这篇文章将为大家详细讲解有关怎么进行spark的基本算子使用和源码解析,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。一.coalesce1.coalesce源码2.coalesce解释是窄依
这篇文章将为大家详细讲解有关怎么进行spark的基本算子使用和源码解析,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
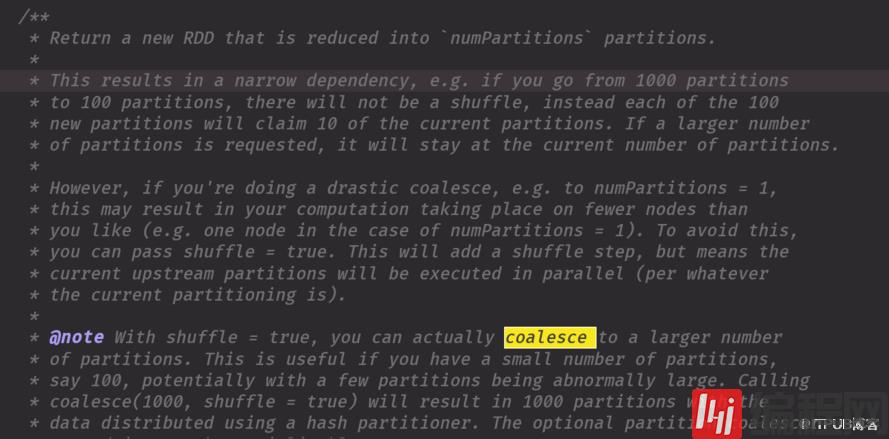

是窄依赖由多变少shuffer默认是false,要注意解决小文件,例如你如果开始有200个文件对应20分区,你极端情况下你过滤变长一个文件,你不能还用200个分区去装吧用coalesce解决,主要就是把前面的压缩一下,但是过滤完后你要用coalesce必须实现做预估
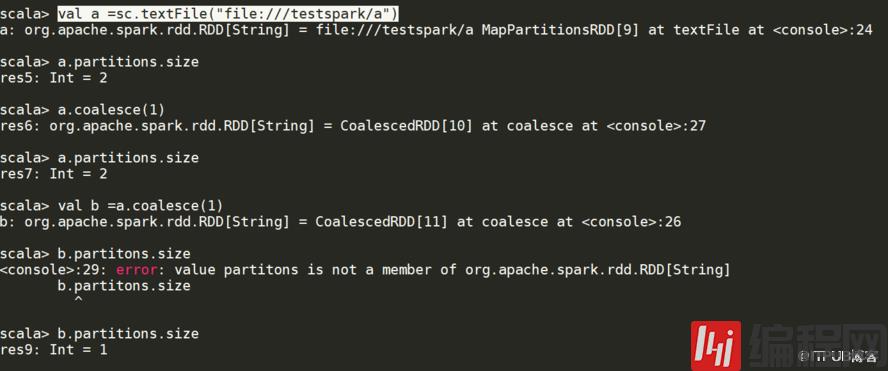
你如果是xxx.oalesce(1),从源头就是1,不会像mr可以设置reduce的数量下图说述的分区的大小a.partitions.size 你之前没有用变量接收coalesce 的值,是不会变得值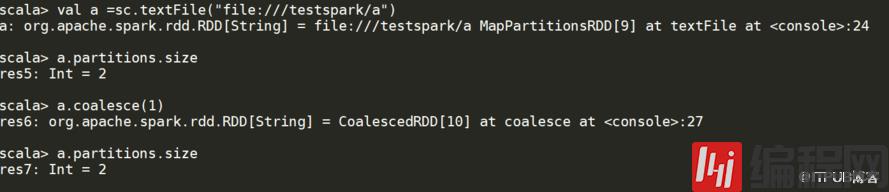
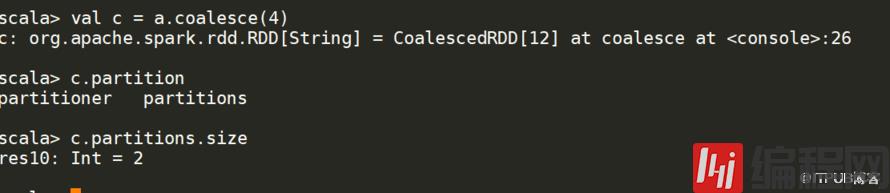
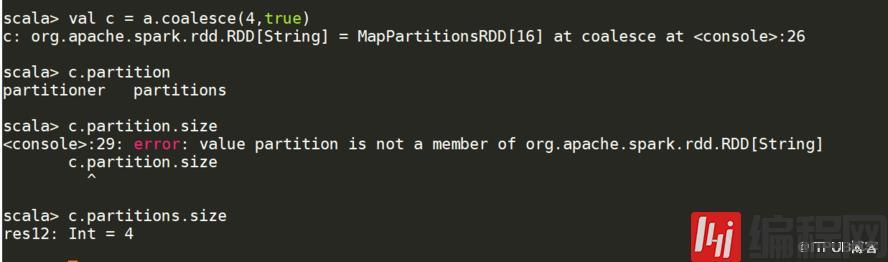
note With shuffle = true, you can actually coalesce to a larger number一般数不需要第二个参数的
就是repartition底层调用coalesce两个参数
每个函数操作的对象是每个元素千万不要用于操作数据库,否则一个元素要拿个connect,太耗费资源
每个函数作用在每个分区上,多用于操纵数据库,一个分区一个connect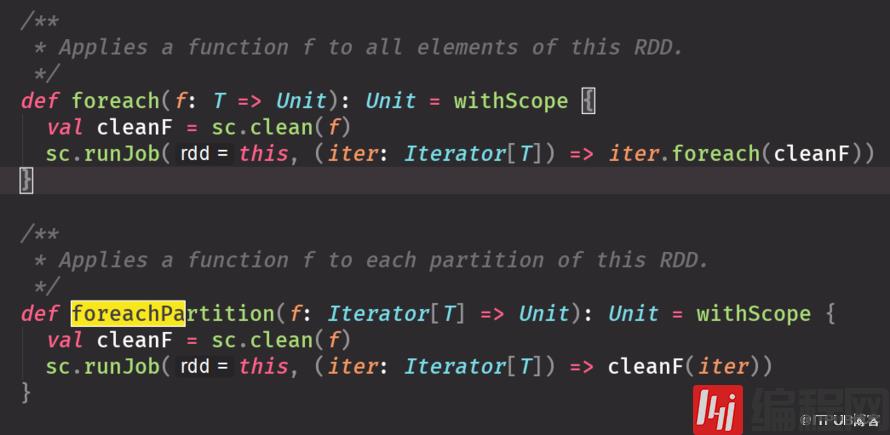
一个是打印每个元素,一个是按分区打印,都是actionforeachPartition多用于操作数据库,存储结果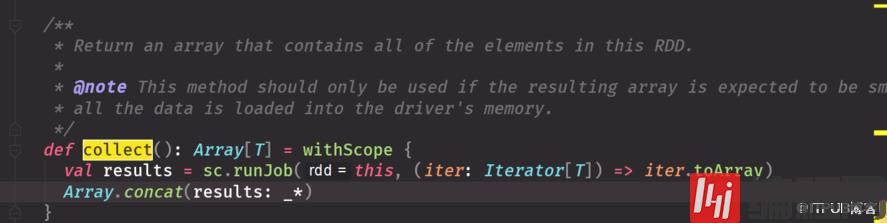
源码 返回数组,数组里包含所有元数数据小用可以,因为数据都会被放到内存里,输出到driver端的超过内存会报oom把driver 调大一些,有局限性RDD中元素太大,抽取回driver会报OOP不可以用collect可以用takecollectcollectByKeycollectByValuecollectAsMap 结果集出来后变成map这些要看数据量要悠着点用,都要数据量少广播变量必须数据量少才可以用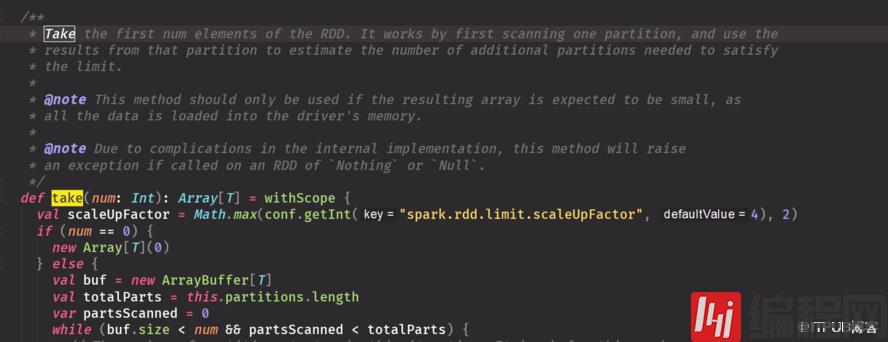
面试常问take是全部扫描还是部分扫描:部分扫描从源码有体现不确定数据有多大你可以先count一下如果少的情况下捏可以用collect,如果太多可以用take这些知识测试用要全部结果你可以保存到文件系统上去saveas...
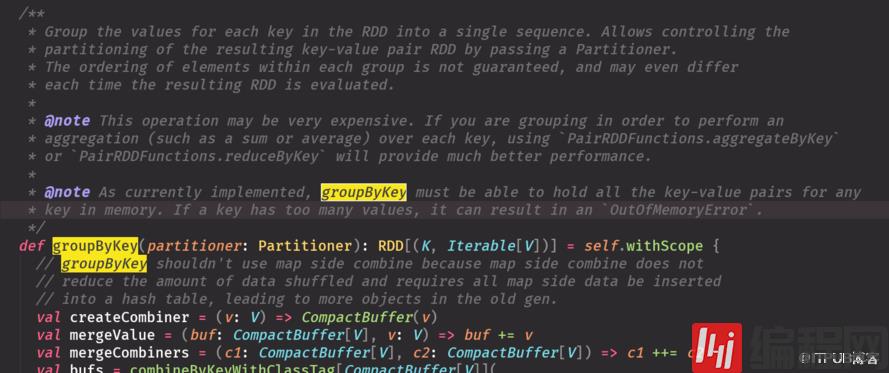


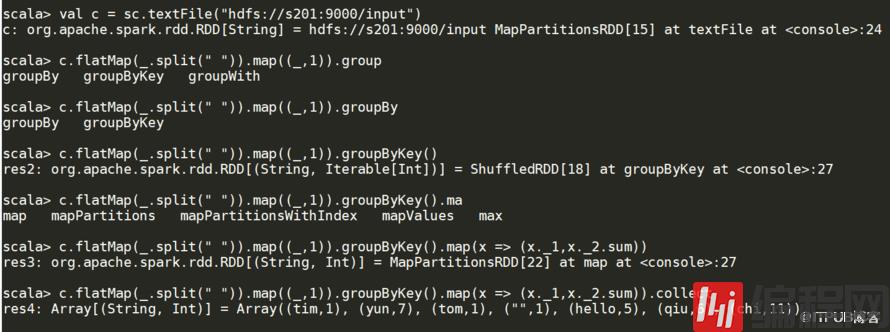
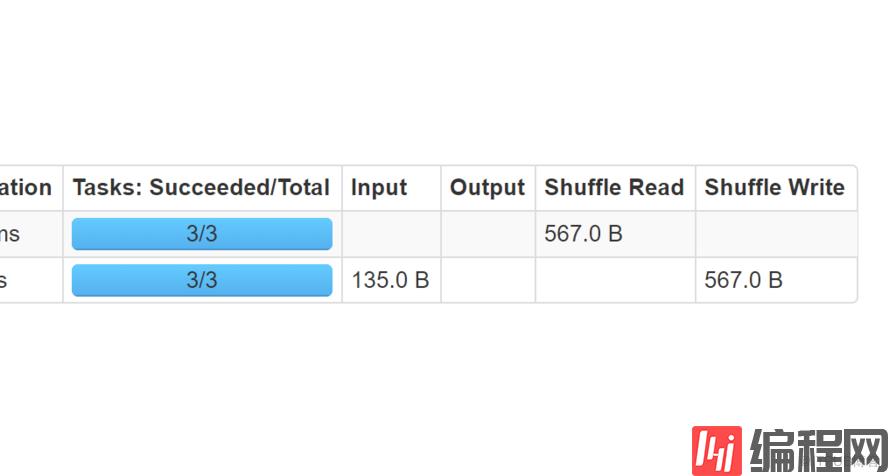
groupByKey 比reduceByKey 数据大小明显变大,不如reduceByKey 性能好
groupByKey 所有元素都shuffer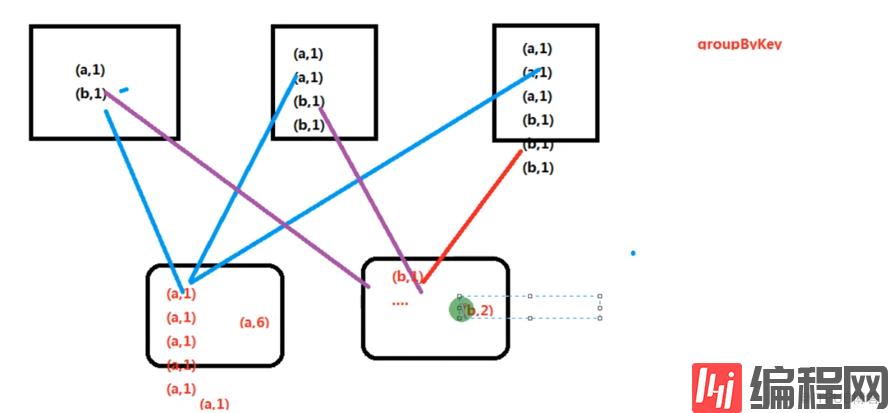
reduceByKey 在map阶段有一个聚合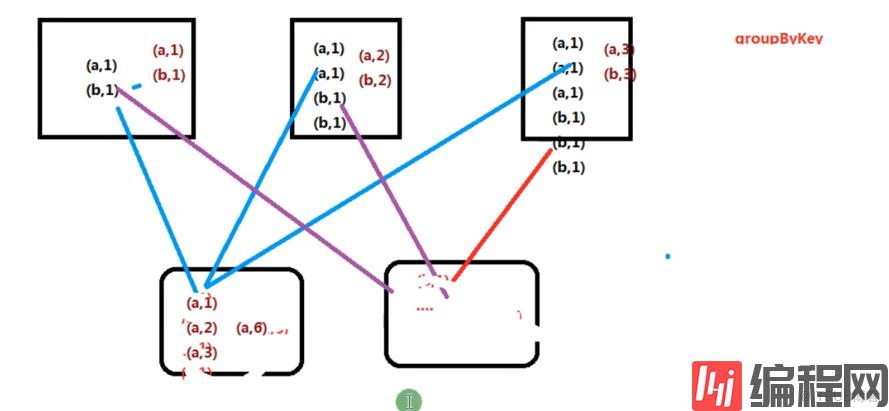
关于怎么进行spark的基本算子使用和源码解析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
--结束END--
本文标题: 怎么进行spark的基本算子使用和源码解析
本文链接: https://www.lsjlt.com/news/230196.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
2024-05-16
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0