Python 官方文档:入门教程 => 点击学习
目录一:归一化的概念二:归一化的作用三:归一化的类型1:线性归一化2:零-均值归一化(Z-score标准化)3:小数定标规范化4:非线性归一化 四:批归一化(BatchNO
数据归一化是深度学习数据预处理中非常关键的步骤,可以起到统一量纲,防止小数据被吞噬的作用。
归一化就是把所有数据都转化成[0,1]或者[-1,1]之间的数,其目的是为了取消各维数据之间的数量级差别,避免因为输入输出数据数量级差别大而造成网络预测误差过大。
线性归一化也被称为最小-最大规范化;离散标准化,是对原始数据的线性变换,将数据值映射到[0,1]之间。用公式表示为:
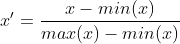
差标准化保留了原来数据中存在的关系,是消除量纲和数据取值范围影响的最简单的方法。代码实现如下:
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return x适用范围:比较适用在数值比较集中的情况
缺点:
Z-score标准化也被称为标准差标准化,经过处理的数据的均值为0,标准差为1。其转化公式为:
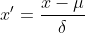
其中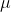 为原始数据的均值,
为原始数据的均值,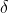 为原始数据的标准差,是当前用的最多的标准化公式
为原始数据的标准差,是当前用的最多的标准化公式
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布
代码实现如下:
def Z_ScoreNormalization(x,mu,sigma):
x = (x - mu) / sigma;
return x这种方法通过移动属性值的小数数位,将属性值映射到[-1,1]之间,移动的小数位数取决于属性值绝对值的最大值。转换公式为:
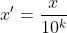
这个方法包括log,指数,正切
适用范围:经常用在数据分析比较大的场景,有些数值很大,有些很小,将原始值进行映射。
在以往的神经网络训练时,仅仅只对输入层数据进行归一化处理,却没有在中间层进行归一化处理。虽然我们对输入数据进行了归一化处理,但是输入数据经过了这样的矩阵乘法之后,其数据分布很可能发生很大改变,并且随着网络的层数不断加深。数据分布的变化将越来越大。因此这种在神经网络中间层进行的归一化处理,使得训练效果更好的方法就被称为批归一化(BN)
输入:上一层输出结果X={x1,x2,.....xm},学习参数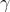 ,
,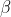
算法流程:
1)计算上一层输出数据的均值:

其中,m是此次训练样本batch的大小。
2)计算上一层输出数据的标准差:

3)归一化处理得到
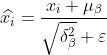
公式中的 是为了避免分母为0而加进去接近于0的很小的值。
是为了避免分母为0而加进去接近于0的很小的值。
4)重构,对经过上面归一化处理得到的数据进行重构,得到:
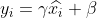
其中,为可学习的参数。
到此这篇关于浅谈一下几种常见的归一化方法的文章就介绍到这了,更多相关常见的归一化方法内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 浅谈Python几种常见的归一化方法
本文链接: https://www.lsjlt.com/news/204869.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0