目录一、前言1.1 常规调优手段1.1.1 加索引1.1.2 代码层优化1.1.3 减少关联表查询1.1.4 分库分表1.1.5 引入第三方存储二、一个棘手的问题2.1 前置准备2
对于一个业务量稳步上升的微服务系统来说,数据规模在可预期的时间段内也是逐渐增长的。使用过Mysql的同学应该知道,mysql单表的数据量是有性能瓶颈的,对于硬件配置一般的服务器来说,单表百万级数据量单表查询问题不大,但是在大规模频繁调用的微服务系统中,一旦该表涉及关联查询的表比较多时,将出现明显的性能问题,此时不管是开发人员,还是DBA,此时就要考虑数据库或表的性能调优了。
遇到上面的性能问题之后不要慌,一般有下面几种常规的手段可以来应对:
分析你的业务代码中最影响性能的查询sql,给字段添加必要而合适的索引。
比如:循环查询改为批量查询,条件允许的情况下使用缓存,使用异步等
将非必要关联的表抽离到业务层代码中,以查询结果集带入到下一步的查询逻辑,多表关联很容易引发查询性能问题
减少单表的数据量,从而提升查询性能,或者将宽表拆解成窄表
mysql + es进行双写,将一些业务简单但查询性能较差的逻辑放在es去做
总结
以上方案各有优劣,需要视情况而定,各种方案在实际的开发中都可以落地,开发和维护成本都不一样,需要综合评估,当然还有其他的方案,比如做数据冷热分离,读写分离等,需视情况来定。
CREATE TABLE `t_content` (
`id` varchar(32) NOT NULL,
`title` varchar(255) DEFAULT NULL,
`price` varchar(32) DEFAULT NULL,
`descs` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;随机造一些数据
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('001', '测试用于', '10', '测试用于');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('1', 'Java面向对象', '10', 'Java面向对象从入门到精通,简单上手');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('10', 'Java开发实战经典', '51', '本书是一本综合讲解Java核心技术的书籍,在书中使用大量的代码及案例进行知识点的分析与运用');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('11', 'Effective Java', '10', '本书介绍了在Java编程中57条极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('12', '分布式 Java 应用:基础与实践', '15', '本书介绍了编写分布式Java应用涉及的众多知识点,分为了基于Java实现网络通信、rpc;基于SOA实现大型分布式Java应用');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('13', 'Http权威指南', '11', '超文本传输协议(Hypertext Transfer Protocol,HTTP)是在万维网上进行通信时所使用的协议方案');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('14', 'spring', '15', '这是啥,还需要学习吗?Java程序员必备书籍');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('15', '深入理解 Java 虚拟机', '18', '作为一位Java程序员,你是否也曾经想深入理解Java虚拟机,但是却被它的复杂和深奥拒之门外');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('16', 'SpringBoot实战', '11', '完成对于springboot的理解,是每个Java程序员必备的姿势');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('17', 'springMVC学习', '72', 'springmvc学习指南');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('18', 'Vue入门到放弃', '20', 'vue入门到放弃书籍信息');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('19', 'vue入门到精通', '20', 'vue入门到精通相关书籍信息');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('2', 'Java面向对象java', '10', 'Java面向对象从入门到精通,简单上手');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('20', 'vue之旅', '20', '由浅入深地全面介绍vue技术,包含大量案例与代码');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('21', 'vue实战', '20', '以实战为导向,系统讲解如何使用 ');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('22', 'vue入门与实践', '20', '现已得到苹果、微软、谷歌等主流厂商全面支持');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('23', 'vue.js应用测试', '20', 'Vue.js创始人尤雨溪鼎力推荐!Vue官方测试工具作者亲笔撰写,Vue.js应用测试完全学习指南');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('24', 'PHP和MySQL web开发', '20', '本书是利用php和MySQL构建数据库驱动的WEB应用程序的权威指南');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('25', 'Web高效编程与优化实践', '20', '从思想提升和内容修炼两个维度,围绕前端工程师必备的前端技术和编程基础');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('26', 'Vue.js 2.x实践指南', '20', '本书旨在让初学者能够快速上手vue技术栈,并能够利用所学知识独立动手进行项目开发');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('27', '初始vue', '20', '解开vue的面纱');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('28', '什么是vue', '20', '一步一步的了解vue相关信息');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('29', '深入浅出vue', '20', '深入浅出vue,慢慢掌握');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('3', 'Java面向编程', '15', 'Java面向对象编程书籍');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('30', '三天vue实战', '20', '三天掌握vue开发');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('31', '不知火舞', '20', '不知名的vue');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('32', '娜可露露', '20', '一招秒人');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('33', '宫本武藏', '20', '我就是一个超级兵');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('34', 'vue宫本vue', '20', '我就是一个超级兵');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('4', 'javascript入门', '18', 'JavaScript入门编程书籍');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('5', '深入理解Java编程', '13', '十三四天掌握Java基础');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('6', '从入门到放弃_Java', '20', '一门从入门到放弃的书籍');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('7', 'Head First Java', '30', '《Head First Java》是一本完整地面向对象(object-oriented,OO)程序设计和Java的学习指导用书');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('8', 'Java 核心技术:卷1 基础知识', '22', '全书共14章,包括Java基本的程序结构、对象与类、继承、接口与内部类、图形程序设计、事件处理、Swing用户界面组件');
INSERT INTO `bank1`.`t_content`(`id`, `title`, `price`, `descs`) VALUES ('9', 'Java 编程思想', '12', '本书赢得了全球程序员的广泛赞誉,即使是最晦涩的概念,在Bruce Eckel的文字亲和力和小而直接的编程示例面前也会化解于无形');
来看下面这个sql
select * from t_content tc
where
tc.title like concat('%','深入', '%') or tc.descs like concat('%','深入', '%')这是一个简单的关键字查询,传入关键字,只要记录的title字段或者descs字段包含了关键字都可以查出来;

对mysql索引略有了解的同学通过explain关键字可以知道,即便你的查询字段本身有索引,使用like查询时要走索引也是有条件的,我们不妨给这两个字段加上索引
create index idx_title on t_content(title);
create index idx_descs on t_content(descs);
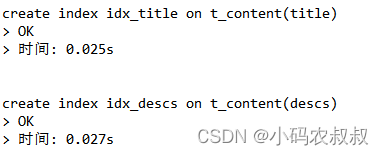
加完索引后,使用explain分析执行计划,是否走索引一目了然;

也就是说,like虽然好用,但是在数据集非常大的情况下,要是不走索引的情况下,那个查询性能是可想而知的。
通过上面的like查询分析,以及最终的效果预测来看,如果在单表数据量非常大的情况下,性能是非常糟糕的,就算是使用前缀匹配勉强走索引,并不能很好的满足需求,那么有人会问,那就可以考虑使用本文开头的那些方案,比如分表,或者引入es都是不错的选择。
事实上,在真实的生产环境中,每一种方案的落地,都需要多方面综合因素的评估考虑,比如:
1)开发投入的时间成本和人力成本;
2)技术的复杂度;
3)与现有技术架构的兼容性;
4)数据的兼容性;
5)数据适配与迁移成本;
6)后续的项目维护成本...
在小编真实的业务场景下,结合现实情况,在尽可能不引入新的存储中间件,以及尽可能减少人力投入成本与数据迁移成本的情况下,这里提出一种使用mysql结合lucene实现全文检索的优化方案,接下来将详细介绍下该方案的实现。
说到全文检索,相信没人不知道es的,就算没有用过,对es查询的高性能也有耳闻,这得力于es底层强大的分词与索引技术,es是一个基于Lucene的实时的分布式搜索和分析引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便,提供了丰富的API,开箱即用。
Lucene是一套用于全文检索和搜寻的开源程式库,由 Apache 软件基金会支持和提供。Lucene 提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。——《百度百科》
何为全文检索?举例来说,假如要在一个文件中查找某个字符串,最直接的办法就是从头开始检索,查到了就OK。这种方式对小数据量文件来说,简单实用。但对于大数据量文件来说,就比较吃力了。
文件中的数据是属于非结构化数据,也就是说它没有什么结构可言(不像我们数据库中的信息,可以一行一行的去匹配查询),要解决上面提到的效率问题,首先我们得将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构(说白了,就是变成关系数据库型一行一行的数据),然后对这些有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这就叫全文搜索。即先建立索引(表结构,把文件中的关键词提取出来),再对索引进行搜索的过程。
那么 Lucene 中是如何建立索引的呢?比如有如下两篇文章,内容如下:
文章1内容:Tom lives in Guangzhou, I live in Guangzhou too.
文章2内容:He once lived in Shanghai.
第一步是将文档传给分词组件(Tokenizer),分词组件会将文档分成一个个单词,并去除标点符号和停词。所谓的停词指的是没有特别意义的词,比如英文中的 a,the,too 等。经过分词后,得到词元(Token) 。如下:
文章1经过分词后的结果:[Tom] [lives] [Guangzhou] [I] [live] [Guangzhou]
文章2经过分词后的结果:[He] [lives] [Shanghai]
然后将词元传给语言处理组件(Linguistic Processor),对于英语,语言处理组件一般会将字母变为小写,将单词缩减为词根形式,如 ”lives” 到 ”live” 等,将单词转变为词根形式,如 ”drove” 到 ”drive” 等。然后得到词(Term)。如下:
文章1经过处理后的结果:[tom] [live] [guangzhou] [i] [live] [guangzhou]
文章2经过处理后的结果:[he] [live] [shanghai]
最后将得到的词传给索引组件(Indexer),索引组件经过处理,得到下面的索引结构,其实这个也是倒排索引建立的详细过程;
| 关键词 | 文章号[出现频率] | 出现位置 |
|---|---|---|
| guangzhou | 1[2] | 3,6 |
| he | 2[1] | 1 |
| i | 1[1] | 4 |
| live | 1[2],2[1] | 2,5,2 |
| shanghai | 2[1] | 3 |
| tom | 1[1] | 1 |
以上就是Lucene 索引结构中最核心的部分。它的关键字是按字符顺序排列的,因此 Lucene 可以用二元搜索算法快速定位关键词。实现时 Lucene 将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)和位置文件(positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。搜索的过程是先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果,然后就可以在具体的文章中根据出现位置找到该词了。所以Lucene在第一次建立索引的时候可能会比较慢,但是以后就不需要每次都建立索引了,就快了。
知道了Lucene的分词及创建索引的原理,下面就来实现一个具体的业务员需求,需求内容如下:
基于mysql数据库中一张现有的数据表,通过引入lucence,实现如下功能:
1)使用lucence替代mysql实现关键字数据查询;
2)添加新用户后,再次检索,能够从lucence检索数据;
在正式开始编码之前,先来对需求进行分解以及实现做一个规划
就以本文开开篇的t_content表为例,假如线上系统的数据表已经在投产运行中了;

从需求描述看,关键字查询走lucence,必须满足下面几个条件
以查询为例,参考下图的实现流程
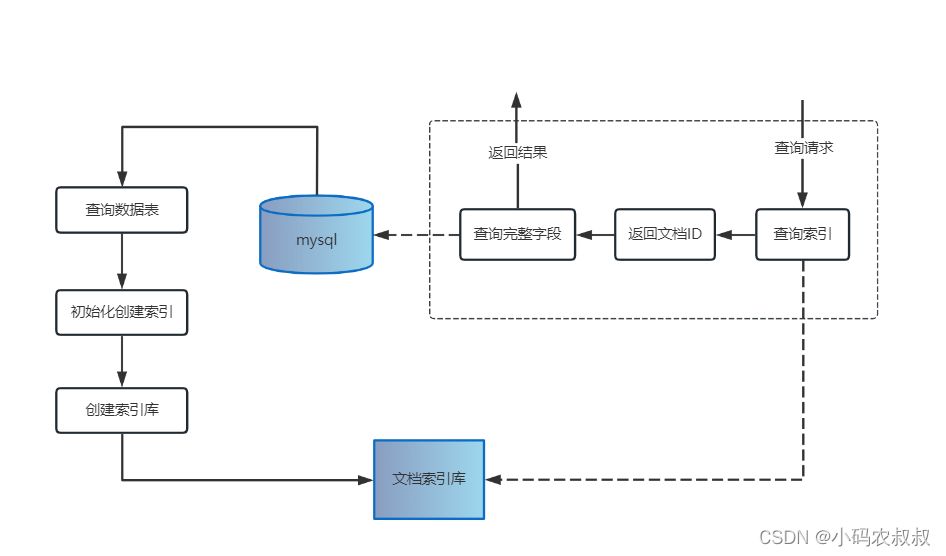
工欲善其事必先利其器,为了更好的编码,有必要对Lucene中涉及到常用的API做一下介绍。
与索引创建相关的核心API对象或属性主要有下面这些
Document
Document 是用来描述文档的,这里的文档可以指一个 html 页面,一封电子邮件,或者是一个文本文件。一个 Document 对象由多个 Field 对象组成,可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。
Field
Field 对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个 Field 对象分别描述。
Analyzer
在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由 Analyzer 来做的。Analyzer 类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引。
IndexWriter
IndexWriter 是 Lucene 用来创建索引的一个核心的类,他的作用是把一个个的 Document 对象加到索引中来。
Directory
这个类代表了 Lucene 的索引的存储的位置,这是一个抽象类,它目前有两个实现,第一个是 FSDirectory,它表示一个存储在文件系统中的索引的位置。第二个是 RAMDirectory,它表示一个存储在内存当中的索引的位置。
使用过es的同学对下面的这些API对象应该不陌生,用起来的时候语法操作上确实很像。
Query
这是一个抽象类,他有多个实现,比如 TerMQuery, BooleanQuery, PrefixQuery. 这个类的目的是把用户输入的查询字符串封装成 Lucene 能够识别的 Query。
Term
Term 是搜索的基本单位,一个 Term 对象有两个 String 类型的域组成。生成一个 Term 对象可以有如下一条语句来完成:Term term = new Term(“fieldName”,”queryWord”); 其中第一个参数代表了要在文档的哪一个 Field 上进行查找,第二个参数代表了要查询的关键词。
TermQuery
TermQuery 是抽象类 Query 的一个子类,它同时也是 Lucene 支持的最为基本的一个查询类。生成一个 TermQuery 对象由如下语句完成: TermQuery termQuery = new TermQuery(new Term(“fieldName”,”queryWord”)); 它的构造函数只接受一个参数,那就是一个 Term 对象。
IndexSearcher
IndexSearcher 是用来在建立好的索引上进行搜索的。它只能以只读的方式打开一个索引,所以可以有多个 IndexSearcher 的实例在一个索引上进行操作。
Hits
Hits 是用来保存搜索的结果的。
接下来,将详细介绍基于springboot整合lucence,实现上面的需求,完整的工程目录如下
这里省略了其他非核心的依赖,可以根据自身需要导入
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- lucene核心库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.6.0</version>
</dependency>
<!-- Lucene的查询解析器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.6.0</version>
</dependency>
<!-- lucene的默认分词器库,适用于英文分词 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.6.0</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>7.6.0</version>
</dependency>
<!-- smartcn中文分词器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>7.6.0</version>
</dependency>
<!-- ik分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
</dependencies>
此处主要配置mysql的连接,逻辑中将涉及到数据表的DB操作
server:
port: 8083
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://IP:3306/bank1?autoReconnect=true&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false
username: root
password: root
mybatis:
type-aliases-package: com.congge.entity
mapper-locations: classpath:mybatis
@GetMapping("/initDbDataToIndex")
public String initDbDataToIndex() throws Exception{
//查询数据库数据
List<Content> dbList = contentService.queryAll();
// 创建文档的集合
Collection<Document> docs = new ArrayList<>();
for (int i = 0; i < dbList.size(); i++) {
Document document = new Document();
//StringField会创建索引,但是不会被分词,TextField,即创建索引又会被分词。
document.add(new StringField("id", (i + 1) + "", Field.Store.YES));
document.add(new StringField("title", dbList.get(i).getTitle(), Field.Store.YES));
document.add(new StringField("price", dbList.get(i).getPrice(), Field.Store.YES));
document.add(new TextField("descs", dbList.get(i).getDescs(), Field.Store.YES));
docs.add(document);
}
// 索引目录类,指定索引在硬盘中的位置
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir"));
Analyzer analyzer = new MyIKAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引
conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 把文档集合交给IndexWriter
indexWriter.aDDDocuments(docs);
indexWriter.commit();
indexWriter.close();
return "initDbDataToIndex success";
}
结合上文对API中的代码进行理解,执行完这个接口后,t_content表这个数据就被lucence创建索引了,在 D:\\Lucene\\indexDir 这个目录下;

索引目录文件如下
注意点:
实际业务中表的数据量可能非常大,为了尽可能避免索引文件过大对本地磁盘空间的压力,最好不要对所有字段进行索引,而是选择经常用于搜索的那些字段即可;
创建完数据的索引之后,就可以体验下检索的效果了,对单个字段进行关键字检索
@GetMapping("/query/keyword")
public Object searchKeyWord(@RequestParam("text") String text) throws Exception {
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(INDEX_PATH));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("descs", new MyIKAnalyzer(true));
Query query = parser.parse(text);
TopDocs topDocs = searcher.search(query, Integer.MAX_VALUE);
log.info("本次搜索共找到" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<Content> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
Content content = new Content();
content.setId(doc.get("id"));
content.setTitle(doc.get("title"));
content.setDescs(doc.get("descs"));
list.add(content);
}
return list;
}随便找一下关键词测试下效果


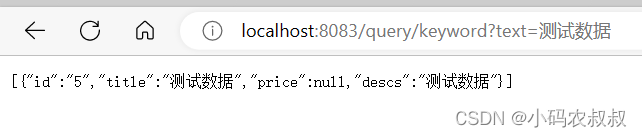
当数据库添加一条新的数据时,就需要给索引文件进行追加操作,否则后续搜索时将不能被搜出来;
@GetMapping("/updateIndex")
public String updateIndex(String desc) throws Exception {
Content content = new Content();
content.setId("1102");
content.setTitle(desc);
content.setPrice("10");
content.setDescs(desc);
contentService.save(content);
// 创建目录对象
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(new MyIKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 创建新的文档数据
Document doc = new Document();
doc.add(new StringField("id", "1102", Field.Store.YES));
doc.add(new StringField("title", content.getTitle(), Field.Store.YES));
doc.add(new StringField("price", content.getPrice(), Field.Store.YES));
doc.add(new TextField("descs", content.getDescs(), Field.Store.YES));
writer.updateDocument(new Term("id", "1102"), doc);
writer.commit();
writer.close();
return "updateIndex success";
}
执行上面的接口后,检查数据表将新增一条数据


此时再次执行上述的搜索接口,可以看到数据能够被成功检索了;

删除一条数据时,需要同步删除索引文件中的数据
@GetMapping("/deleteIndex")
public String deleteIndex(String id) throws Exception {
contentService.deleteById(id);
// 创建目录对象
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("D:\\Lucene\\indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(new IKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 根据词条进行删除
writer.deleteDocuments(new Term("id", id));
writer.commit();
writer.close();
return "deleteIndex success";
}执行删除接口
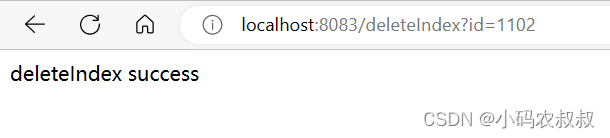
删除成功后再次执行上面的查询接口,此时就查不到数据了

在实际开发中,分页查询是很常见的,使用lucence也可以实现分页查询,看下面的代码
@GetMapping("/query/page")
public Object queryForPage(@RequestParam("text") String text,
@RequestParam(value = "page",defaultValue = "1") int page,
@RequestParam(value = "pageSize",defaultValue = "10") int pageSize) throws Exception {
Map<String, Object> resMap = new HashMap<>();
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(INDEX_PATH));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("descs", new MyIKAnalyzer(true));
Query query = parser.parse(text);
TopDocs topDocs = IndexUtils.searchByPage(page, pageSize, searcher, query);
log.info("本次搜索共找到" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<Content> list = new ArrayList<>();
List<String> idList = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
idList.add(doc.get("id"));;
}
if(!CollectionUtils.isEmpty(idList)){
list = contentService.queryContentByIdList(idList);
}
resMap.put("page", page);
resMap.put("pageSize", pageSize);
resMap.put("total", topDocs.totalHits);
resMap.put("list", list);
return resMap;
}
执行上面的接口查询,看到如下的效果

还记得在本文开头使用like关键字查询吗?在mysql的like查询中,如果希望从多个字段中匹配出某个关键字,使用like的or即可,使用lucence也可以满足,不过有个前提,那就是匹配的字段都需要提前分词,为了达到这个目的,首先删除本地已经创建的索引文件,然后在初始化索引文件接口中将title与descs两个字段都设置为分词;
上面的代码修改后再次执行重新生成索引文件
完整的查询代码
@GetMapping("/query/multi")
public Object multiFieldQuery(String text) throws Exception {
String[] str = {"title", "descs"};
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(INDEX_PATH));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer());
// 创建查询对象
Query query = parser.parse(text);
// 获取前十条记录
TopDocs topDocs = searcher.search(query, 100);
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<Content> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
Content content = new Content();
content.setId(doc.get("id"));
content.setTitle(doc.get("title"));
content.setDescs(doc.get("descs"));
list.add(content);
}
return list;
}
比如在数据表中有条数据的title中含有”什么“;
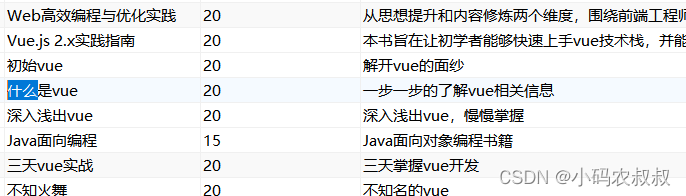
调用一下接口测试,可以看到数据就查到了;

在一些网站上,当我们搜索关键词时发现,我们搜索出来的内容里面包含了关键词的位置会以高亮进行展示,像es,lucence都支持结果的高亮现实,完整代码如下
@GetMapping("/query/high-light")
public Object queryHighLight(String text) throws Exception {
String[] str = {"title", "descs"};
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(INDEX_PATH));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
MultiFieldQueryParser parser = new MultiFieldQueryParser(str, new MyIKAnalyzer());
Query query = parser.parse(text);
TopDocs topDocs = searcher.search(query, Integer.MAX_VALUE);
//高亮显示设置
SimpleHTMLFORMatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
//高亮后的段落范围在100字内
Fragmenter fragmenter = new SimpleFragmenter(100);
highlighter.setTextFragmenter(fragmenter);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
List<Content> list = new ArrayList<>();
for (ScoreDoc scoreDoc : scoreDocs) {
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
Content content = new Content();
String title = highlighter.getBestFragment(new MyIKAnalyzer(), "title", doc.get("title"));
if (title == null) {
title = content.getTitle();
}
String descs = highlighter.getBestFragment(new MyIKAnalyzer(), "descs", doc.get("descs"));
if (descs == null) {
descs = content.getDescs();
}
content.setDescs(descs);
content.setTitle(title);
list.add(content);
}
return list;
}
执行接口查询,看到如下效果,如果将其中的html进行渲染的话就能清楚的看到效果了;

本文接口中涉及到的工具类如下
public class IndexUtils {
public static final String INDEX_PATH = "D:\\Lucene\\indexDir";
private static Directory dir;
public static TopDocs searchByPage(int page, int perPage, IndexSearcher searcher, Query query) throws IOException {
TopDocs result = null;
if (query == null) {
System.out.println(" Query is null return null ");
return null;
}
ScoreDoc before = null;
if (page != 1) {
TopDocs docsBefore = searcher.search(query, (page - 1) * perPage);
ScoreDoc[] scoreDocs = docsBefore.scoreDocs;
if (scoreDocs.length > 0) {
before = scoreDocs[scoreDocs.length - 1];
}
}
result = searcher.searchAfter(before, query, perPage);
return result;
}
public static IndexWriter getWriter() throws Exception {
//使用中文分词器
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
//将中文分词器配到写索引的配置中
IndexWriterConfig config = new IndexWriterConfig(analyzer);
//实例化写索引对象
IndexWriter writer = new IndexWriter(dir, config);
return writer;
}
}
通过上面的接口效果演示,初步可以满足提出的需求,但代码部分比较粗糙,还需细致打磨,提出如下几点可供继续完善
或许在你的项目中,不只一张表需要通过lucence这种方式,那么就涉及到索引目录的管理,是放到一个目录下管理还是分不同的目录管理,这个是需要考虑的。
在集群或多节点部署情况下,为了数据检索的准确性,索引文件一定需要集中在一个位置存储,否则将造成数据不一致问题。
如果lucence没有查到数据,你是否还要去mysql中再查一次呢?因为可能会出现lucence索引文件在极端情况下被破坏的情况,这是所有走数据双写方案需要考虑的问题。
如果你的索引文件越来越大,可能面临单机索引文件存储受限的情况,这将涉及到索引文件拆分或者迁移的问题,这个是有必要提前规划的。
本文以一个实际的需求案例出发,详细说明了如何基于Lucence实现对mysql数据表的全文检索,作为一种可落地的实施方案,对于解决类似的实际问题有一定的参考意义,希望对您有用。
到此这篇关于springboot微服务Lucence实现Mysql全文检索的文章就介绍到这了,更多相关Mysql全文检索内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
--结束END--
本文标题: springboot微服务Lucence实现Mysql全文检索功能
本文链接: https://www.lsjlt.com/news/201421.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-11
2024-05-11
2024-05-11
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作





0