目录1. 现状说明1.1 数据湖摄取和计算过程 - 处理更新1.2 当前批处理过程中的挑战2. Hudi 数据湖 — 查询模式2.1 面向分析师的表/OLAP(按 created_date 分区)2.2 面向
Apache Hudi(简称:Hudi)使得您能在hadoop兼容的存储之上存储大量数据,同时它还提供两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。
在我们的用例中1-10% 是对历史记录的更新。当记录更新时,我们需要从之前的 updated_date 分区中删除之前的条目,并将条目添加到最新的分区中,在没有删除和更新功能的情况下,我们必须重新读取整个历史表分区 -> 去重数据 -> 用新的去重数据覆盖整个表分区
这个过程有效,但也有其自身的缺陷:
借助Apache Hudi,我们希望在将数据摄取到数据湖中的同时,找到更好的重复数据删除和数据版本控制优化解决方案。
当我们开始在我们的数据湖上实现 Apache Hudi 的旅程时,我们根据表的主要用户的查询模式将表分为 2 类。
这是一个示例电子商务订单数据流,从摄取到数据湖到创建 OLAP,最后到业务分析师查询它
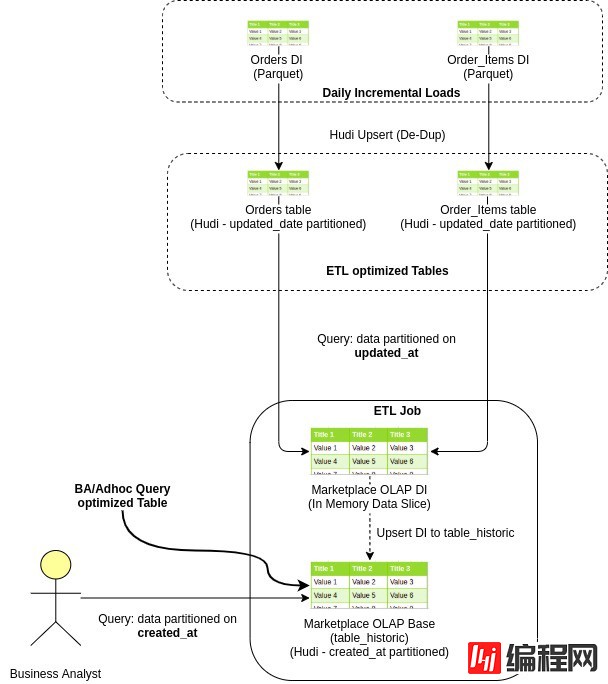
由于两种类型的表的日期分区列不同,我们采用不同的策略来解决这两个用例。
在 Hudi 中,我们需要指定分区列和主键列,以便 Hudi 可以为我们处理更新和删除。
以下是我们如何处理面向分析师的表中的更新和删除的逻辑:
由于主键和 created_date 对于退出和传入记录保持相同,Hudi 通过使用来自传入记录 created_date 和 primary_key 列的此信息获取现有记录的分区和分区文件路径。
当我们开始使用 Hudi 时,在阅读了许多博客和文档之后,在 created_date 上对面向 ETL 的表进行分区似乎是合乎逻辑的。
此外 Hudi 提供增量消费功能,允许我们在 created_date 上对表进行分区,并仅获取在 D-1 或 D-n 上插入(插入或更新)的那些记录。
这种方法在理论上效果很好,但在改造传统的日常批处理过程中的增量消费时,它带来了其他一系列挑战:
Hudi 维护了在不同时刻在表上执行的所有操作的时间表,这些提交包含有关作为 upsertbWxMFKGATN 的一部分插入或重写的部分文件的信息,我们将此 Hudi 表称为 Commit Timeline。
这里要注意的重要信息是增量查询基于提交时间线,而不依赖于数据记录中存在的实际更新/创建日期信息。
历史数据重新摄取:在每个常规增量 D-1 拉取中,我们期望仅在 D-1 上更新的记录作为输出。但是在重新摄取历史数据的情况下,会再次出现类似于前面描述的冷启动问题的问题,并且下游作业也会出现 OOM。
作为面向 ETL 的作业的解决方法,我们尝试将数据分区保持在 updated_date 本身,然而这种方法也有其自身的挑战。
我们知道 Hudi 表的本地索引,Hudi 依靠索引来获取存储在数据分区本地目录中的 Row-to-Part_file 映射。因此,如果我们的表在 updated_date 进行分区,Hudi 无法跨分区自动删除重复记录。
Hudi 的全局索引策略要求我们保留一个内部或外部索引来维护跨分区的数据去重。对于大数据量,每天大约 2 亿条记录,这种方法要么运行缓慢,要么因 OOM 而失败。
因此,为了解决更新日期分区的数据重复挑战,我们提出了一种全新的重复数据删除策略,该策略也具有很高的性能。
进一步优化用 true 填充陈旧更新中的 _hoodie_is_deleted 列,并将其与每日增量负载结合。 通过基本 hudi 表路径发出此数据的 upsert 命令。 它将在单个操作(和单个提交)中执行插入和删除。
作为数据版本控制的另一个好处,它解决了并发读取和写入问题,因为数据版本控制使并发读取器可以读取数据文件的版本控制副本,并且当并发写入器用新数据覆盖同一分区时不会抛出 FileNotFoundException 文件。
到此这篇关于Apache Hudi 如何加速传统的批处理模式的文章就介绍到这了,更多相关Apache bWxMFKGATN;Hudi 批处理模式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
--结束END--
本文标题: 使用Apache Hudi 加速传统的批处理模式的方法
本文链接: https://www.lsjlt.com/news/21637.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0