本篇内容主要讲解“基于python怎么实现cdn日志文件导入mysql进行分析”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“基于Python怎么实现cdn日志文件导入Mysql进行分析”吧!一、
本篇内容主要讲解“基于python怎么实现cdn日志文件导入mysql进行分析”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“基于Python怎么实现cdn日志文件导入Mysql进行分析”吧!
周六日出现CDN大量请求,现需要分析其请求频次与来源,查询是否存在被攻击问题。
本文以阿里云CDN日志作为辅助查询数据,其它云平台大同小异。
系统提供的离线日志如下所示:
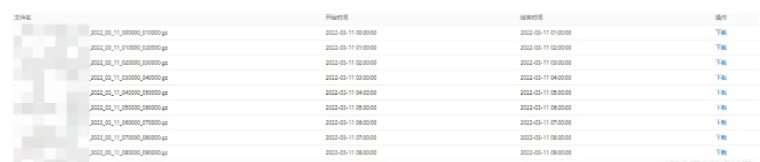
日志实例如下所示:
[9/Jun/2015:01:58:09 +0800] 10.10.10.10 - 1542 "-" "GET Http://www.aliyun.com/index.html" 200 191 2830 MISS "Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://example.com/robot/)" "text/html"
其中相关字段的解释如下:
[9/Jun/2015:01:58:09 +0800]:日志开始时间。
10.10.10.10:访问IP。
-:代理IP。
1542:请求响应时间,单位为毫秒。
"-": HTTP请求头中的Referer。
GET:请求方法。
http://www.aliyun.com/index.html:用户请求的URL链接。
200:HTTP状态码。
191:请求大小,单位为字节。
2830:请求返回大小,单位为字节。
MISS:命中信息。
HIT:用户请求命中了CDN边缘节点上的资源(不需要回源)。
MISS:用户请求的内容没有在CDN边缘节点上缓存,需要向上游获取资源(上游可能是CDN L2节点,也可能是源站)。
Mozilla/5.0(compatible; AhrefsBot/5.0; +http://example.com/robot/):User-Agent请求头信息。
text/html:文件类型。
按照上述字段说明创建一个 mysql 表,用于后续通过 Python 导入 Mysql 数据,字段可以任意定义
SET NAMES utf8mb4;SET FOREIGN_KEY_CHECKS = 0;-- ------------------------------ Table structure for ll-- ----------------------------DROP TABLE IF EXISTS `ll`;CREATE TABLE `ll` ( `id` int(11) NOT NULL, `s_time` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `ip` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `pro_ip` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `dura_time` int(11) NULL DEFAULT NULL, `referer` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `method` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `url` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `code` int(255) NULL DEFAULT NULL, `size` double NULL DEFAULT NULL, `res_size` double NULL DEFAULT NULL, `miss` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `ua` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `html_type` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;SET FOREIGN_KEY_CHECKS = 1;下载全部日志之后,使用 Python 批量导入数据库中,解析代码如下,在提前开始前需要先看一下待提取的每行数据内容。
[11/Mar/2022:00:34:17 +0800] 118.181.139.215 - 1961 "http://xx.baidu.cn/" "GET https://cdn.baidu.com/video/1111111111.mp4" 206 66 3739981 HIT "Mozilla/5.0 (iPad; CPU OS 15_1 like Mac OS X) AppleWEBKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 SP-engine/2.43.0 main%2F1.0 baiduboxapp/13.5.0.10 (Baidu; P2 15.1) NABar/1.0" "video/mp4"
初看之下,我们会使用空格进行切片,例如下述代码:
import os# 获取文件名my_path = r"C:日志目录"file_names = os.listdir(my_path)file_list = [os.path.join(my_path, file) for file in file_names]for file in file_list: with open(file, 'r', encoding='utf-8') as f: lines = f.readlines() for i in lines: item_list = i.split(' ') s_time = item_list[0]+' '+item_list[1] ip = item_list[2], pro_ip =item_list[3], dura_time =item_list[4], referer =item_list[5], method =item_list[6], url = item_list[7], code =item_list[8], size =item_list[9], res_size =item_list[10], miss =item_list[11], html_type =item_list[12] print(s_time,ip,pro_ip,dura_time,referer,method,url,code,size,res_size,miss,html_type)运行之后,会发现里面的开始时间位置,UA位置都存在空格,所以该方案舍弃,接下来使用正则表达式提取。
参考待提取的模板编写正则表达式如下所示:
\[(?<time>.*?)\] (?<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (?<pro_ip>.*?) (?<dura_time>\d+) \"(?<referer>.*?)\" \"(?<method>.*?) (?<url>.*?)\" (?<code>\d+) (?<size>\d+) (?<res_size>\d+) (?<miss>.*?) \"(?<ua>.*?)\" \"(?<html_type>.*?)\"
接下来进行循环读取数据,然后进行提取:
import osimport reimport pymysql# 获取文件名my_path = r"C:日志文件夹"file_names = os.listdir(my_path)file_list = [os.path.join(my_path, file) for file in file_names]wait_list = []for file in file_list: with open(file, 'r', encoding='utf-8') as f: lines = f.readlines() for i in lines: pattern = re.compile( '\[(?P<time>.*?)\] (?P<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (?P<pro_ip>.*?) (?P<dura_time>\d+) \"(?P<referer>.*?)\" \"(?P<method>.*?) (?P<url>.*?)\" (?P<code>\d+) (?P<size>\d+) (?P<res_size>\d+) (?P<miss>.*?) \"(?P<ua>.*?)\" \"(?P<html_type>.*?)\"') gs = pattern.findall(i) item_list = gs[0] s_time = item_list[0] ip = item_list[1] pro_ip = item_list[2] dura_time = item_list[3] referer = item_list[4] method = item_list[5] url = item_list[6] code = item_list[7] size = item_list[8] res_size = item_list[9] miss = item_list[10] ua = item_list[11] html_type = item_list[12] values_str = f"('{s_time}', '{ip}', '{pro_ip}', {int(dura_time)}, '{referer}', '{method}', '{url}', {int(code)}, {int(size)}, {int(res_size)}, '{miss}', '{ua}','{html_type}')" wait_list.append(values_str)读取到数据存储到 wait_list 列表中,然后操作列表,写入MySQL,该操作为了防止SQL语句过长,所以每次间隔1000元素进行插入。
def insert_data(): for i in range(0,int(len(wait_list)/1000+1)): items = wait_list[i * 1000:i * 1000 + 1000] item_str = ",".join(items) inser_sql = f"INSERT INTO ll(s_time, ip, pro_ip, dura_time, referer, method, url,code, size, res_size, miss, ua,html_type) VALUES {item_str}" db = pymysql.connect(host='localhost', user='root', passWord='root', database='logs') cursor = db.cursor() try: cursor.execute(inser_sql) db.commit() except Exception as e: # print(content) print(e) db.rollback()最终的结果如下所示:
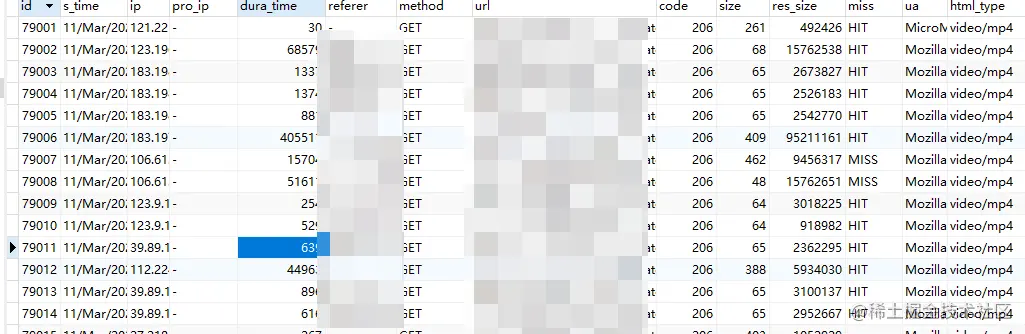
导入MySQL之后,就可以按照自己的需求进行排序与查询了。
可以通过 refer 计算请求次数:
select count(id) num,referer from ll GROUP BY referer ORDER BY num desc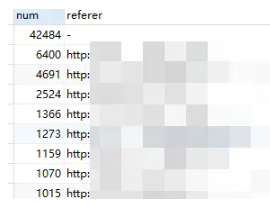
到此,相信大家对“基于python怎么实现cdn日志文件导入mysql进行分析”有了更深的了解,不妨来实际操作一番吧!这里是编程网网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
--结束END--
本文标题: 基于python怎么实现cdn日志文件导入mysql进行分析
本文链接: https://www.lsjlt.com/news/329476.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0