这篇文章主要讲解了“Java集合HashMap的知识点详解”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Java集合HashMap的知识点详解”吧!一、什么是哈希表在讨论哈希表之前,我们先大
这篇文章主要讲解了“Java集合HashMap的知识点详解”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Java集合HashMap的知识点详解”吧!
一、什么是哈希表
在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下(后面会探讨下哈希冲突的情况),仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
这个函数可以简单描述为:存储位置 = f(关键字) ,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
插入过程如下图所示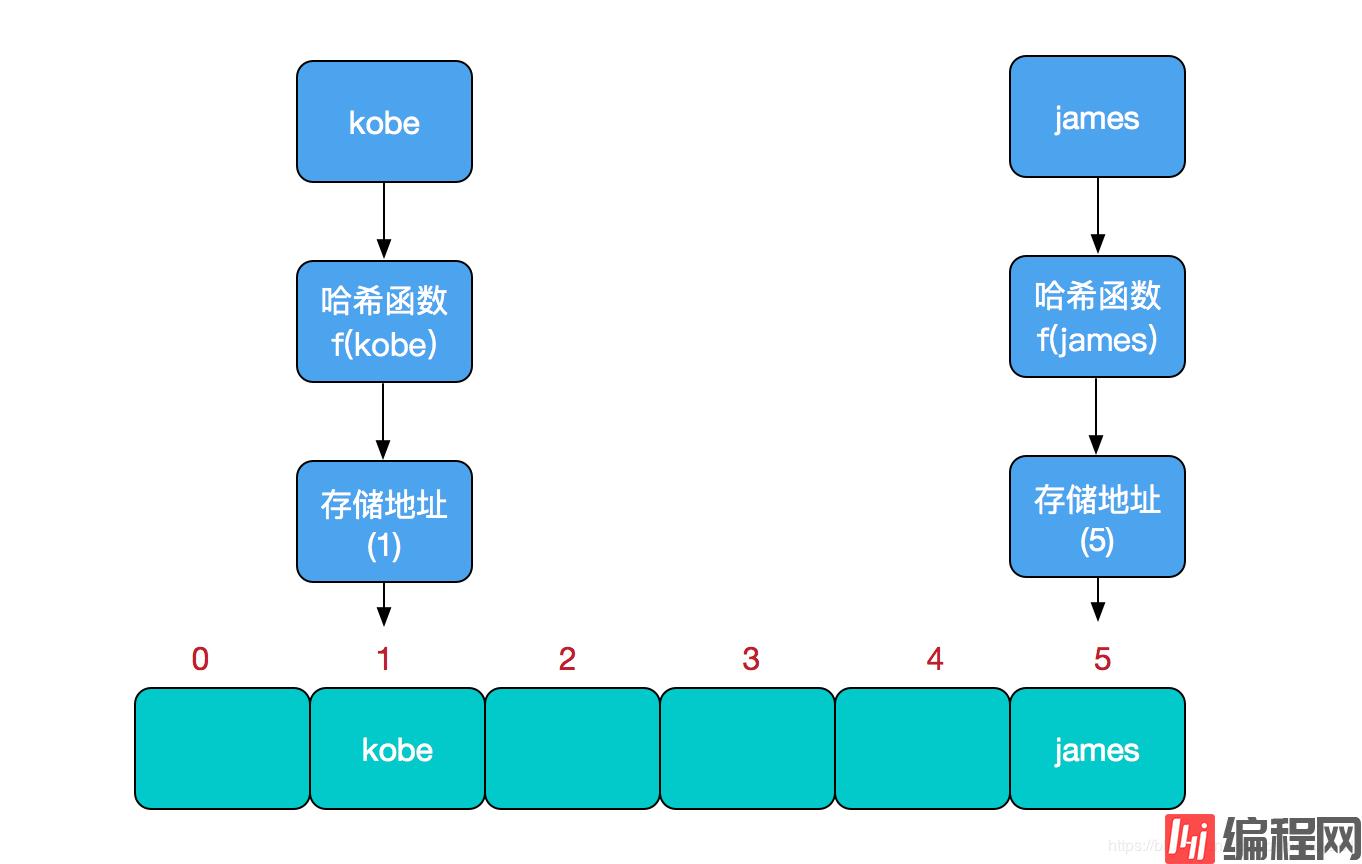
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
二、HashMap的实现原理
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。(其实所谓Map其实就是保存了两个对象之间的映射关系的一种集合)
//HashMap的主干数组,可以看到就是一个Entry数组,初始值为空数组{},主干数组的长度一定是2的次幂。//至于为什么这么做,后面会有详细分析。transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;123Entry是HashMap中的一个静态内部类。代码如下
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构 int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算 Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } 123456789101112131415所以,HashMap的总体结构如下: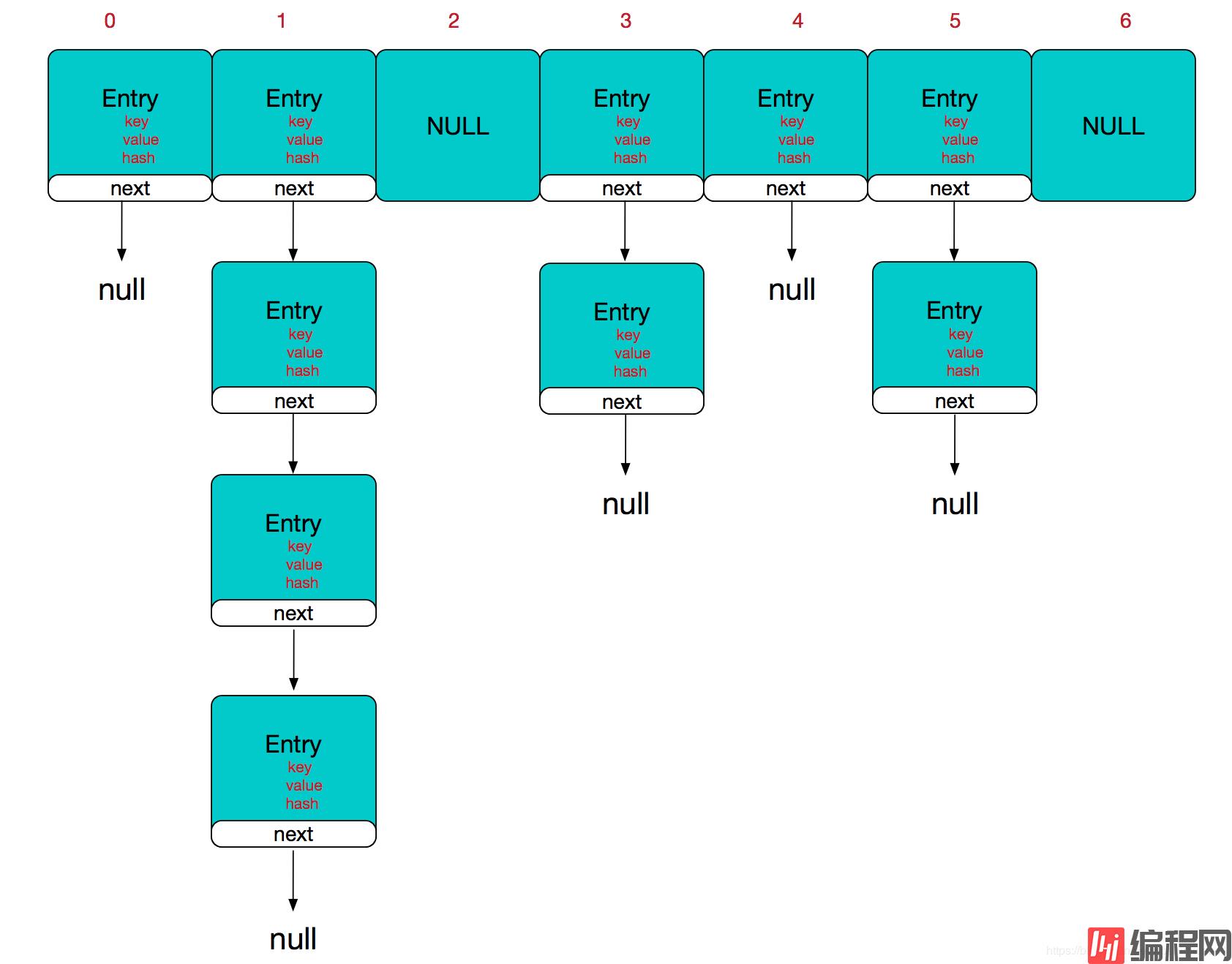
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
其他几个重要字段
transient int size;int threshold;final float loadFactor;transient int modCount;1234567891011121314151617HashMap有4个构造器,其他构造器如果用户没有传入initialCapacity 和loadFactor这两个参数,会使用默认值
initialCapacity默认为16,loadFactory默认为0.75
我们看下其中一个
public HashMap(int initialCapacity, float loadFactor) { //此处对传入的初始容量进行校验,最大不能超过MAXIMUM_CAPACITY = 1<<30(230) if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init();//init方法在HashMap中没有实际实现,不过在其子类如 linkedHashMap中就会有对应实现 }12345678910111213141516从上面这段代码我们可以看出,在常规构造器中,没有为数组table分配内存空间(有一个入参为指定Map的构造器例外),而是在执行put操作的时候才真正构建table数组
OK,接下来我们来看看put操作的实现
public V put(K key, V value) { //如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold, //此时threshold为initialCapacity 默认是1<<4(24=16) if (table == EMPTY_TABLE) { inflateTable(threshold); } //如果key为null,存储位置为table[0]或table[0]的冲突链上 if (key == null) return putForNullKey(value); int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀 int i = indexFor(hash, table.length);//获取在table中的实际位置 for (Entry<K,V> e = table[i]; e != null; e = e.next) { //如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败 addEntry(hash, key, value, i);//新增一个entry return null; }12345678910111213141516171819202122232425inflateTable这个方法用于为主干数组table在内存中分配存储空间,通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于toSize的最接近toSize的二次幂,比如toSize=13,则capacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
private void inflateTable(int toSize) { int capacity = roundUpToPowerOf2(toSize);//capacity一定是2的次幂 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); table = new Entry[capacity]; initHashSeedAsNeeded(capacity); }12345678roundUpToPowerOf2中的这段处理使得数组长度一定为2的次幂,Integer.highestOneBit是用来获取最左边的bit(其他bit位为0)所代表的数值.
private static int roundUpToPowerOf2(int number) { // assert number >= 0 : "number must be non-negative"; return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; }1234567hash函数
final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash42((String) k); } h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }12345678910111213以上hash函数计算出的值,通过indexFor进一步处理来获取实际的存储位置
static int indexFor(int h, int length) { return h & (length-1); }123456h&(length-1)保证获取的index一定在数组范围内,举个例子,默认容量16,length-1=15,h=18,转换成二进制计算为index=2。位运算对计算机来说,性能更高一些(HashMap中有大量位运算)
所以最终存储位置的确定流程是这样的:
再来看看addEntry的实现:
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length);//当size超过临界阈值threshold,并且即将发生哈希冲突时进行扩容 hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }123456789通过以上代码能够得知,当发生哈希冲突并且size大于阈值的时候,需要进行数组扩容,扩容时,需要新建一个长度为之前数组2倍的新的数组,然后将当前的Entry数组中的元素全部传输过去,扩容后的新数组长度为之前的2倍,所以扩容相对来说是个耗资源的操作。
三、为何HashMap的数组长度一定是2的次幂?
我们来继续看上面提到的resize方法
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }12345678910111213如果数组进行扩容,数组长度发生变化,而存储位置 index = h&(length-1),index也可能会发生变化,需要重新计算index,我们先来看看transfer这个方法
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; //for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已) for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); //将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。 e.next = newTable[i]; newTable[i] = e; e = next; } } }1234567891011121314151617这个方法将老数组中的数据逐个链表地遍历,扔到新的扩容后的数组中,我们的数组索引位置的计算是通过 对key值的hashcode进行hash扰乱运算后,再通过和 length-1进行位运算得到最终数组索引位置。
HashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。从下图可以我们也能看到这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了之前已经散列良好的老数组的数据位置重新调换),个人理解。
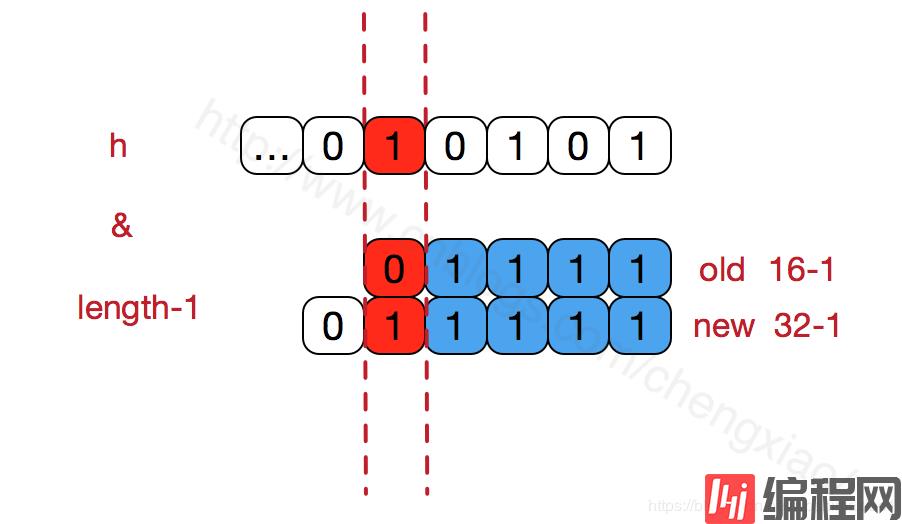
还有,数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀
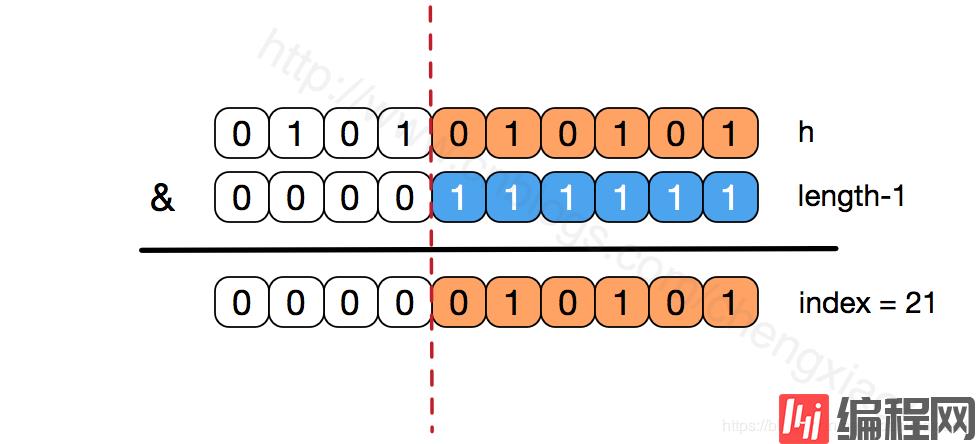
我们看到,上面的&运算,高位是不会对结果产生影响的(hash函数采用各种位运算可能也是为了使得低位更加散列),我们只关注低位bit,如果低位全部为1,那么对于h低位部分来说,任何一位的变化都会对结果产生影响,也就是说,要得到index=21这个存储位置,h的低位只有这一种组合。这也是数组长度设计为必须为2的次幂的原因。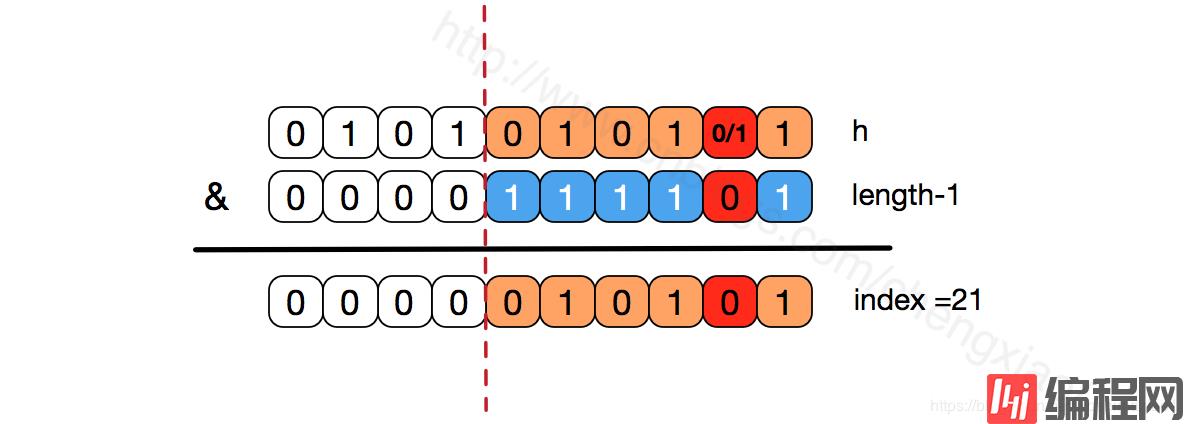
如果不是2的次幂,也就是低位不是全为1此时,要使得index=21,h的低位部分不再具有唯一性了,哈希冲突的几率会变的更大,同时,index对应的这个bit位无论如何不会等于1了,而对应的那些数组位置也就被白白浪费了。
get方法:
public V get(Object key) { //如果key为null,则直接去table[0]处去检索即可。 if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }1234567get方法通过key值返回对应value,如果key为null,直接去table[0]处检索。我们再看一下getEntry这个方法
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } //通过key的hashcode值计算hash值 int hash = (key == null) ? 0 : hash(key); //indexFor (hash&length-1) 获取最终数组索引,然后遍历链表,通过equals方法比对找出对应记录 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; } 123456789101112131415161718可以看出,get方法的实现相对简单,key(hashcode)–>hash–>indexFor–>最终索引位置,找到对应位置table[i],再查看是否有链表,遍历链表,通过key的equals方法比对查找对应的记录。要注意的是,有人觉得上面在定位到数组位置之后然后遍历链表的时候,e.hash == hash这个判断没必要,仅通过equals判断就可以。其实不然,试想一下,如果传入的key对象重写了equals方法却没有重写hashCode,而恰巧此对象定位到这个数组位置,如果仅仅用equals判断可能是相等的,但其hashCode和当前对象不一致,这种情况,根据Object的hashCode的约定,不能返回当前对象,而应该返回null,后面的例子会做出进一步解释。
四、重写equals方法需同时重写hashCode方法
最后我们再聊聊老生常谈的一个问题,各种资料上都会提到,“重写equals时也要同时覆盖hashcode”,我们举个小例子来看看,如果重写了equals而不重写hashcode会发生什么样的问题
public class MyTest { private static class Person{ int idCard; String name; public Person(int idCard, String name) { this.idCard = idCard; this.name = name; } @Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()){ return false; } Person person = (Person) o; //两个对象是否等值,通过idCard来确定 return this.idCard == person.idCard; } } public static void main(String []args){ HashMap<Person,String> map = new HashMap<Person, String>(); Person person = new Person(1234,"乔峰"); //put到hashmap中去 map.put(person,"天龙八部"); //get取出,从逻辑上讲应该能输出“天龙八部” System.out.println("结果:"+map.get(new Person(1234,"萧峰"))); }}实际输出结果:null1234567891011121314151617181920212223242526272829303132333435如果我们已经对HashMap的原理有了一定了解,这个结果就不难理解了。尽管我们在进行get和put操作的时候,使用的key从逻辑上讲是等值的(通过equals比较是相等的),但由于没有重写hashCode方法,所以put操作时,key(hashcode1)–>hash–>indexFor–>最终索引位置 ,而通过key取出value的时候 key(hashcode1)–>hash–>indexFor–>最终索引位置,由于hashcode1不等于hashcode2,导致没有定位到一个数组位置而返回逻辑上错误的值null(也有可能碰巧定位到一个数组位置,但是也会判断其entry的hash值是否相等,上面get方法中有提到。)
所以,在重写equals的方法的时候,必须注意重写hashCode方法,同时还要保证通过equals判断相等的两个对象,调用hashCode方法要返回同样的整数值。而如果equals判断不相等的两个对象,其hashCode可以相同(只不过会发生哈希冲突,应尽量避免)。
五、JDK1.8中HashMap的性能优化
假如一个数组槽位上链上数据过多(即拉链过长的情况)导致性能下降该怎么办?
jdk1.8在JDK1.7的基础上针对增加了红黑树来进行优化。即当链表超过8时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高 HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
感谢各位的阅读,以上就是“Java集合HashMap的知识点详解”的内容了,经过本文的学习后,相信大家对Java集合HashMap的知识点详解这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: Java集合HashMap的知识点详解
本文链接: https://www.lsjlt.com/news/229752.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0