目录什么是 CI、CD为什么要使用 CI、CDgitlab CI、CDgitlab CI、CD 中的一些基本概念CI、CD 的工作模型其他一些在个人实践中的一些经验指定特定分支才会执
gitlab 可能大家很常用,CI、CD 也应该早有耳闻,但是可能还没有去真正地了解过,这篇文章就是我对 gitlab CI、CD 的一些理解,以及踩过的一些坑,希望能帮助到大家。
CI(Continuous Integration)持续集成,CD(Continuous Deployment)持续部署(也包含了持续交付的意思)。
CI 指的是一种开发过程的的自动化流程,在我们提交代码的时候,一般会做以下操作:
lint 检查,检查代码是否符合规范这个过程我们可以称之为 CI,也就是持续集成,这个过程是自动化的,也就是说我们不需要手动去执行这些操作,只需要提交代码,这些操作就会自动执行。
CD 指的是在我们 CI 流程通过之后,将代码自动发布到服务器的过程,这个过程也是自动化的。 在有了前面 CI 的一些操作之后,说明我们的代码是可以安全发布到服务器的,所以就可以进行发布的操作。
实际上,就算没有 CI、CD 的这些花里胡哨的概念,对于一些重复的操作,我们也会尽量想办法会让它们可以自动化实现的,只不过可能效率上没有这么高,但是也是可以的。
CI、CD 相比其他方式的优势在于:
在开始之前,我们可以通过下图来了解一下 CI、CD 的整体流程:
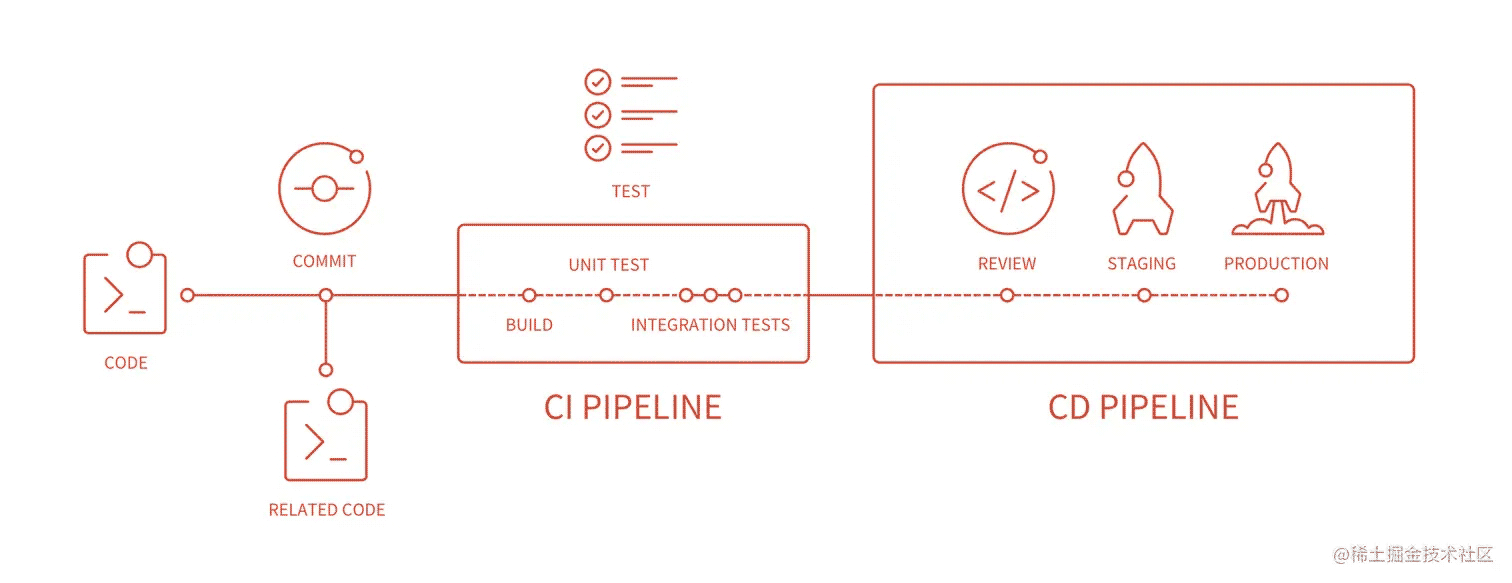
CI PIPELINE,也就是中间的部分。build、unit test、integration tests 等,也就是构建、单元测试、集成测试等。CD PIPELINE,也就是右边的部分。staging、production 等,也就是部署到测试环境、部署到生产环境等。在 CD 流程结束之后,我们就可以在服务器上看到我们的代码了。
在开始之前,我们先来了解一下 gitlab CI、CD 中的一些基本概念:
pipeline:流水线,也就是 CI、CD 的整个流程,包含了多个 stage,每个 stage 又包含了多个 job。stage: 一个阶段,一个阶段中可以包含多个任务(job),这些任务会并行执行,但是下一个 stage 的 job 只有在上一个 stage 的 job 执行通过之后才会执行。job:一个任务,这是 CI、CD 中最基本的概念,也是最小的执行单元。一个 stage 中可以包含多个 job,同时这些 job 会并行执行。runner:执行器,也就是执行 job 的机器,runner 跟 gitlab 是分离的,runner 需要我们自己去安装,然后注册到 gitlab 上(不需要跟 gitlab 在同一个服务器上,这样有个好处就是可以很方便实现多个机器来同时处理 gitlab 的 CI、CD 的任务)。tag: runner 和 job 都需要指定标签,job 可以指定一个或多个标签(必须指定,否则 job 不会被执行),这样 job 就只会在指定标签的 runner 上执行。cache: 缓存,可以缓存一些文件,这样下次流水线执行的时候就不需要重新下载了,可以提高执行效率。artifacts: 这代表这构建过程中所产生的一些文件,比如打包好的文件,这些文件可以在下一个 stage 中使用,也可以在 pipeline 执行结束之后下载下来。variables:变量,可以在 pipeline 中定义一些变量,这些变量可以在 pipeline 的所有 stage 和 job 中使用。services:服务,可以在 pipeline 中启动一些服务,比如 Mysql、Redis 等,这样我们就可以在 pipeline 中使用这些服务了(常常用在测试的时候模拟一个服务)。script: 脚本,可以在 job 中定义一些脚本,这些脚本会在 job 执行的时候执行。我们以下面的配置为例子,简单说明一下 pipeline、stage、job 的工作模型,以及 cache 和 artifacts 的作用:
ci 配置文件(也就是一个 pipeline 的所有任务):
# 定义一个 `pipeline` 的所有阶段,一个 `pipeline` 可以包含多个 `stage`,每个 `stage` 又包含多个 `job`。
# stage 的顺序是按照数组的顺序来执行的,也就是说 stage1 会先执行,然后才会执行 stage2。
stages:
- stage1 # stage 的名称
- stage2
# 定义一个 `job`,一个 `job` 就是一个任务,也是最小的执行单元。
job1:
stage: stage1 # 指定这个 `job` 所属的 `stage`,这个 `job` 只会在 `stage1` 执行。
script: # 指定这个 `job` 的脚本,这个脚本会在 `job` 执行的时候执行。
- echo "hello world" > "test.txt"
tags: # 指定这个 `job` 所属的 `runner` 的标签,这个 `job` 只会在标签为 `tag1` 的 `runner` 上执行。
- tag1
# cache 可以在当前 `pipeline` 后续的 `job` 中使用,也可以在后续的 `pipeline` 中使用。
cache: # 指定这个 `job` 的缓存,这个缓存会在 `job` 执行结束之后保存起来,下次执行的时候会先从缓存中读取,如果没有缓存,就会重新下载。
key: $CI_COMMIT_REF_SLUG # 缓存的 key
paths: # 缓存的路径
- node_modules/
artifacts: # 指定这个 `job` 的构建产物,这个构建产物会在 `job` 执行结束之后保存起来。可以在下一个 stage 中使用,也可以在 pipeline 执行结束之后下载下来。
paths:
- test.txt
job2:
stage: stage1
script:
- cat test.txt
tags:
- tag1
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
# 指定这个 `job` 的缓存策略,只会读取缓存,不会写入缓存。默认是既读取又写入,在 job 开始的时候读取,在 job 结束的时候写入。
# 但是实际上,只有在安装依赖的时候是需要写入缓存的,其他 job 都使用 pull 即可。
policy: pull
# job3 和 job4 都属于 stage2,所以 job3 和 job4 会并行执行。
# job3 和 job4 都指定了 tag2 标签,所以 job3 和 job4 只会在标签为 tag2 的 runner 上执行。
# 同时,在 job1 中,我们指定了 test.txt 作为构建产物,所以 job3 和 job4 都可以使用 test.txt 这个文件。
job3:
stage: stage2
script:
- cat test.txt
tags:
- tag1
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
policy: pull
job4:
stage: stage2
script:
- cat test.txt
tags:
- tag1
cache:
key: $CI_COMMIT_REF_SLUG
paths:
- node_modules/
policy: pull
上面的配置文件的 pipeline 执行过程可以用下面的图来表示:
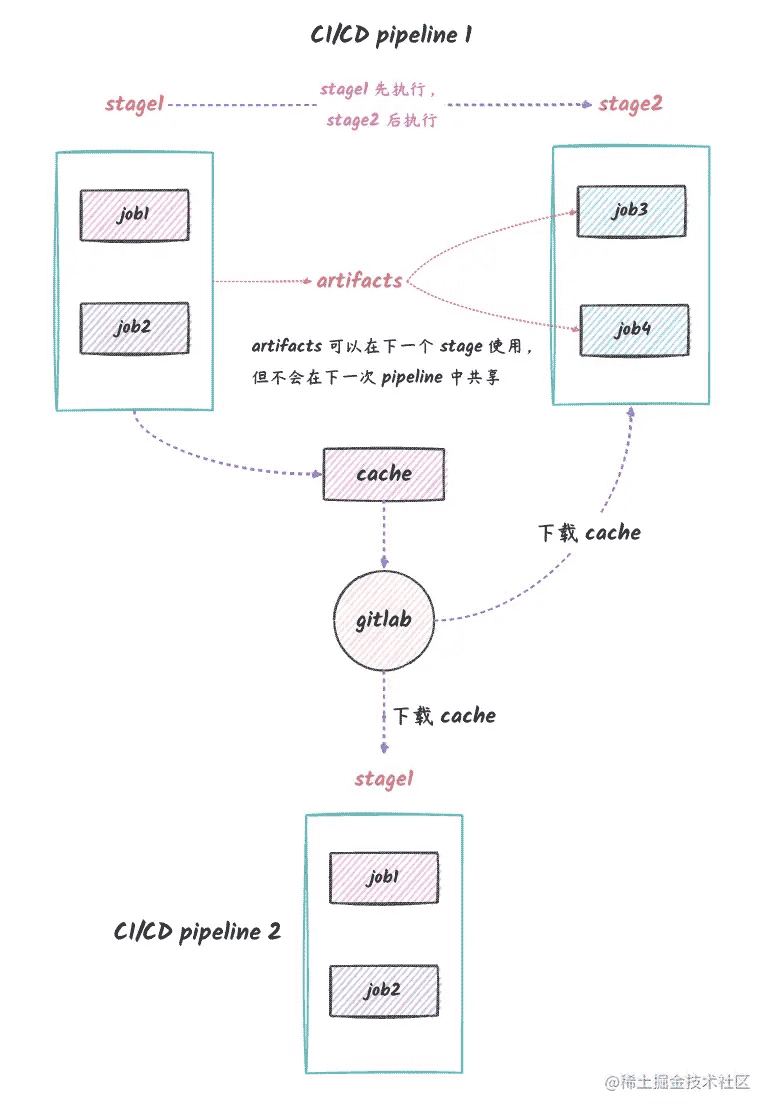
说明:
pipeline 被执行了,但是 pipeline2 没有全部画出来pipeline 1 中,stage1 中的 job 会先被执行,然后才会执行 stage2 中的 job。stage1 中的 job1 和 job2 是可以并行执行的,这也就是 stage 的本质上的含义,表示了一个阶段中不同的任务,比如我们做测试的时候,可以同时对不同模块做测试。job1 和 job2 都指定了 tag1 标签,所以 job1 和 job2 只会在标签为 tag1 的 runner 上执行。job1 中,我们创建了一个 test.txt 文件,这个文件会作为 stage1 的构建产物,它可以在 stage2 中被使用,也就是 job3 和 job4 都可以读取到这个文件。一种实际的场景是,前端部署的时候,build 之后会生成可以部署的静态文件,这些静态文件就会被保留到部署相关的 stage 中。需要注意的是,artifacts 只会在当前 pipeline 后续的 stage 中共享,不会在 pipeline 之间共享。job1 中,我们也指定了 cache,这个 cache 会在 job1 执行结束之后保存起来,不同于 artifacts,cache 是可以在不同的 pipeline 之间共享的。一种很常见的使用场景就是我们代码的依赖,比如 node_modules 文件夹,它可以加快后续 pipeline 的执行流程,因为避免了重复的依赖安装。需要特别注意的是:cache 是跨流水线共享的,而 artifacts 只会在当前流水线的后续 stage 共享。
gitlab 的 CI、CD 是一个很庞大的话题,同时很多内容可能比较少用,所以本文只是介绍个人在实践中用到的一些内容,其他的东西如果有需要,可以自行查阅官方文档。
这个算是基本操作了,我们可以通过 only 来指定特定分支才会执行的 job,也有其他方法可以实现,比如 rules,具体请参考官方文档。
deploy-job:
stage: deploy
# 当前的这个 job 只会在 master 分支代码更新的时候会执行
only:
- "master"
这个也是基本操作,我们可以通过 needs 来指定不同 job 之间的依赖关系,比如 job1 依赖 job2,那么 job1 就会在 job2 执行完毕之后才会执行。
job1:
stage: deploy
needs:
- job2
我们可以通过 tags 来指定 job 执行的 runner,比如我们可以指定 job 只能在 api 标签的 runner 上执行。
build-job:
stage: build
tags:
- api
如果我们没有标签为 api 的 runner,那么这个 job 就会一直不会被执行,所以需要确保我们配置的 tag 有对应的 runner。
注意:这个只在我们的 runner 的 executor 为 docker 的时候才会生效。也就是我们的 runner 是一个 docker 容器。
有时候,我们需要执行一些特定命令,但是我们全局的 docker 镜像里面没有,可能只需要一个特定的 docker 镜像,这个时候我们可以通过 image 来指定 job 的 docker 镜像。
deploy-job:
stage: deploy
tags:
- api
# 指定 runner 的 docker image
image: eleven26/rsync:1.3.0
script:
# 下面这个命令只在上面指定的 docker 镜像中存在
- rsync . root@example.com:/home/www/foo
在我们的 CI 流程中,可能会有一些集成测试需要使用到一些服务,比如我们的 mysql,这个时候我们可以通过 services 来指定我们需要的服务。
test_RabbitMQ:
# 这会启动一个 rabbitMQ 3.8 的 docker 容器,我们的 job 就可以使用这个容器了。
# 我们的 job 可以连接到一个 rabbitmq 的服务,然后进行测试。
# 需要注意的是,这个容器只会在当前 job 执行的时候存在,执行完毕之后就会被删除。所以产生的数据不会被保留。
services:
- rabbitmq:3.8
stage: test
only:
- master
tags:
- Go
script:
# 下面的测试命令会连接到上面启动的 rabbitmq 服务
- "go test -v -cover ./pkg/rabbitmq"
在 yaml 中,有一种机制可以让我们复用 yaml 配置片段,比如:
# 发布代码的 job
.deploy-job: &release-job
tags:
- api
image: eleven26/rsync:1.3.0
script:
- rsync . root@example.com:/home/www/foo
deploy-release:
<<: *release-job
stage: deploy
only:
- "release"
deploy-master:
<<: *release-job
stage: deploy
only:
- "master"
上面的代码中,我们定义了一个 release-job 的配置片段,然后在 deploy-release 和 deploy-master 中,我们都引用了这个配置片段,这样我们就可以复用这个配置片段了。 等同于下面的代码:
# 发布代码的 job
.deploy-job: &release-job
tags:
- api
image: eleven26/rsync:1.3.0
script:
- rsync . root@example.com:/home/www/foo
deploy-release:
tags:
- api
image: eleven26/rsync:1.3.0
script:
- rsync . root@example.com:/home/www/foo
stage: deploy
only:
- "release"
deploy-master:
tags:
- api
image: eleven26/rsync:1.3.0
script:
- rsync . root@example.com:/home/www/foo
stage: deploy
only:
- "master"
在 yaml 的术语中,这一种机制叫做 anchor。
初次使用的人,可能会对这个东西有点迷惑,因为它们好像都是缓存,但是实际上,它们的用途是不一样的。
cache 是用来缓存依赖的,比如 node_modules 文件夹,它可以加快后续 pipeline 的执行流程,因为避免了重复的依赖安装。artifacts 是用来缓存构建产物的,比如 build 之后生成的静态文件,它可以在后续的 stage 中使用。表示的是单个 pipeline 中的不同 stage 之间的共享。我们可以通过 expire_in 来指定 artifacts 的过期时间,比如:
job1:
stage: build
only:
- "release"
image: eleven26/apidoc:1.0.0
tags:
- api
artifacts:
paths:
- public
expire_in: 1 hour
因为我们的 artifacts 有时候只是生成一些需要部署到服务器的东西,然后在下一个 stage 使用,所以是不需要长期保留的。所以我们可以通过 expire_in 来指定一个比较短的 artifacts 的过期时间。
gitlab CI 的 cache 有一个 policy 属性,它的值默认是 pull-push,也就是在 job 开始执行的时候会拉取缓存,在 job 执行结束的时候会将缓存指定文件夹的内容上传到 gitlab 中。
但是在实际使用中,我们其实只需要在安装依赖的时候上传这些缓存,其他时候都只是读取缓存的。所以我们在安装依赖的 job 中使用默认的 policy,而在后续的 job 中,我们可以通过 policy: pull 来指定只拉取缓存,不上传缓存。
job:
tags:
- api
image: eleven26/rsync:1.3.0
cache:
key:
files:
- composer.JSON
- composer.lock
paths:
- "vendor/"
policy: pull # 只拉取 vendor,在 job 执行完毕之后不上传 vendor
这一个特性是非常有用的,在现代软件工程的实践中,往往通过 *.lock 文件来记录我们使用的额依赖的具体版本,以保证在不同环境中使用的时候保持一致的行为。
所以,相应的,我们的缓存也可以在 *.lock 这类文件发生变化的时候,重新生成缓存。上面的例子就使用了这种机制。
在 script 中,我们可以使用多行命令,比如:
job:
script:
# 我们可以通过下面这种方式来写多行的 shell 命令,也就是以一个竖线开始,然后换行
- |
if [ "$release_host" != "" ]; then
host=$release_host
fi
如果我们的项目需要部署到服务器上,那么我们还需要做一些额外的操作,比如同步代码到服务器上。 如果我们的 gitlab 是通过容器执行的,或者我们的 runner 的 executor 是 docker,那么有一种比较常见的方法是通过 ssh 私钥来进行部署。
我们可以通过以下流程来实现:
id_rsa 和 id_rsa.pub。id_rsa.pub 的内容添加到服务器的 authorized_keys 文件中。id_rsa 上传到 gitlab 中(在项目的 CI/CD 配置中,配置一个变量,变量名为 PRIVATE_KEY,内容为 id_rsa 的内容,类型为 file)。ci 配置文件中,添加如下配置即可:before_script:
- chmod 600 $PRIVATE_KEY
deploy:
stage: deploy
image: eleven26/rsync:1.3.0
script:
# $user 是 ssh 的用户
# $host 是 ssh 的主机
# $port 是 ssh 的端口
# $PRIVATE_KEY 是我们在 gitlab 中配置的私钥
- rsync -az -e "ssh -o StrictHosTKEyChecking=no -p $port -i $PRIVATE_KEY" --delete --exclude='.git' . $user@$host:/home/www
这里的 rsync 命令中,我们使用了 -o StrictHostKeyChecking=no 参数,这是为了避免每次都需要手动输入 yes 来确认服务器的指纹。
安全最佳实践:
必须严格遵循以上两步,否则会造成严重的安全问题。
最后,总结一下本文中一些比较关键的内容:
pipeline:代表了一次 CI 的执行过程,它包含了多个 stage。stage:代表了一组 job 的集合,stage 会按照顺序执行。job:代表了一个具体的任务,比如 build、test、deploy 等。stage 中的多个 job 是可以并行执行的。但是下一个 stage 的 job 必须要等到上一个 stage 的所有 job 都执行完毕之后才会执行。cache 和 artifacts 的区别:cache 是用来缓存依赖的,比如 node_modules 文件夹,它可以加快后续 pipeline 的执行流程,因为避免了重复的依赖安装。artifacts 是用来缓存构建产物的,比如 build 之后生成的静态文件,它可以在后续的 stage 中使用。表示的是单个 pipeline 中的不同 stage 之间的共享。cache 在安装依赖的 job 中才需要使用默认的 policy,也就是 pull-push,在其他不需要安装依赖的 job 中使用 pull 就可以了,不需要上传缓存。cache 的 key 可以指定多个文件,这样在指定的文件变动的时候,缓存会失效,这往往用在依赖相关的文件中。services 关键字来指定需要启动的服务,比如 mysql、redis 等,在 job 中可以连接到这些 services,从而方便进行测试。yaml 的 anchor 机制来复用一些配置片段,可以少写很多重复的配置。job 必须运行在某个 runner 上,job 和 runner 的关联是通过 tag 来指定的。以上就是gitlab ci cd 不完全指南的详细内容,更多关于gitlab ci cd 的资料请关注编程网其它相关文章!
--结束END--
本文标题: gitlab ci cd 命令的使用不完全指南
本文链接: https://www.lsjlt.com/news/209665.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-23
2024-05-22
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-13
2024-05-13
2024-05-11
2024-05-11
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答
一口价域名售卖能注册吗?域名是网站的标识,简短且易于记忆,为在线用户提供了访问我们网站的简单路径。一口价是在域名交易中一种常见的模式,而这种通常是针对已经被注册的域名转售给其他人的一种方式。
一口价域名买卖的过程通常包括以下几个步骤:
1.寻找:买家需要在域名售卖平台上找到心仪的一口价域名。平台通常会为每个可售的域名提供详细的描述,包括价格、年龄、流
443px" 443px) https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294.jpg https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294-768x413.jpg 域名售卖 域名一口价售卖 游戏音频 赋值/切片 框架优势 评估指南 项目规模

官方手机版

微信公众号

商务合作




0