这篇文章给大家分享的是有关怎么创建sparkSession和sparksql的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。一、概述spark 有三大引擎,spark core、sparkSQL、sparkStre
这篇文章给大家分享的是有关怎么创建sparkSession和sparksql的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
spark 有三大引擎,spark core、sparkSQL、sparkStreaming,
spark core 的关键抽象是 SparkContext、RDD;
SparkSQL 的关键抽象是 SparkSession、DataFrame;
sparkStreaming 的关键抽象是 StreaminGContext、DStream
SparkSession 是 spark2.0 引入的概念,主要用在 sparkSQL 中,当然也可以用在其他场合,他可以代替 SparkContext;
SparkSession 其实是封装了 SQLContext 和 HiveContext
(1) 在Spark1.6 中我们使用的叫Hive on spark,主要是依赖hive生成spark程序,有两个核心组件SQLcontext和HiveContext。
这是Spark 1.x 版本的语法
//set up the spark configuration and create contexts val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local") // your handle to SparkContext to access other context like SQLContext val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value") val sqlContext = new org.apache.spark.sql.SQLContext(sc)(2)Spark2.0中我们使用的就是sparkSQL,是后继的全新产品,解除了对Hive的依赖。
从Spark2.0以上的版本开始,spark是使用全新的SparkSession接口代替Spark1.6 中的SQLcontext和HiveContext 来实现对数据的加载、转换、处理等工作,并且实现了SQLcontext和HiveContext的所有功能。
在新版本中并不需要之前那么繁琐的创建很多对象,只需要创建一个SparkSession对象即可。SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并支持把DataFrame转换成SQLContext自身中的表。然后使用SQL语句来操作数据,也提供了HiveQL以及其他依赖于Hive的功能支持。
SparkSession 是 Spark SQL 的入口。使用 Dataset 或者 Dataframe 编写 Spark SQL 应用的时候,第一个要创建的对象就是 SparkSession。Builder 是 SparkSession 的构造器。 通过 Builder, 可以添加各种配置,并通过 stop 函数来停止 SparkSession。
Builder 的方法如下:
import org.apache.spark.sql.SparkSessionval spark: SparkSession = SparkSession.builder .appName("My Spark Application") //设置 application 的名字 .master("local[*]") .enableHiveSupport() //增加支持 hive Support .config("spark.sql.warehouse.dir", "target/spark-warehouse") //设置各种配置 .getOrCreate //获取或者新建一个 sparkSession(1)设置参数
创建SparkSession之后可以通过 spark.conf.set 来设置运行参数
//配置设置 spark.conf.set("spark.sql.shuffle.partitions", 6) spark.conf.set("spark.executor.memory", "2g") //获取配置,可以使用Scala的迭代器来读取configMap中的数据。 val configMap:Map[String, String] = spark.conf.getAll()(2)读取元数据
如果需要读取元数据(catalog),可以通过SparkSession来获取。
spark.catalog.listTables.show(false) spark.catalog.listDatabases.show(false)这里返回的都是Dataset,所以可以根据需要再使用Dataset api来读取
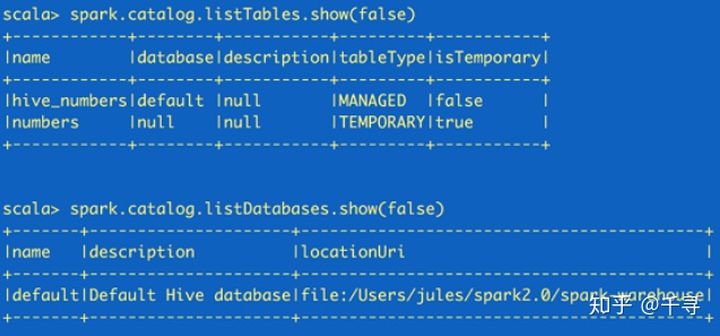
catalog 和 schema 是两个不同的概念
Catalog是目录的意思,从数据库方向说,相当于就是所有数据库的集合;
Schema是模式的意思, 从数据库方向说, 类似Catelog下的某一个数据库;
(3)创建Dataset和Dataframe
通过SparkSession来创建Dataset和Dataframe有多种方法。
通过range()方法来创建dataset
通过createDataFrame()来创建dataframe。
// create a Dataset using spark.range starting from 5 to 100,// with increments of 5val numDS = spark.range(5, 100, 5)//创建dataset // reverse the order and display first 5 itemsnumDS.orderBy(desc("id")).show(5) //compute descriptive stats and display themnumDs.describe().show() // create a DataFrame using spark.createDataFrame from a List or Seqval langPercentDF = spark.createDataFrame( List( ("Scala", 35), ("python", 30), ("R", 15), ("Java", 20)) )//创建dataframe //rename the columnsval lpdf = langPercentDF.withColumnRenamed("_1", "language"). withColumnRenamed("_2", "percent") //order the DataFrame in descending order of percentagelpDF.orderBy(desc("percent")).show(false)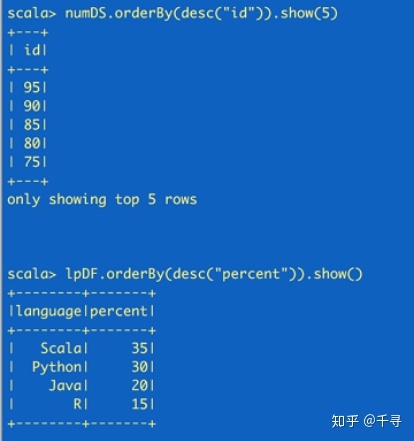
(4)读取数据
可以用SparkSession读取JSON、CSV、TXT 和 parquet表。
import spark.implicits //使RDD转化为DataFrame以及后续SQL操作//读取jsON文件,生成DataFrameval jsonFile = args(0)val zipsDF = spark.read.json(jsonFile)(5)使用SparkSQL
借助SparkSession用户可以像SQLContext一样使用Spark SQL的全部功能。
zipsDF.createOrReplaceTempView("zips_table")//对上面的dataframe创建一个表zipsDF.cache()//缓存表 val resultsDF = spark.sql("SELECT city, pop, state, zip FROM zips_table") //对表调用SQL语句resultsDF.show(10)//展示结果(6)存储/读取Hive表
下面的代码演示了通过SparkSession来创建Hive表并进行查询的方法。
//drop the table if exists to get around existing table error spark.sql("DROP TABLE IF EXISTS zips_hive_table") //save as a hive table spark.table("zips_table").write.saveAsTable("zips_hive_table") //make a similar query against the hive table val resultsHiveDF = spark.sql("SELECT city, pop, state, zip FROM zips_hive_table WHERE pop > 40000") resultsHiveDF.show(10)它是 sparkSQL 的入口点,sparkSQL 的应用必须创建一个 SQLContext 或者 HiveContext 的类实例
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSession, SQLContext, HiveContext conf = SparkConf().setAppName('test').setMaster('yarn')sc = SparkContext(conf=conf) sqlc = SQLContext(sc)print(dir(sqlc))# 'cacheTable', 'clearCache', 'createDataFrame', 'createExternalTable', 'dropTempTable', 'getConf', 'getOrCreate', 'newSession', 'range', 'read', 'readStream',# 'reGISterDataFrameAsTable', 'registerFunction', 'registerJavaFunction', 'setConf', 'sparkSession', 'sql', 'streams', 'table', 'tableNames', 'tables', 'udf', 'uncacheTable' ### sqlcontext 读取数据也自动生成 dfdata = sqlc.read.text('/usr/yanshw/test.txt')print(type(data))它是 sparkSQL 的另一个入口点,它继承自 SQLContext,用于处理 hive 中的数据
HiveContext 对 SQLContext 进行了扩展,功能要强大的多
它可以执行 HiveSQL 和 SQL 查询
它可以操作 hive 数据,并且可以访问 HiveUDF
它不一定需要 hive,在没有 hive 环境时也可以使用 HiveContext
注意,如果要处理 hive 数据,需要把 hive 的 hive-site.xml 文件放到 spark/conf 下,HiveContext 将从 hive-site.xml 中获取 hive 配置信息;
如果 HiveContext 没有找到 hive-site.xml,他会在当前目录下创建 spark-warehouse 和 metastore_db 两个文件夹
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSession, SQLContext, HiveContext conf = SparkConf().setAppName('test').setMaster('yarn')sc = SparkContext(conf=conf)## 需要把 hive/conf/hive-site.xml 复制到 spark/conf 下hivec = HiveContext(sc)print(dir(hivec))# 'cacheTable', 'clearCache', 'createDataFrame', 'createExternalTable', 'dropTempTable', 'getConf', 'getOrCreate', 'newSession', 'range', 'read', 'readStream','refreshTable',# 'registerDataFrameAsTable', 'registerFunction', 'registerJavaFunction', 'setConf', 'sparkSession', 'sql', 'streams', 'table', 'tableNames', 'tables', 'udf', 'uncacheTable' data = hivec.sql('''select * from hive1101.person limit 2''')print(type(data))SparkSession 创建
from pyspark.sql import SparkSession ### method 1sess = SparkSession.builder \ .appName("aaa") \ .config("spark.driver.extraClassPath", sparkClassPath) \ .master("local") \ .enableHiveSupport() \ # sparkSQL 连接 hive 时需要这句 .getOrCreate() # builder 方式必须有这句 ### method 2conf = SparkConf().setAppName('myapp1').setMaster('local[4]') # 设定 appname 和 mastersess = SparkSession.builder.config(conf=conf).getOrCreate() # builder 方式必须有这句 ### method 3from pyspark import SparkContext, SparkConfconf = SparkConf().setAppName('myapp1').setMaster('local[4]') # 设定 appname 和 mastersc = SparkContext(conf=conf)sess = SparkSession(sc)1)文件数据源
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSession, SQLContext, HiveContext conf = SparkConf().setAppName('test').setMaster('yarn')sc = SparkContext(conf=conf) #### 替代了 SQLContext 和 HiveContext,其实只是简单的封装,提供了统一的接口spark = SparkSession(sc)print(dir(spark))# 很多属性,我把私有属性删了# 'Builder','builder', 'catalog', 'conf', 'createDataFrame', 'newSession', 'range', 'read', 'readStream','sparkContext', 'sql', 'stop', 'streams', 'table', 'udf', 'version' ### sess 读取数据自动生成 dfdata = spark.read.text('/usr/yanshw/test.txt') #read 可读类型 [ 'csv', 'fORMat', 'jdbc', 'json', 'load', 'option', 'options', 'orc', 'parquet', 'schema', 'table', 'text']print(type(data)) # <class 'pyspark.sql.dataframe.DataFrame'>2) Hive 数据源
## 也需要把 hive/conf/hive-site.xml 复制到 spark/conf 下spark = SparkSession.builder.appName('test').master('yarn').enableHiveSupport().getOrCreate() hive_data = spark.sql('select * from hive1101.person limit 2')print(hive_data) # DataFrame[name: string, idcard: string]SparkSession vs SparkContext
SparkSession 是 spark2.x 引入的新概念,SparkSession 为用户提供统一的切入点,字面理解是创建会话,或者连接 spark
在 spark1.x 中,SparkContext 是 spark 的主要切入点,由于 RDD 作为主要的 API,我们通过 SparkContext 来创建和操作 RDD,
SparkContext 的问题在于:
不同的应用中,需要使用不同的 context,在 Streaming 中需要使用 StreamingContext,在 sql 中需要使用 sqlContext,在 hive 中需要使用 hiveContext,比较麻烦
随着 DataSet 和 DataFrame API 逐渐成为标准 API,需要为他们创建接入点,即 SparkSession
SparkSession 实际上封装了 SparkContext,另外也封装了 SparkConf、sqlContext,随着版本增加,可能更多,
所以我们尽量使用 SparkSession ,如果发现有些 API 不在 SparkSession 中,也可以通过 SparkSession 拿到 SparkContext 和其他 Context 等
在 shell 操作中,原生创建了 SparkSession,故无需再创建,创建了也不会起作用
在 shell 中,SparkContext 叫 sc,SparkSession 叫 spark。
感谢各位的阅读!关于“怎么创建SparkSession和sparkSQL”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
--结束END--
本文标题: 怎么创建SparkSession和sparkSQL
本文链接: https://www.lsjlt.com/news/300126.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0