,在读取数据时,最差的情况要遍历所有的层次,这也是为什么说lsm适合写多读少的场景,在读时也最好读取最近的数据。
b+tree的索引更新是原地更新,原地更新带来的代价很明显,第一个是要加锁,第二个由于更新时各个节点之前的在磁盘位置并不相邻带来的随机写入问题。 但b+tree的随机读性能很好,上千万的数据最多也只需要两三次磁盘io。
而lsm在高效写的优势下 带来了读放大问题,最坏的情况可能要在lsm多层磁盘索引结构中,每个层次都找一遍。在写频繁的场景下,查询也基本上是查最近数据时,lsm具有很好的性能。
问了一通之后,算是理清楚了lsm的原理了,平时我也倾向于向自己发问来不断剖析问题,结尾我再问一个问题吧,这篇文章里,我一共问了几个问题呢?
以上就是问哭自己lsm 索引原理及剖析的详细内容,更多关于lsm 索引原理的资料请关注我们其它相关文章!
--结束END--
本文标题: 问哭自己lsm 索引原理深入剖析
本文链接: https://www.lsjlt.com/news/201316.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-11
2024-05-11
2024-05-11
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0