这篇文章主要讲解了“spark sql中的RDD与DataFrame转换实例用法”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Spark SQL中的RDD与DataFrame转换实例用法”吧
这篇文章主要讲解了“spark sql中的RDD与DataFrame转换实例用法”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Spark SQL中的RDD与DataFrame转换实例用法”吧!

反射把schema信息全部定义在case class 类里面package coreimport org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.types.StructTypeobject Test { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("Test") .master("local[2]") .getOrCreate() val mess = spark.sparkContext.textFile("file:///D:\\test\\person.txt") import spark.implicits._ val result = mess.map(_.split(",")).map(x => Info(x(0).toInt,x(1),x(2).toInt)).toDF() // result.map(x => x(0)).show() //在1.x 版本是可以的 在2.x不可以需要价格rdd result.rdd.map(x => x(0)).collect().foreach(println) result.rdd.map(x => x.getAs[Int]("id")).collect().foreach(println) }}case class Info(id:Int,name:String,age:Int)注意2.2版本以前 类的构造方法参数有限在2.2后没有限制了

制定scheme信息 就是编程的方式 作用到Row 上面
从原有的RDD转化 ,类似于textFile一个StructType匹配Row里面的数据结构(几列),就是几个StructField 通过createDataFrame 把schema与RDD关联上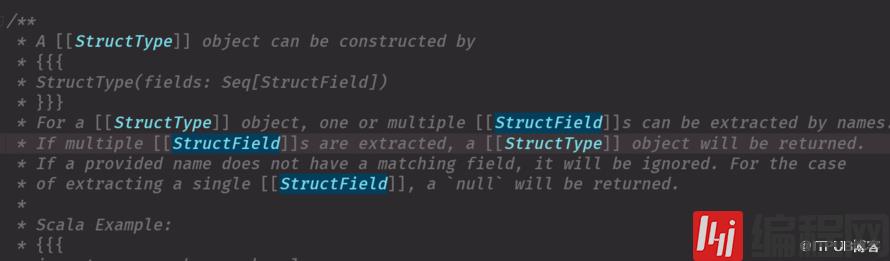
StructField 可以理解为一列StructType 包含 1-n 个StructFieldpackage coreimport org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}import org.apache.spark.sql.{Row, SparkSession}object TestRDD2 { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("TestRDD2") .master("local[2]") .getOrCreate() val mess = spark.sparkContext.textFile("file:///D:\\test\\person.txt") val result = mess.map(_.split(",")).map(x => Row(x(0).toInt, x(1), x(2).toInt)) //工作中这样写 val structType = new StructType( Array( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) ) ) val schema = StructType(structType) val info = spark.createDataFrame(result,schema) info.show() }}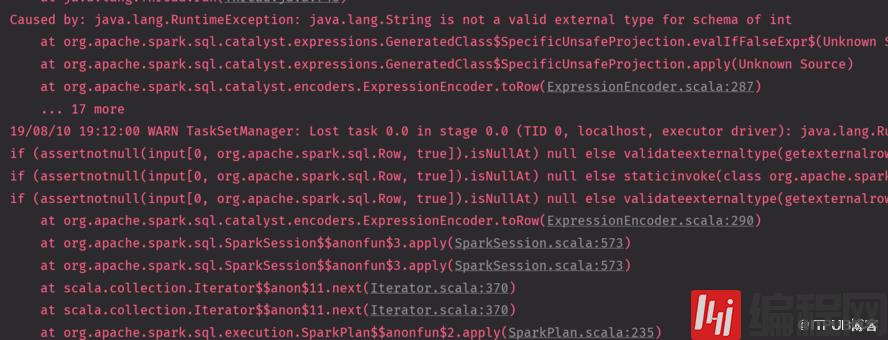
自己定义的schema信息与Row中的信息不匹配val result = mess.map(_.split(",")).map(x => Row(x(0), x(1), x(2)))//工作中这样写val structType = new StructType( Array( StructField("id", IntegerType, true), StructField("name", StringType, true), StructField("age", IntegerType, true) ))上面的是string 要的是int ,一定要注意因为会经常出错要转化类型val result = mess.map(_.split(",")).map(x => Row(x(0).toInt, x(1), x(2).toInt))df.select('name).show 这个在spark-shell 可以或者df.select('name').show 但是代码里面不行,需要隐士转show源码 默认是true 显示小于等于20条,对应行中的字符是false就全部显示出来show(30,false) 也是全部显示出来不会截断show(5) 但是后面的多与20字符就不会显示你可以show(5,false)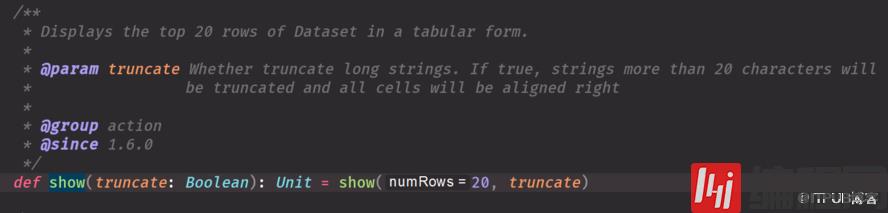
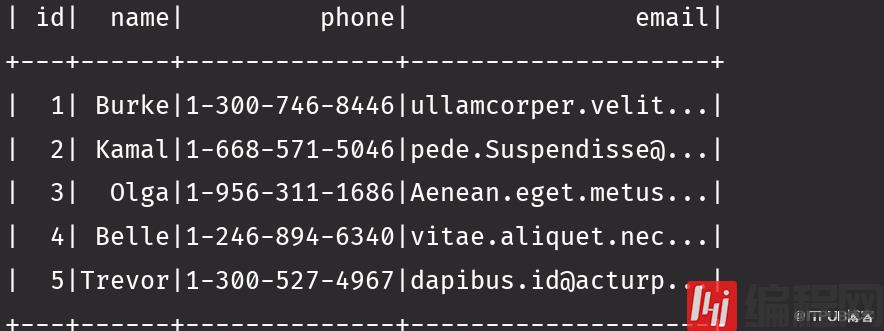
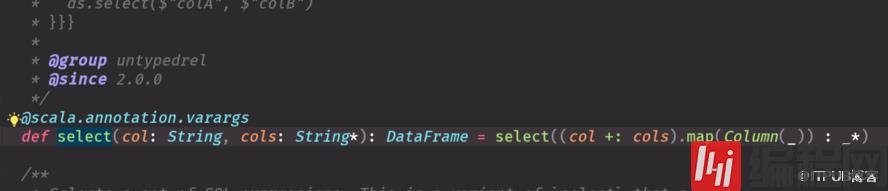
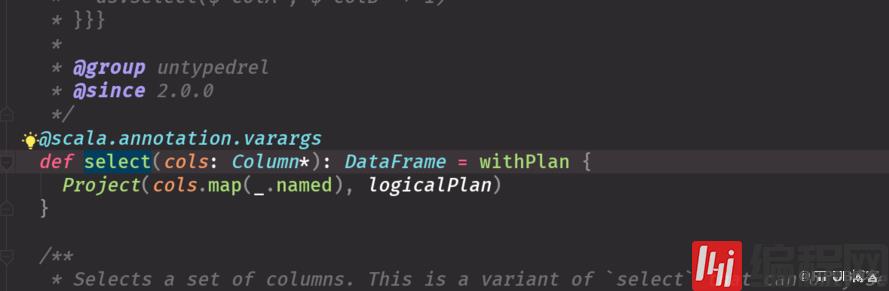
df.select("name").show(false)import spark.implicits._//这样不隐士转换不行df.select('name).show(false)df.select($"name")第一个select走的底层源码是 第一个源码图2,3个select走的源码是第二个head 默认调第一条,你想展示几条就调几条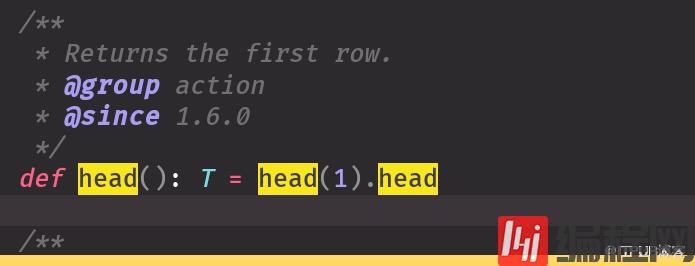
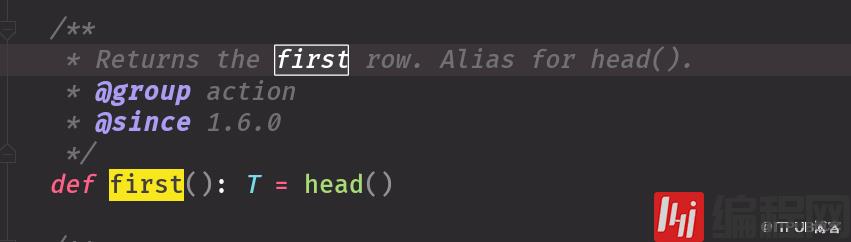
sort源码默认升序降序解释中有

全局视图加上 global_temp 规定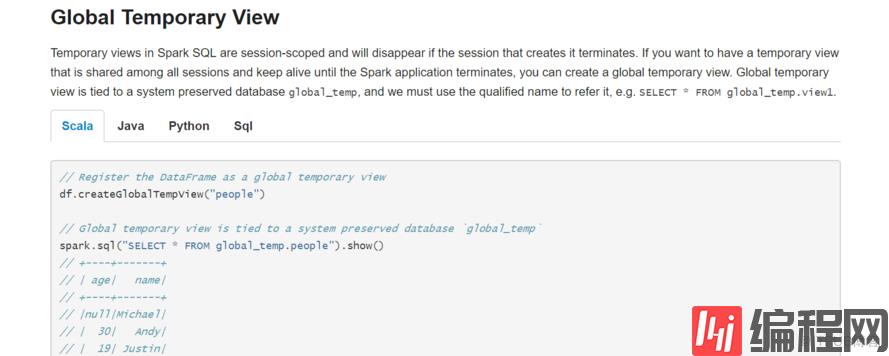

val spark = SparkSession.builder() .appName("Test") .master("local[2]") .getOrCreate() val mess = spark.sparkContext.textFile("file:///D:\\test\\person.txt") import spark.implicits._ val result = mess.map(_.split(",")).map(x => Info(x(0).toInt,x(1),x(2).toInt)).toDF() //在1.x 版本是可以的 在2.x不可以需要价格rdd result.map(x => x(0)).show() 这样写是对的 result.rdd.map(x => x(0)).collect().foreach(println) 去类中的数据两种写法: result.rdd.map(x => x(0)).collect().foreach(println)result.rdd.map(x => x.getAs[Int]("id")).collect().foreach(println)对于分隔符 | 你切分一定要加转义字符,否则数据不对感谢各位的阅读,以上就是“Spark SQL中的RDD与DataFrame转换实例用法”的内容了,经过本文的学习后,相信大家对Spark SQL中的RDD与DataFrame转换实例用法这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: Spark SQL中的RDD与DataFrame转换实例用法
本文链接: https://www.lsjlt.com/news/230081.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0