在一个月黑风高的夜晚,突然收到现网生产环境kafka消息积压的告警,梦中惊醒啊,马上起来排查日志。问题现象:消费请求卡死在查找CoordinatorCoordinator为何物?Coordinator用于管理Consumer G
在一个月黑风高的夜晚,突然收到现网生产环境kafka消息积压的告警,梦中惊醒啊,马上起来排查日志。
Coordinator为何物?Coordinator用于管理Consumer Group中各个成员,负责消费offset位移管理和Consumer Rebalance。Consumer在消费时必须先确认Consumer Group对应的Coordinator,随后才能join Group,获取对应的topic partition进行消费。
那如何确定Consumer Group的Coordinator呢?分两步走:
一个Consumer Group对应一个__consumers_offsets的分区,首先先计算Consumer Group对应的__consumers_offsets的分区,计算公式如下:
__consumers_offsets partition# = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount,其中groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定。
1中计算的该partition的leader所在的broker就是被选定的Coordinator。
Coordinator节点找到了,现在看看Coordinator是否有问题:

不出所料,Coordinator对应分区Leader为-1,消费端程序会一直等待,直到Leader选出来为止,这就直接导致了消费卡死。
为啥Leader无法选举?Leader选举是由Controller负责的。Controller节点负责管理整个集群中分区和副本的状态,比如partition的Leader选举,topic创建,副本分配,partition和replica扩容等。现在我们看看Controller的日志:
1. 6月10日15:48:30,006 秒Broker 1成为controller

此时感知的节点为1和2,节点3 在zk读不出来:

31秒847的时候把__consumer_offsets的分区3的Leader选为1,ISR为[1,2],leader_epoch为14:

再过1秒后才感知到Controller发生变化,自身清退

2. Broker 2在其后几百毫秒后(15:48:30,936)也成为Controller

但是Broker2 是感知到Broker 3节点是活的,日志如下:

注意这个时间点,Broker1还没在zk把__consumer_offsets的分区3 的Leader从节点3改为1,这样Broker 2还认为Broker 3是Leader,并且Broker 3在它认为是活的,所以不需要重新选举Leader。这样一直保持了相当长的时间,即使Broker 1已经把这个分区的Leader切换了,它也不感知。
3. Broker 2在12号的21:43:19又感知Broker 1网络中断,并处理节点失败事件:

因为Broker 2内存中认为__consumer_offsets分区3的Leader是broker 3,所以不会触发分区3的Leader切换。
Broker 2但是在处理失败的节点Broker 1时,会把副本从ISR列表中去掉,去掉前会读一次zk,代码如下:
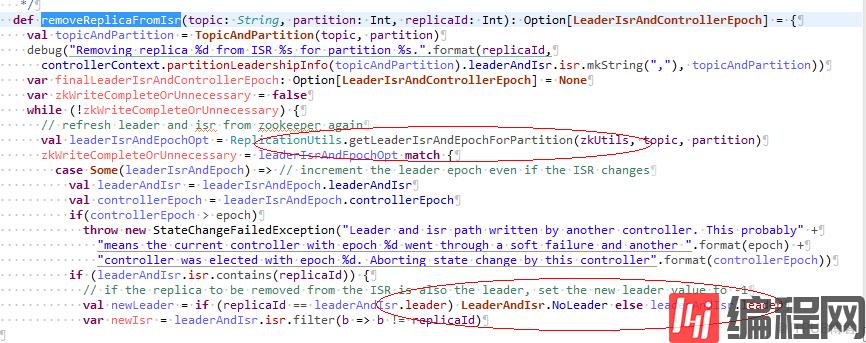
但是发现zk中分区3的Leader已经变为1,ISR列表为[1,2],当要去掉的节点1就是Leader的时候,Leader就会变为-1, ISR只有[2],从日志也可以看到:

这样分区3 的Leader一直为-1,直到有新的事件触发节点2重新选举才能恢复(例如重启某个节点)。
出现网络异常后,由于新老controller之间感知的可用节点不同,导致新controller对某个分区的Leader在内存中的信息与zk记录元数据的信息不一致,导致controller选举流程出现错误,选不出Leader。 需要有新的选举事件才能触发Leader选出来,例如重启。
这是一个典型的由于网络异常导致脑裂,进而出现了多个Controller,菊厂分布式消息服务Kafka(https://www.huaweicloud.com/product/dmskafka.html)经过电信级的可靠性验证,已经完美解决了这些问题 。
--结束END--
本文标题: Kafka无法消费?!我的分布式消息服务Kafka却稳如泰山!
本文链接: https://www.lsjlt.com/news/239974.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答
一口价域名售卖能注册吗?域名是网站的标识,简短且易于记忆,为在线用户提供了访问我们网站的简单路径。一口价是在域名交易中一种常见的模式,而这种通常是针对已经被注册的域名转售给其他人的一种方式。
一口价域名买卖的过程通常包括以下几个步骤:
1.寻找:买家需要在域名售卖平台上找到心仪的一口价域名。平台通常会为每个可售的域名提供详细的描述,包括价格、年龄、流
443px" 443px) https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294.jpg https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294-768x413.jpg 域名售卖 域名一口价售卖 游戏音频 赋值/切片 框架优势 评估指南 项目规模

官方手机版

微信公众号

商务合作




0