Python 官方文档:入门教程 => 点击学习
这篇文章主要讲解了“如何使用python爬虫抓取弹幕”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何使用python爬虫抓取弹幕”吧!一、爬虫是什么?百度百科这样说:自动获取网页内容的程序
这篇文章主要讲解了“如何使用python爬虫抓取弹幕”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何使用python爬虫抓取弹幕”吧!
百度百科这样说:自动获取网页内容的程序。在我理解看来,爬虫就是~~“在网络上爬来爬去的…”住口!~~
那么接下来就让我们看看如何养搬运B站弹幕的“虫”吧
首先,得知道爬取的网站url是什么。对于B站弹幕而言,弹幕所在位置是有固定格式的:
Http://comment.bilibili.com/+cid+.xml
ok,那么问题来了,cid是什么呢?不用管是什么,我告诉你怎么获取。
打开视频后点击F12,切换到“网络”,在筛选器处填入“cid”进行筛选。

点击筛选出的网络信息,在右端Payload处找到cid
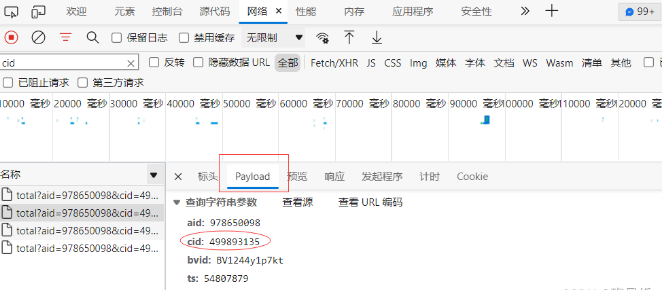
到此,我们就知道了何同学视频弹幕的网络链接:
http://comment.bilibili.com/499893135.xml
接着就是发送网络请求,获取网络页面资源。Python有很多发送网络请求的库。比如:
urllib库
requests库
我们用reaquests库演示
发送请求的代码如下
(示例):
#【何同学】我用108天开了个灯......视频的cid:499893135#弹幕所在地url = "http://comment.bilibili.com/499893135.xml"#发送请求req = requests.get(url = url)#获取内容响应的内容html_byte = req.content#将byte转为strhtml_str = str(html_byte,"utf-8")还有个值得提一下的地方是,发送请求的请求头可以加上,伪装自己是浏览器访问。可以通过header参数,加上user-agent,获取方式如下:
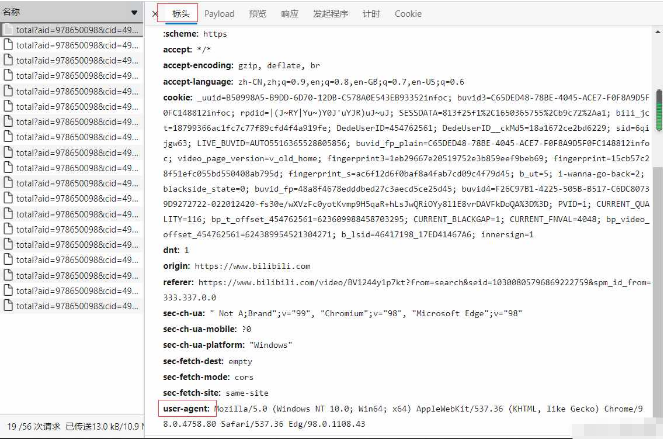
那么,代码就是下面这样了:
#假装自己是浏览器header ={ 'User-Agent':'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'}#【何同学】我用108天开了个灯......视频的cid:499893135#弹幕所在地url = "http://comment.bilibili.com/499893135.xml"#发送请求req = requests.get(url = url, headers=header)#获取内容响应的内容html_byte = req.content#将byte转为strhtml_str = str(html_byte,"utf-8")html_str是html文件的格式,我们需要对其进行处理,来获取我们想要的信息。这个时候,BeautifulSoup库就要闪亮登场了,我们用它来处理得到的html文件
代码如下(示例):
#解析 soup = BeautifulSoup(html,'html.parser') #找到html文件里的<d>标签 results = soup.find_all('d') #把标签里的文本提取出来 contents = [x.text for x in results] #存为字典 dic ={"contents" : contents}contents就是弹幕字符串列表了,存成字典是为了下一步…
把弹幕信息存储成excel,也有好多库可以用。比如:
xlwt库
我们就用pandas库把
代码如下(示例):
把用第二步得到的字典创建dataFrame,然后用pandas库的一个api存下就行了
#用字典创建了一个电子表格df = pd.DataFrame(dic)df["contents"].to_excel('htx.xlsx')import requestsfrom bs4 import BeautifulSoupimport pandas as pd def main(): html = askUrl() dic =analyse(html) writeExcel(dic) def askUrl(): #假装自己是浏览器 header ={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43' } #【何同学】我用108天开了个灯......视频的cid:499893135 #弹幕所在地 url = "http://comment.bilibili.com/499893135.xml" req = requests.get(url = url, headers=header) html_byte = req.content#字节 html_str = str(html_byte,"utf-8") return html_str def analyse(html): soup = BeautifulSoup(html,'html.parser') results = soup.find_all('d') #x.text表示要放到contents中的值 contents = [x.text for x in results] #保存结果 dic ={"contents" : contents} return dic def writeExcel(dic): #用字典创建了一个电子表格 df = pd.DataFrame(dic) df["contents"].to_excel('htx.xlsx') if __name__ == '__main__': main()感谢各位的阅读,以上就是“如何使用python爬虫抓取弹幕”的内容了,经过本文的学习后,相信大家对如何使用python爬虫抓取弹幕这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: 如何使用python爬虫抓取弹幕
本文链接: https://www.lsjlt.com/news/322022.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0