目录聚簇索引非聚簇索引总结前言: 在 Mysql 默认引擎 InnoDB 中,索引大致可分为两类:聚簇索引和非聚簇索引,它们的区别也是常见的面试题,所以我们今天就来盘它们。 聚簇索引 聚簇索引(Clustered Ind
前言:
在 Mysql 默认引擎 InnoDB 中,索引大致可分为两类:聚簇索引和非聚簇索引,它们的区别也是常见的面试题,所以我们今天就来盘它们。
聚簇索引(Clustered Index)一般指的是主键索引(如果存在主键索引的话),聚簇索引也被称之为聚集索引。
聚簇索引在 InnoDB 中是使用 B+ 树实现的,比如我们创建一张 student 表,它的构建 SQL 如下:
drop table if exists student;
create table student(
id int primary key,
name varchar(16),
class_id int not null,
index (class_id)
)engine=InnoDB;
-- 添加测试数据
insert into student(id,name,class_id) values(1,'张三',100),
(2,'李四',200),(3,'王五',300);以上 student 表中有一个聚簇索引(也就是主键索引)id,和一个非聚簇索引 class_id。
聚簇索引 id 对应的 B+ 树如下图所示:

在聚簇索引的叶子节点直接存储用户信息的内存地址,我们使用内存地址可以直接找到相应的行数据。
非聚簇索引在 InnoDB 引擎中,也叫二级索引,以上面 student 表为例,
在 student 中非聚簇索引 class_id 对应 B+ 树如下图所示:
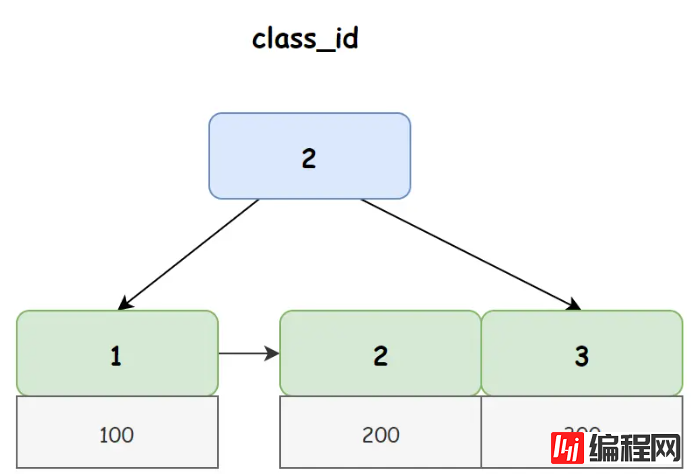
从上图我们可以看出,在非聚簇索引的叶子节点上存储的并不是真正的行数据,而是主键 ID,所以当我们使用非聚簇索引进行查询时,首先会得到一个主键 ID,然后再使用主键 ID 去聚簇索引上找到真正的行数据,我们把这个过程称之为回表查询。
在 mysql 的 InnoDB 引擎中,每个索引都会对应一颗 B+ 树,而聚簇索引和非聚簇索引最大的区别在于叶子节点存储的数据不同,聚簇索引叶子节点存储的是行数据,因此通过聚簇索引可以直接找到真正的行数据;而非聚簇索引叶子节点存储的是主键信息,所以使用非聚簇索引还需要回表查询,因此我们可以得出聚簇索引和非聚簇索引的区别主要有以下几个:
到此这篇关于Mysql聚簇索引和非聚簇索引的区别详情的文章就介绍到这了,更多相关MySQL聚簇索引和非聚簇索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
--结束END--
本文标题: MySQL聚簇索引和非聚簇索引的区别详情
本文链接: https://www.lsjlt.com/news/32933.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-13
2024-05-13
2024-05-13
2024-05-13
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
2024-05-12
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0