这篇文章将为大家详细讲解有关如何使用hadoop来提取文件中的指定内容,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。一、需求把以下txt中含“baidu”字符串的链接输出到一个文件,否则输出到另外一个文件
这篇文章将为大家详细讲解有关如何使用hadoop来提取文件中的指定内容,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
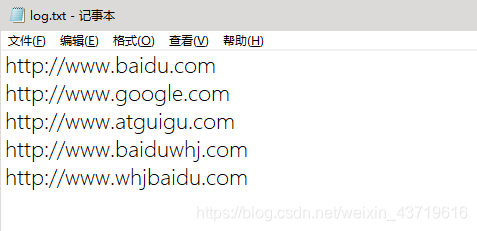
把以下txt中含“baidu”字符串的链接输出到一个文件,否则输出到另外一个文件。
1.LogMapper.java
package com.whj.mapReduce.outputfORMat;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class LogMapper extends Mapper<LongWritable,Text,Text,NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 不做任何处理 context.write(value,NullWritable.get()); }}2.LogReducer.java
package com.whj.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class LogReducer extends Reducer<Text,NullWritable,Text,NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { for (NullWritable value : values) { context.write(key,NullWritable.get()); } }}3.LogOutputFormat.java
package com.whj.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.RecordWriter;import org.apache.hadoop.mapreduce.TaskAttemptContext;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LoGoutputFormat extends FileOutputFormat<Text,NullWritable> { @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { LogRecordWriter lrw = new LogRecordWriter(job); return lrw; }}4.LogRecordWriter.java
package com.whj.mapreduce.outputformat;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IOUtils;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.RecordWriter;import org.apache.hadoop.mapreduce.TaskAttemptContext;import java.io.IOException;public class LogRecordWriter extends RecordWriter<Text,NullWritable> { private FSDataOutputStream baiduOut;//ctrl+alt+f private FSDataOutputStream otherOut; public LogRecordWriter(TaskAttemptContext job) throws IOException {//创建两条流 FileSystem fs = FileSystem.get(job.getConfiguration()); baiduOut = fs.create(new Path("D:\\temp\\outputformat.log")); otherOut = fs.create(new Path("D:\\temp\\other.log")); } @Override public void write(Text key, NullWritable nullWritable) throws IOException, InterruptedException {// 具体写 String log = key.toString(); if(log.contains("baidu")){ baiduOut.writeBytes(log+"\n"); }else{ otherOut.writeBytes(log+"\n"); } } @Override public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {//关流 IOUtils.closeStream(baiduOut); IOUtils.closeStream(otherOut); }}5.LogDriver.java
package com.whj.mapreduce.outputformat;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class LogDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setjarByClass(LogDriver.class); job.setMapperClass(LogMapper.class); job.setReducerClass(LogReducer.class); job.setMapOutpuTKEyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //设置自定义的 outputformat job.setOutputFormatClass(LogOutputFormat.class); FileInputFormat.setInputPaths(job, new Path("D:\\input")); // 虽 然 我 们 自 定 义 了 outputformat , 但 是 因 为 我 们 的 outputformat 继承自fileoutputformat //而 fileoutputformat 要输出一个_SUCCESS 文件,所以在这还得指定一个输出目录 FileOutputFormat.setOutputPath(job, new Path("D:\\temp\\logoutput")); boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }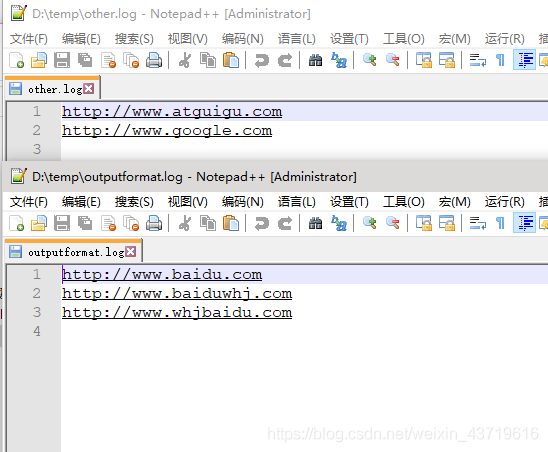
关于“如何使用hadoop来提取文件中的指定内容”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
--结束END--
本文标题: 如何使用hadoop来提取文件中的指定内容
本文链接: https://www.lsjlt.com/news/278162.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-09
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0