本节简单介绍了postgresql中的HTAB如何动态扩展,这是第2部分,结合代码进行解析.一、数据结构struct HTAB{ //指向共享的控制信息 HASHHDR *hctl; //段目录
本节简单介绍了postgresql中的HTAB如何动态扩展,这是第2部分,结合代码进行解析.
struct HTAB{ //指向共享的控制信息 HASHHDR *hctl; //段目录 HASHSEGMENT *dir; //哈希函数 HashValueFunc hash; //哈希键比较函数 HashCompareFunc match; //哈希键拷贝函数 HashCopyFunc keycopy; //内存分配器 HashAllocFunc alloc; //内存上下文 MemoryContext hcxt; //表名(用于错误信息) char *tabname; //如在共享内存中,则为T bool isshared; //如为T,则固定大小不能扩展 bool isfixed; //不允许冻结共享表,因此这里会保存相关状态 bool frozen; //保存这些固定值的本地拷贝,以减少冲突 //哈希键长度(以字节为单位) Size keysize; //段大小,必须为2的幂 long ssize; //段偏移,ssize的对数 int sshift; };struct HASHHDR{ //#define NUM_FREELISTS 32 FreeListData freeList[NUM_FREELISTS]; //这些域字段可以改变,但不适用于分区表 //同时,就算是非分区表,共享表的dsize也不能改变 //目录大小 long dsize; //已分配的段大小(<= dsize) long nsegs; //正在使用的最大桶ID uint32 max_bucket; //进入整个哈希表的模掩码 uint32 high_mask; //进入低位哈希表的模掩码 uint32 low_mask; //下面这些字段在哈希表创建时已固定 //哈希键大小(以字节为单位) Size keysize; //所有用户元素大小(以字节为单位) Size entrysize; //分区个数(2的幂),或者为0 long num_partitions; //目标的填充因子 long ffactor; //如目录是固定大小,则该值为dsize的上限值 long max_dsize; //段大小,必须是2的幂 long ssize; //段偏移,ssize的对数 int sshift; //一次性分配的条目个数 int nelem_alloc; #ifdef HASH_STATISTICS long accesses; long collisions;#endif};typedef struct{ //该空闲链表的自旋锁 slock_t mutex; //相关桶中的条目个数 long nentries; //空闲元素链 HASHELEMENT *freeList; } FreeListData;typedef struct HASHELEMENT{ //链接到相同桶中的下一个条目 struct HASHELEMENT *link; //该条目的哈希函数结果 uint32 hashvalue; } HASHELEMENT;//哈希表头部结构,非透明类型,用于dynahash.ctypedef struct HASHHDR HASHHDR;//哈希表控制结构,非透明类型,用于dynahash.ctypedef struct HTAB HTAB;//hash_create使用的参数数据结构//根据hash_flags标记设置相应的字段typedef struct HASHCTL{ //分区个数(必须是2的幂) long num_partitions; //段大小 long ssize; //初始化目录大小 long dsize; //dsize上限 long max_dsize; //填充因子 long ffactor; //哈希键大小(字节为单位) Size keysize; //参见上述数据结构注释 Size entrysize; // HashValueFunc hash; HashCompareFunc match; HashCopyFunc keycopy; HashAllocFunc alloc; MemoryContext hcxt; //共享内存中的哈希头部结构地址 HASHHDR *hctl; } HASHCTL;//哈希桶是HASHELEMENTs链表typedef HASHELEMENT *HASHBUCKET;//hash segment是桶数组typedef HASHBUCKET *HASHSEGMENT;typedef uint32 (*HashValueFunc) (const void *key, Size keysize); typedef int (*HashCompareFunc) (const void *key1, const void *key2, Size keysize); typedef void *(*HashCopyFunc) (void *dest, const void *src, Size keysize);typedef void *(*HashAllocFunc) (Size request);其结构如下图所示: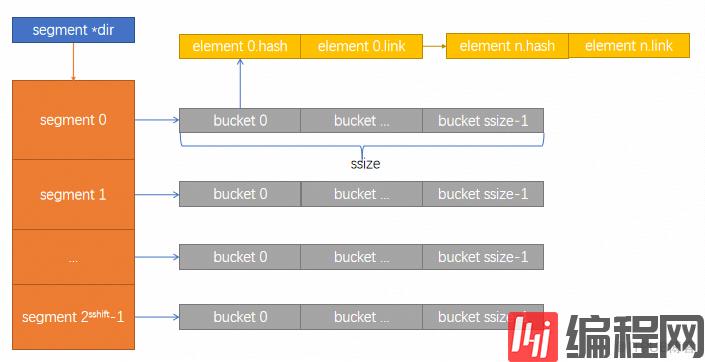
扩展后的结构如下图所示: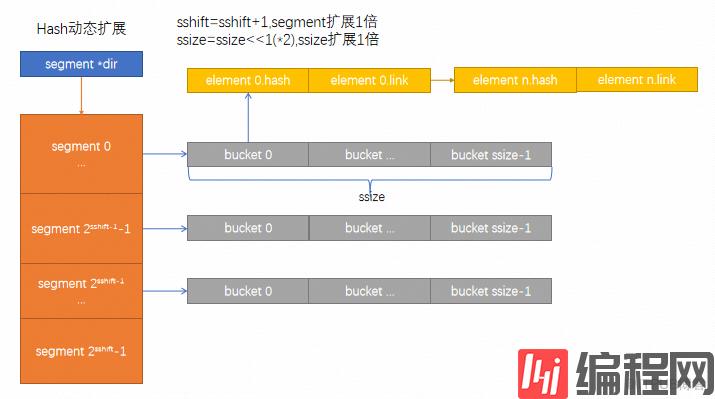
主要的函数是expand_table
1.分配新桶,HTAB的最大桶数max_bucket+1
2.根据新桶号计算段号和段内编号
3.如需扩展段,则扩展(*2)
4.获取新桶号对应的原桶号,目的是为了把原桶号中的数据迁移到新桶中.新桶号和原桶号相差low_mask
5.扫描旧桶,重建旧桶元素链表,构造新桶元素链表
static boolexpand_table(HTAB *hashp){ HASHHDR *hctl = hashp->hctl;//hash控制结构 HASHSEGMENT old_seg,//原seg new_seg;//新seg long old_bucket,//原bucket new_bucket;//新bucket long new_segnum,//新seg号 new_segndx;//新seg索引(segment中的编号) long old_segnum,//新seg号 old_segndx;//原seg索引 HASHBUCKET *oldlink,//原桶 *newlink;//新桶 HASHBUCKET currElement,//当前元素 nextElement;//下一元素 //#define IS_PARTITIONED(hctl) ((hctl)->num_partitions != 0) Assert(!IS_PARTITIONED(hctl));#ifdef HASH_STATISTICS hash_expansions++;#endif new_bucket = hctl->max_bucket + 1;//新增加一个bucket new_segnum = new_bucket >> hashp->sshift;//取商数 new_segndx = MOD(new_bucket, hashp->ssize);//取余数 if (new_segnum >= hctl->nsegs) { //扩展segment,每次扩展一倍 if (new_segnum >= hctl->dsize) if (!dir_realloc(hashp)) return false; if (!(hashp->dir[new_segnum] = seg_alloc(hashp)))//为新的seg对应的bucket分配空间 return false; hctl->nsegs++; } //已完成创建 hctl->max_bucket++; old_bucket = (new_bucket & hctl->low_mask); if ((uint32) new_bucket > hctl->high_mask) { hctl->low_mask = hctl->high_mask;//如15->31 hctl->high_mask = (uint32) new_bucket | hctl->low_mask;//如31->63 } old_segnum = old_bucket >> hashp->sshift;//计算原seg号 old_segndx = MOD(old_bucket, hashp->ssize);//计算原seg中的索引号 old_seg = hashp->dir[old_segnum];//旧seg new_seg = hashp->dir[new_segnum];//新seg oldlink = &old_seg[old_segndx];//原bucket指针 newlink = &new_seg[new_segndx];//新bucket指针 for (currElement = *oldlink; currElement != NULL; currElement = nextElement)//循环遍历 { nextElement = currElement->link; if ((long) calc_bucket(hctl, currElement->hashvalue) == old_bucket) { *oldlink = currElement; oldlink = &currElement->link;//重新构造原bucket } else { *newlink = currElement;//构造新bucket newlink = &currElement->link; } } //不要忘了终止重建后的hash链 *oldlink = NULL; *newlink = NULL; return true;}static booldir_realloc(HTAB *hashp){ HASHSEGMENT *p; HASHSEGMENT *old_p; long new_dsize; long old_dirsize; long new_dirsize; if (hashp->hctl->max_dsize != NO_MAX_DSIZE) return false; new_dsize = hashp->hctl->dsize << 1; old_dirsize = hashp->hctl->dsize * sizeof(HASHSEGMENT); new_dirsize = new_dsize * sizeof(HASHSEGMENT); old_p = hashp->dir; CurrentDynaHashCxt = hashp->hcxt; p = (HASHSEGMENT *) hashp->alloc((Size) new_dirsize); if (p != NULL) { memcpy(p, old_p, old_dirsize); MemSet(((char *) p) + old_dirsize, 0, new_dirsize - old_dirsize); hashp->dir = p; hashp->hctl->dsize = new_dsize; Assert(hashp->alloc == DynaHashAlloc); pfree(old_p); return true; } return false;}static HASHSEGMENTseg_alloc(HTAB *hashp){ HASHSEGMENT segp; CurrentDynaHashCxt = hashp->hcxt; segp = (HASHSEGMENT) hashp->alloc(sizeof(HASHBUCKET) * hashp->ssize); if (!segp) return NULL; MemSet(segp, 0, sizeof(HASHBUCKET) * hashp->ssize); return segp;}测试脚本
[local:/data/run/pg12]:5120 pg12@testdb=# \d t_expand; Table "public.t_expand" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- id | integer | | | [local:/data/run/pg12]:5120 pg12@testdb=# select count(*) from t_expand; count --------- 2000000(1 row)[local:/data/run/pg12]:5120 pg12@testdb=# select * from t_expand;...启动gdb跟踪
(gdb) b hash_search_with_hash_valueBreakpoint 2 at 0xa790f2: file dynahash.c, line 925.(gdb) cContinuing.Breakpoint 2, hash_search_with_hash_value (hashp=0x224eac8, keyPtr=0x7fffed717700, hashvalue=2252448879, action=HASH_ENTER, foundPtr=0x7fffed7176ff) at dynahash.c:925925 HASHHDR *hctl = hashp->hctl; --> hash控制结构体(gdb) n926 int freelist_idx = FREELIST_IDX(hctl, hashvalue);--> 空闲链表(gdb) p *hctl$1 = {freeList = {{mutex = 0 '\000', nentries = 0, freeList = 0x22504d0}, {mutex = 0 '\000', nentries = 0, freeList = 0x0} <repeats 31 times>}, dsize = 256, nsegs = 1, max_bucket = 15, high_mask = 31, low_mask = 15, keysize = 20, entrysize = 72, num_partitions = 0, ffactor = 1, max_dsize = -1, ssize = 256, sshift = 8, nelem_alloc = 46}(gdb) n949 if (action == HASH_ENTER || action == HASH_ENTER_NULL) (gdb) 956 if (!IS_PARTITIONED(hctl) && !hashp->frozen &&(gdb) 957 hctl->freeList[0].nentries / (long) (hctl->max_bucket + 1) >= hctl->ffactor && --> 判断是否需要扩展(gdb) 956 if (!IS_PARTITIONED(hctl) && !hashp->frozen &&(gdb) 965 bucket = calc_bucket(hctl, hashvalue);-->计算hash桶(gdb) stepcalc_bucket (hctl=0x224eb60, hash_val=2252448879) at dynahash.c:871871 bucket = hash_val & hctl->high_mask;-->先行与high_mask(31)进行掩码运算(gdb) n872 if (bucket > hctl->max_bucket)-->得到的结果如何比max_bucket还大,那要跟low_mask(15)进行掩码运算(gdb) p bucket$2 = 15(gdb) n875 return bucket;(gdb) l870 871 bucket = hash_val & hctl->high_mask;872 if (bucket > hctl->max_bucket)873 bucket = bucket & hctl->low_mask;874 875 return bucket;876 }877 878 (gdb) 982 keysize = hashp->keysize; (gdb) 984 while (currBucket != NULL)(gdb) 997 if (foundPtr)(gdb) 998 *foundPtr = (bool) (currBucket != NULL);(gdb) 1003 switch (action)(gdb) 1047 if (currBucket != NULL)(gdb) 1051 if (hashp->frozen)(gdb) 1055 currBucket = get_hash_entry(hashp, freelist_idx);(gdb) 1056 if (currBucket == NULL)(gdb) 1073 *prevBucketPtr = currBucket;(gdb) 1074 currBucket->link = NULL;(gdb) 1077 currBucket->hashvalue = hashvalue;(gdb) 1078 hashp->keycopy(ELEMENTKEY(currBucket), keyPtr, keysize);(gdb) 1087 return (void *) ELEMENTKEY(currBucket);(gdb) 1093 }(gdb) hash_search (hashp=0x224eac8, keyPtr=0x7fffed717700, action=HASH_ENTER, foundPtr=0x7fffed7176ff) at dynahash.c:916916 }(gdb)N/A
--结束END--
本文标题: PostgreSQL 源码解读(248)- HTAB动态扩展图解#2
本文链接: https://www.lsjlt.com/news/227355.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0