这篇文章将为大家详细讲解有关hdfs分布式文件系统如何设计,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。正文HDFS的设计以及概念 HDFS集群是典型的 master/slave 架构,master 节
这篇文章将为大家详细讲解有关hdfs分布式文件系统如何设计,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
正文
HDFS的设计以及概念
HDFS集群是典型的 master/slave 架构,master 节点叫做 Namenode,salve 节点叫做 DataNode。最简单的 HDFS 集群便是一个 NameNode 节点和多个 DataNode 节点,HDFS 集群的架构图如下:
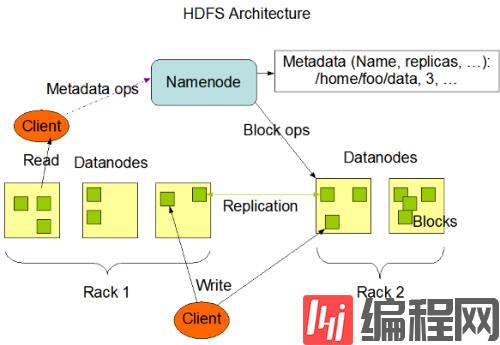
Block:数据块,HDFS 集群将存储的文件划分为多个分块,块作为独立的存储单元,默认大小为为 128M。如果某个文件超过集群单机存储容量,分块可以解决该问题;其次按照块进行存储、备份能简化系统的设计。默认块大小修改 hdfs-site.xml 文件中的 dfs.blocksize 配置。
NameNode:HDFS 集群的 Master 节点,维护集群文件的目录结构(命名空间)和编辑日志文件,同时在内存中记录文件各个块所在的数据节点的信息。
DataNode:HDFS 集群的 Slave 节点,负责存储实际的数据。根据需要存储和检索数据块,并定期向 NameNode 发送他们所存储的数据块列表。为了实现数据存储的高可靠,HDFS 将一个块存储在不同的 DataNode 节点, 默认是 3 个,可以通过 hdfs-site.xml 文件中的 dfs.replication 配置修改默认值。如果当前 DataNode 中的数据块损坏, 可以从其他 DataNode 节点复制一个正确的数据块。
以上是架构图中显而易见的几个重要概念,接下来将结合架构设计中的高可用、可扩展性来介绍下架构图中隐藏的几个重要概念。
联邦 HDFS:这个主要是为了解决可扩展性的问题,我们知道 NameNode 进程的内存中存放了数据与数据位置的对应关系,对于一个文件数据量多的集群来说,NameNode 的内存将成为集群规模扩大的瓶颈。因此,单一 NameNode 的集群并不可取。hadoop 2.x 的发行版引入了联邦 HDFS 允许向集群中添加 NameNode 节点实现横向扩展。每一个 NameNode 管理命名空间中的一部分,每个 NameNode 维护一个命名空间卷(namespace volume),命名空间卷之间相互独立,一个 NameNode 失效不会影响其他 NameNode 维护的命名空间。
HDFS HA: 这个解决高可用,即 HDFS High Available。这一实现中配置了一对活动-备用(active-standby)NameNode。当活动的 NameNode 失效,备用 NameNode 会接管相应的任务,这一过程对用户透明。实现这一设计,需要在架构上做如下修改:
1. HA 的两个 NameNode 之间通过高可用共享存储实现编辑日志的共享,目的是为了能够使备用 NameNode 接管工作后实现与主 NameNode 状态同步。QJM(日志管理器,quorum journal manager)是为提供一个高可用的日志编辑而设计的,被推荐用于大多数 HDFS 集群中。QJM 以一组日志节点的形式运行,一般是 3,每一次编辑必须写入多数日志节点,因此系统可以忍受任何一个节点丢失,日志节点便是 JournalNode。
2. DataNode 需要同时向 2 个 NameNode 发送数据报告,因为数据块的映射信息存储在 NameNode 的内存中
3. 客户端需要处理 NameNode 失效的问题,对用户透明
HDFS的基本操作
命令行接口
命令行接口操作 HDFS 是最简单、最方便的方式。HDFS 的命令与 linux 本地命令非常相似,可以通过 hadoop fs help 命令查看 HDFS 所支持所有命令,接下来介绍下常用的命令:
hadoop fs -put <localsrc> <dst> #将本地文件上传至 HDFS;
hadoop fs -ls <path> # 与 Linux ls命令类似;
hadoop fs -cat <src> #查看 HDFS 文件数据;
hadoop fs -text <path> # 同 cat 命令, 可以看 SequenceFile、压缩文件;
hadoop fs -rm <src> # 删除 HDFS 文件或目录。
以上是比较常用的 HDFS 命令,查看帮助文档可以在每个命令上增加一些命令行选项,输出不同的信息。以 ls 命令为例,看一下 HDFS 输出的文件信息。
hadoop fs -ls /hadoop-ex/Wordcount/input
-rw-r--r-- 3 root supergroup 32 2019-03-03 01:34 /hadoop-ex/wordcount/input/words
-rw-r--r-- 3 root supergroup 28 2019-03-03 01:46 /hadoop-ex/wordcount/input/words2
可以发现输出的内容与 Linux 下 ls 命令类似。第 1 部分显示文件类型与权限,第 2 部分是副本数量 3,第 3 、4部分是所属的用户和用户组,第 5 部分是文件大小,若是目录则为 0 ,第 6、7 部分是文件的修改日期和时间,第 8 部分是文件的路径和名称。 在 HDFS 中有个超级用户,即 启动 NameNode 的用户。
Java 接口
相对于命令行接口,Java接口更加灵活,更强大。但用起来不是很方便,一般可以在 MR 或者 spark 任务中使用 Java 接口读取 HDFS 上的数据。本章仅举一个读取 HDFS 文件数据的例子介绍一下 Java 接口的使用方式,主要使用 FileSystem api 来实现,更具体和更多的使用方法读者可以自行查阅。
package com.cnblogs.duma.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
public class FileSystemEx {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
// uri 便是 core-site.xml 文件中 fs.defaultFS 配置的值
FileSystem fs = FileSystem.get(URI.create("hdfs://hadoop0:9000"), conf);
InputStream in = null;
try {
// 指定打开的文件
in = fs.open(new Path("/hadoop-ex/wordcount/input/words"));
// 将输入流拷贝到标准输出流
IOUtils.copyBytes(in, System.out, 4096, false);
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭输入流
IOUtils.closeStream(in);
}
}
}
关于“HDFS分布式文件系统如何设计”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
--结束END--
本文标题: HDFS分布式文件系统如何设计
本文链接: https://www.lsjlt.com/news/230552.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0