这篇“怎么让spark sql写mysql时支持update操作”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看
这篇“怎么让spark sql写mysql时支持update操作”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“怎么让spark sql写Mysql时支持update操作”文章吧。
除了支持:Append、Overwrite、ErrorIfExists、Ignore;还要在支持update操作
spark提供了一个枚举类,用来支撑对接数据源的操作模式
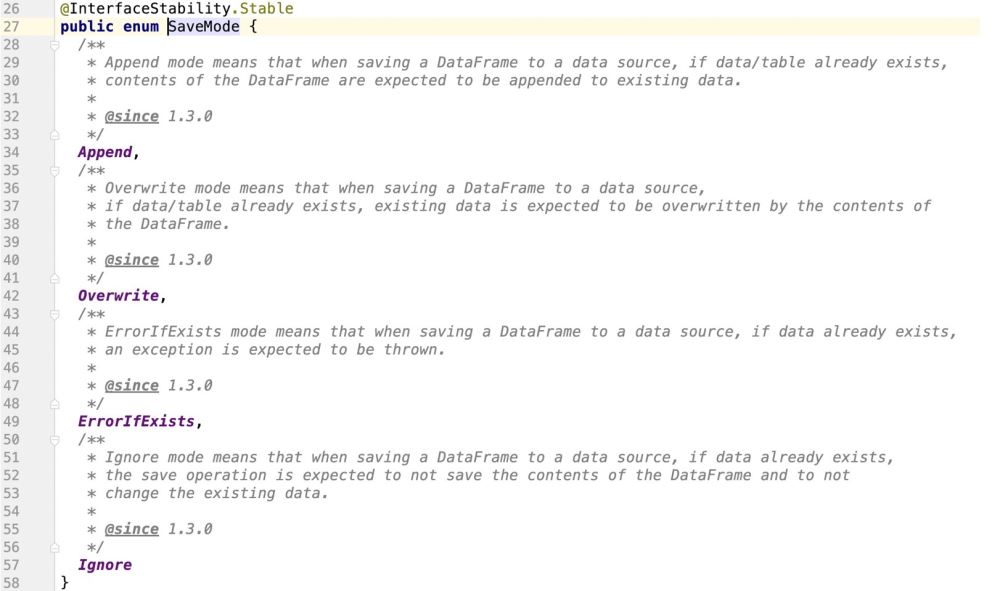
通过源码查看,很明显,spark是不支持update操作的
关键的知识点就是:
我们正常在sparkSQL写数据到mysql的时候:
大概的api是:
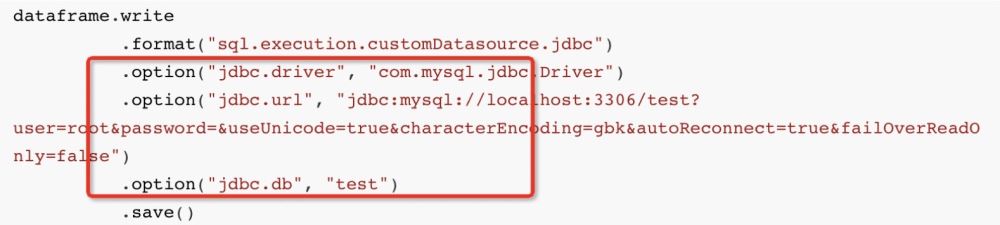
dataframe.write .fORMat("sql.execution.customDatasource.jdbc") .option("jdbc.driver", "com.mysql.jdbc.Driver") .option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&passWord=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false") .option("jdbc.db", "test") .save()那么在底层中,spark会通过JDBC方言JdbcDialect , 将我们要插入的数据翻译成:
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)那么通过方言解析出的sql语句就通过PrepareStatement的executeBatch(),将sql语句提交给mysql,然后数据插入;
那么上面的sql语句很明显,完全就是插入代码,并没有我们期望的 update操作,类似:
UPDATE table_name SET field1=new-value1, field2=new-value2但是mysql独家支持这样的sql语句:
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';大概的意思就是,如果数据不存在则插入,如果数据存在,则 执行update操作;
因此,我们的切入点就是,让sparkSQL内部对接JdbcDialect的时候,能够生成这种sql:
INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';首先是:
dataframe.write调用write方法就是为了返回一个类:DataFrameWriter
主要是因为DataFrameWriter是sparksql对接外部数据源写入的入口携带类,下面这些内容是给DataFrameWriter注册的携带信息
然后在出发save()操作后,就开始将数据写入;
接下来看save()源码:
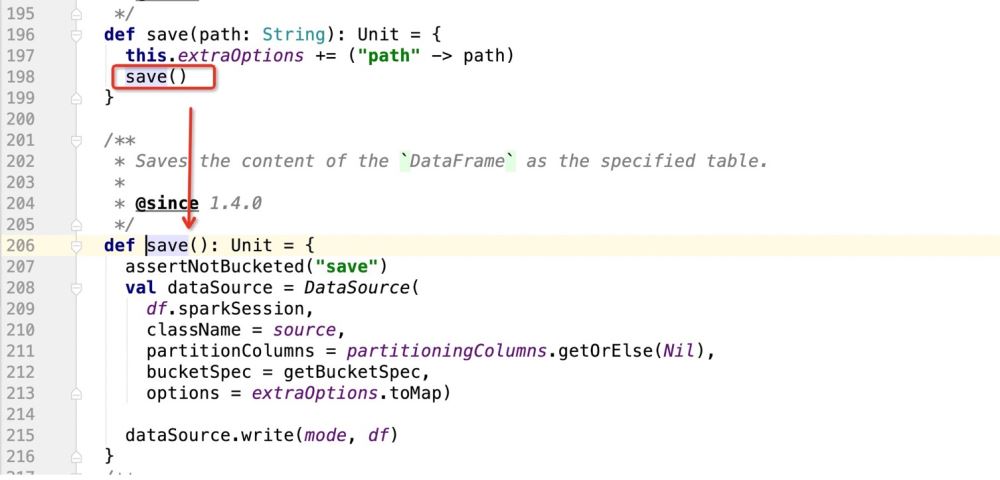
在上面的源码里面主要是注册DataSource实例,然后使用DataSource的write方法进行数据写入
实例化DataSource的时候:
def save(): Unit = { assertNotBucketed("save") val dataSource = DataSource( df.sparkSession, className = source,//自定义数据源的包路径 partitionColumns = partitioninGColumns.getOrElse(Nil),//分区字段 bucketSpec = getBucketSpec,//分桶(用于Hive) options = extraoptions.toMap)//传入的注册信息 //mode:插入数据方式SaveMode , df:要插入的数据 dataSource.write(mode, df) }然后就是dataSource.write(mode, df)的细节,整段的逻辑就是:
根据providingClass.newInstance()去做模式匹配,然后匹配到哪里,就执行哪里的代码;
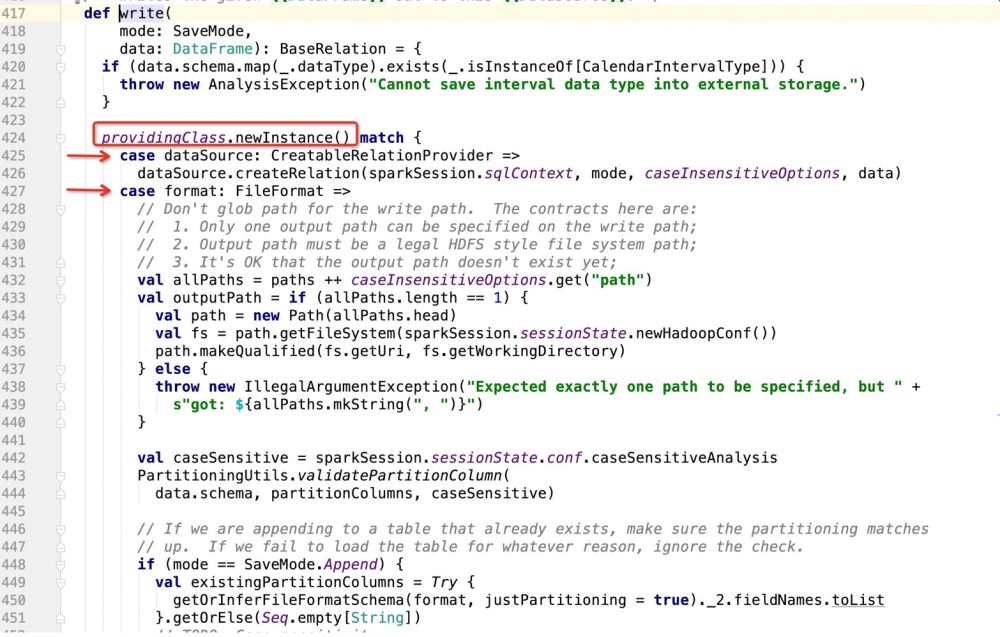
然后看下providingClass是什么:
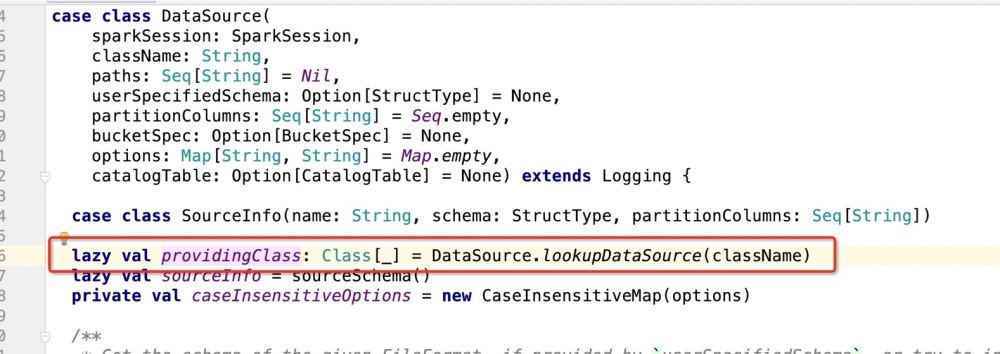
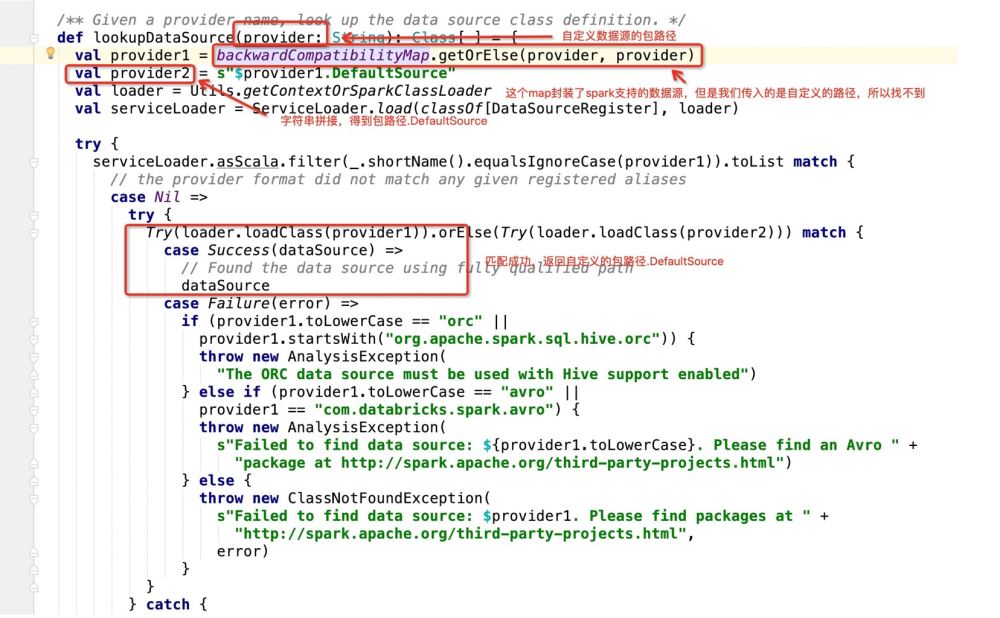
拿到包路径.DefaultSource之后,程序进入:
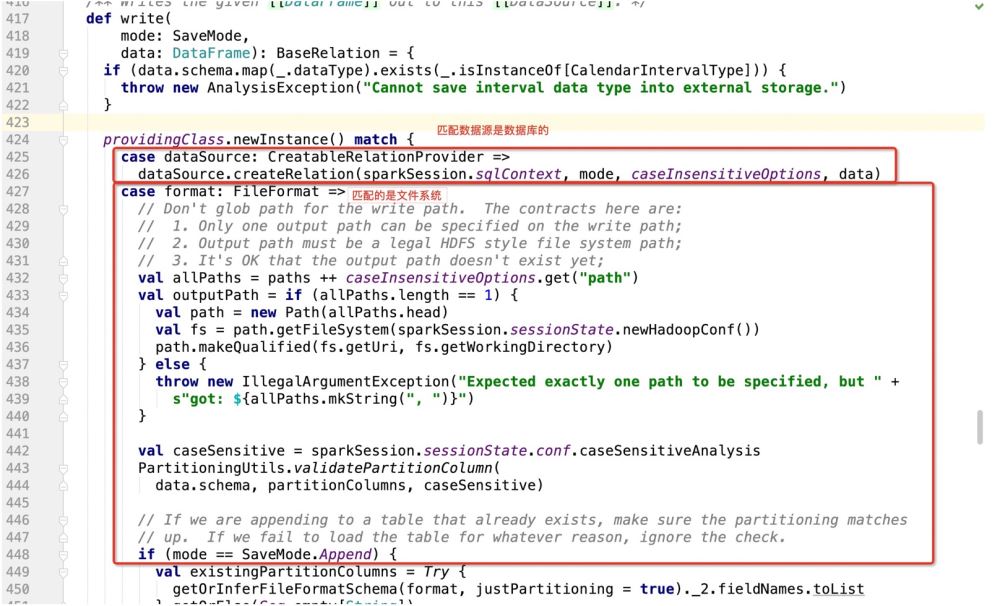
那么如果是数据库作为写入目标的话,就会走:dataSource.createRelation,直接跟进源码:
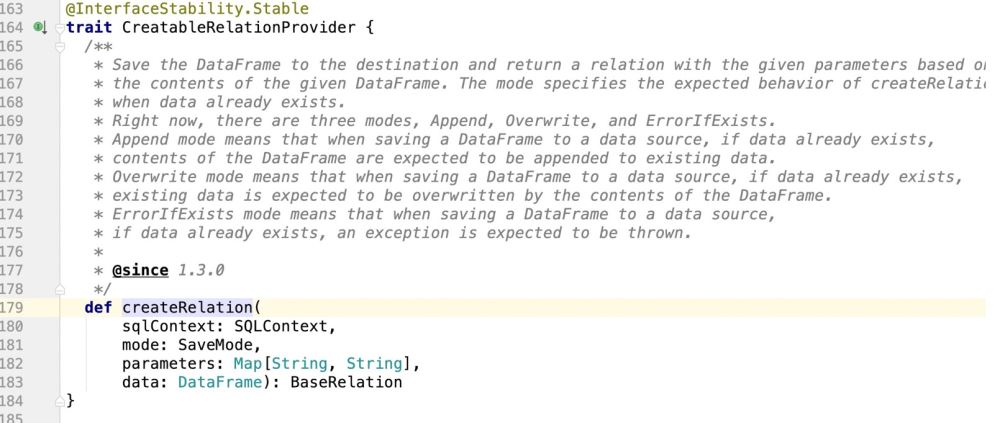
很明显是个特质,因此哪里实现了特质,程序就会走到哪里了;
实现这个特质的地方就是:包路径.DefaultSource , 然后就在这里面去实现数据的插入和update的支持操作;
根据代码的流程,最终sparkSQL 将数据写入mysql的操作,会进入:包路径.DefaultSource这个类里面;
也就是说,在这个类里面既要支持spark的正常插入操作(SaveMode),还要在支持update;
如果让sparksql支持update操作,最关键的就是做一个判断,比如:
if(isUpdate){ sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';}else{ insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)}但是,在spark生产sql语句的源码中,是这样写的:
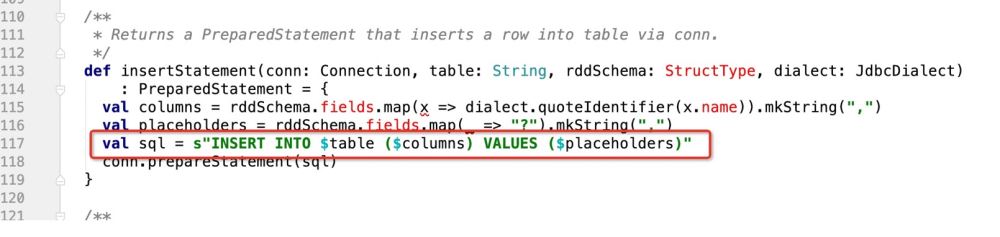
没有任何的判断逻辑,就是最后生成一个:
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)所以首要的任务就是 ,怎么能让当前代码支持:ON DUPLICATE KEY UPDATE
可以做个大胆的设计,就是在insertStatement这个方法中做个如下的判断
def insertStatement(conn: Connection, savemode:CustomSaveMode , table: String, rddSchema: StructType, dialect: JdbcDialect) : PreparedStatement = { val columns = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",") val placeholders = rddSchema.fields.map(_ => "?").mkString(",") if(savemode == CustomSaveMode.update){ //TODO 如果是update,就组装成ON DUPLICATE KEY UPDATE的模式处理 s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE $duplicateSetting" }esle{ val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders)" conn.prepareStatement(sql) } }这样,在用户传递进来的savemode模式,我们进行校验,如果是update操作,就返回对应的sql语句!
所以按照上面的逻辑,我们代码这样写:
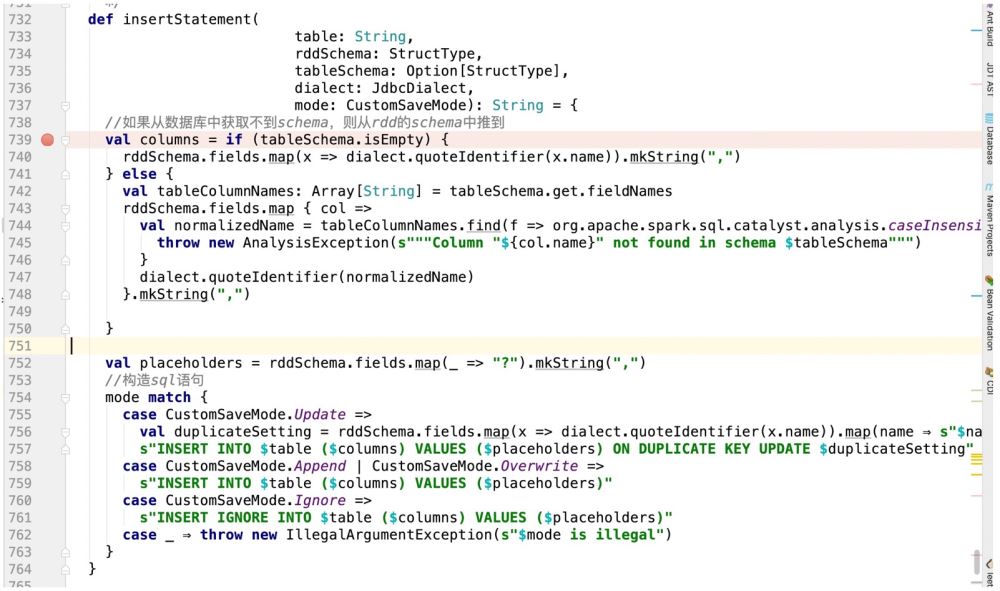
这样我们就拿到了对应的sql语句;
但是只有这个sql语句还是不行的,因为在spark中会执行jdbc的prepareStatement操作,这里面会涉及到游标。
即jdbc在遍历这个sql的时候,源码会这样做:
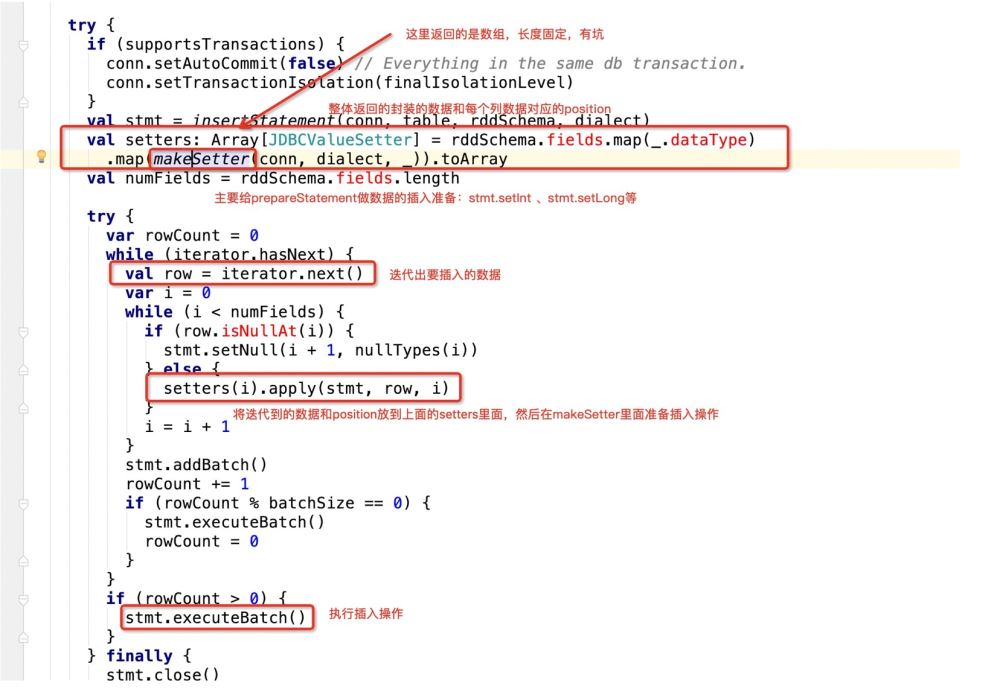
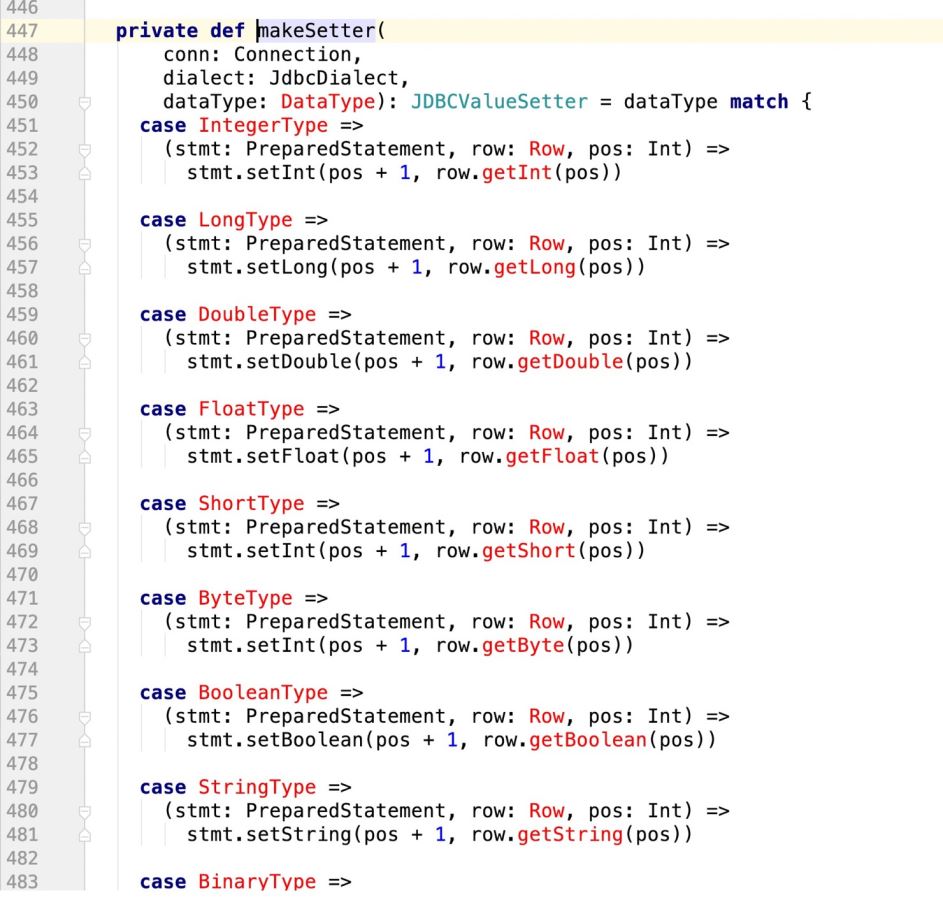
看下makeSetter:

所谓有坑就是:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType) .map(makeSetter(conn, dialect, _)).toArray但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
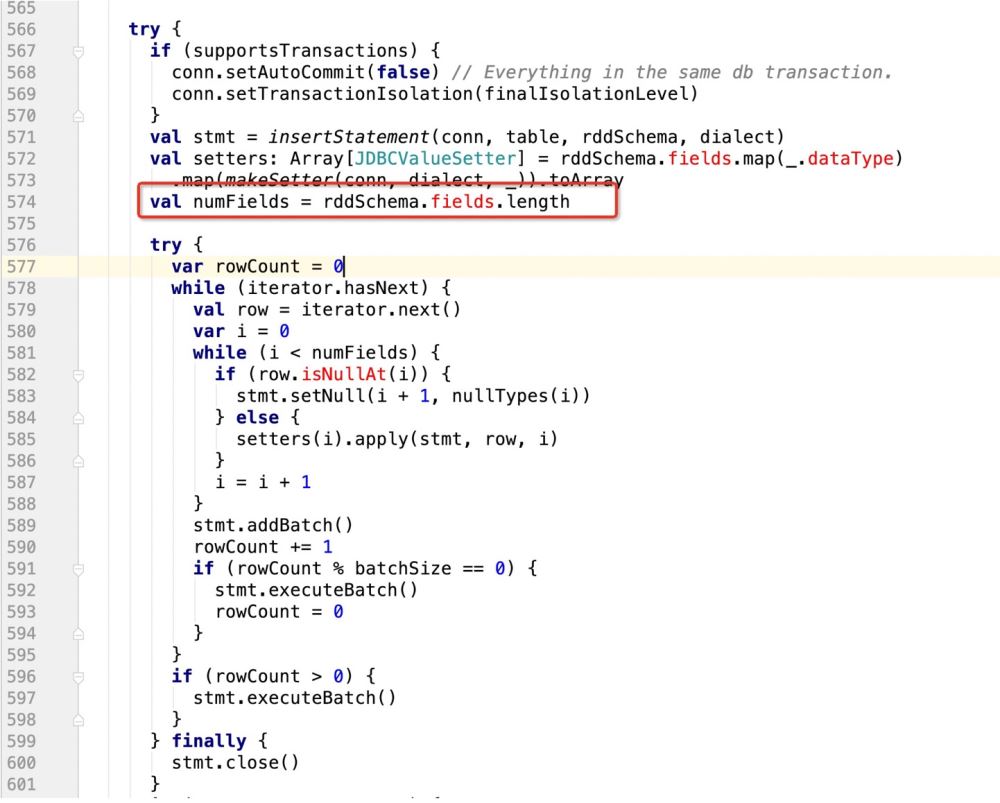
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
if(isupdate){ val numFields = rddSchema.fields.length * 2}else{ val numFields = rddSchema.fields.length}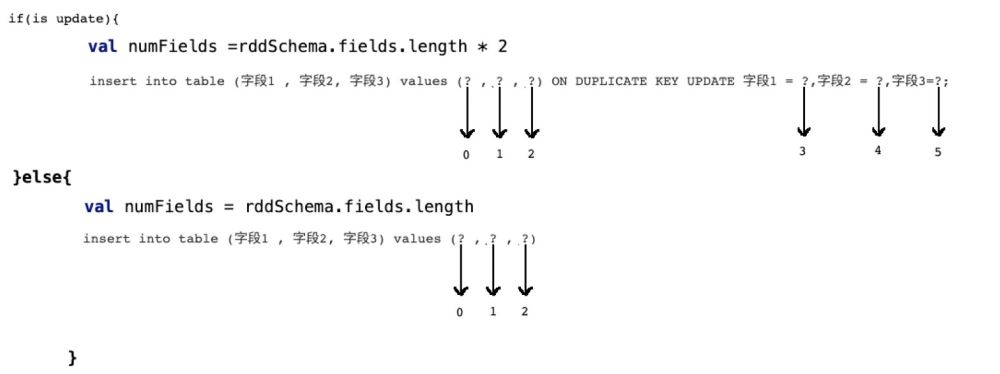
row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
因此,代码改造前样子:
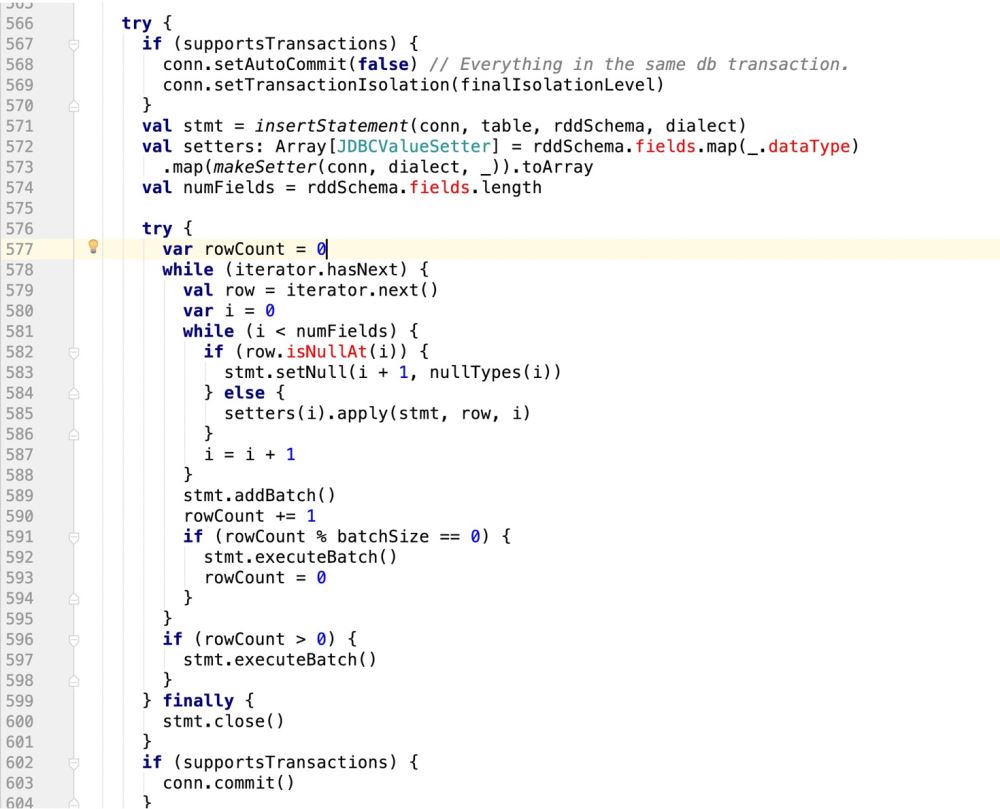
改造后的样子:
try { if (supportsTransactions) { conn.setAutoCommit(false) // Everything in the same db transaction. conn.setTransactionIsolation(finalIsolationLevel) }// val stmt = insertStatement(conn, table, rddSchema, dialect) //此处采用最新自己的sql语句,封装成prepareStatement val stmt = conn.prepareStatement(sqlStmt) println(sqlStmt) //makeSetter也要适配update操作,即游标问题 val isUpdate = saveMode == CustomSaveMode.Update val setters: Array[JDBCValueSetter] = isUpdate match { case true => val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType) .map(makeSetter(conn, dialect, _)).toArray Array.fill(2)(setters).flatten case _ => rddSchema.fields.map(_.dataType) val numFieldsLength = rddSchema.fields.length val numFields = isUpdate match{ case true => numFieldsLength *2 case _ => numFieldsLength val cursorBegin = numFields / 2 try { var rowCount = 0 while (iterator.hasNext) { val row = iterator.next() var i = 0 while (i < numFields) { if(isUpdate){ //需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE i < cursorBegin match{ //说明还没走到update阶段 case true => //row.isNullAt 判空,则设置空值 if (row.isNullAt(i)) { stmt.setNull(i + 1, nullTypes(i)) } else { setters(i).apply(stmt, row, i, 0) } //说明走到了update阶段 case false => if (row.isNullAt(i - cursorBegin)) { //pos - offset stmt.setNull(i + 1, nullTypes(i - cursorBegin)) setters(i).apply(stmt, row, i, cursorBegin) } }else{ if (row.isNullAt(i)) { stmt.setNull(i + 1, nullTypes(i)) } else { setters(i).apply(stmt, row, i ,0) } //滚动游标 i = i + 1 } stmt.addBatch() rowCount += 1 if (rowCount % batchSize == 0) { stmt.executeBatch() rowCount = 0 } if (rowCount > 0) { stmt.executeBatch() } finally { stmt.close() conn.commit() committed = true Iterator.empty } catch { case e: SQLException => val cause = e.getNextException if (cause != null && e.getCause != cause) { if (e.getCause == null) { e.initCause(cause) } else { e.addSuppressed(cause) throw e } finally { if (!committed) { // The stage must fail. We Got here through an exception path, so // let the exception through unless rollback() or close() want to // tell the user about another problem. if (supportsTransactions) { conn.rollback() conn.close() } else { // The stage must succeed. We cannot propagate any exception close() might throw. try { conn.close() } catch { case e: Exception => logWarning("Transaction succeeded, but closing failed", e)// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for // `PreparedStatement`. The last argument `Int` means the index for the value to be set // in the SQL statement and also used for the value in `Row`. //PreparedStatement, Row, position , cursor private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit private def makeSetter( conn: Connection, dialect: JdbcDialect, dataType: DataType): JDBCValueSetter = dataType match { case IntegerType => (stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) => stmt.setInt(pos + 1, row.getInt(pos - cursor)) case LongType => stmt.setLong(pos + 1, row.getLong(pos - cursor)) case DoubleType => stmt.setDouble(pos + 1, row.getDouble(pos - cursor)) case FloatType => stmt.setFloat(pos + 1, row.getFloat(pos - cursor)) case ShortType => stmt.setInt(pos + 1, row.getShort(pos - cursor)) case ByteType => stmt.setInt(pos + 1, row.getByte(pos - cursor)) case BooleanType => stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor)) case StringType =>// println(row.getString(pos)) stmt.setString(pos + 1, row.getString(pos - cursor)) case BinaryType => stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor)) case TimestampType => stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor)) case DateType => stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor)) case t: DecimalType => stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor)) case ArrayType(et, _) => // remove type length parameters from end of type name val typeName = getJdbcType(et, dialect).databaseTypeDefinition .toLowerCase.split("\\(")(0) val array = conn.createArrayOf( typeName, row.getSeq[AnyRef](pos - cursor).toArray) stmt.setArray(pos + 1, array) case _ => (_: PreparedStatement, _: Row, pos: Int,cursor:Int) => throw new IllegalArgumentException( s"Can't translate non-null value for field $pos") }以上就是关于“怎么让spark sql写mysql时支持update操作”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注编程网数据库频道。
--结束END--
本文标题: 怎么让spark sql写mysql时支持update操作
本文链接: https://www.lsjlt.com/news/322675.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0