Python 官方文档:入门教程 => 点击学习
这篇文章主要介绍“python基于词频排序如何实现快速挖掘关键词”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python基于词频排序如何实现快速挖掘关键词”文章能帮助大家解决问题。一、所有的代码这
这篇文章主要介绍“python基于词频排序如何实现快速挖掘关键词”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python基于词频排序如何实现快速挖掘关键词”文章能帮助大家解决问题。
这是所有的代码
from collections import defaultdictimport jieba.posseg as jpwith open('keyWord.txt','r',encoding='utf-8') as file:keyword_list = file.read().split('\n')not_flag = set(['w','x','y','z','un','m'])not_word = set(['的','是','有','啊','呢','么','好'])keyword_split = dict()word_count = defaultdict(int)for keyword in keyword_list:word_set = set()for word,flag in jp.cut(keyword):if flag in not_flag:continueif word in not_word:continueif word == 'pdf' or word == 'PDF':continueword_count[word] += 1word_set.add(word)keyword_split[keyword] = word_setid_keyword_list = defaultdict(list)id_count = defaultdict(int)for keyword,word_set in keyword_split.items():word_sort = dict()for word in word_set:word_sort[word] = word_count[word]word_sort = sorted(word_sort.items(),key=lambda x:x[1],reverse=True)word_id = ','.join([word for word,count in word_sort[0:3]])id_keyword_list[word_id] += [keyword]id_count[word_id] += 1result = []id_count = sorted(id_count.items(),key=lambda x:x[1],reverse=True)for word_id,count in id_count:if count < 3:continuefor keyword in id_keyword_list[word_id]:result.append('%s\t%s' % (keyword,word_id))result.append('')with open('result.txt','wb') as file:file.write('\n'.join(result).encode('utf-8'))keyword.txt如下图:
有50万的关于pdf的关键词数据
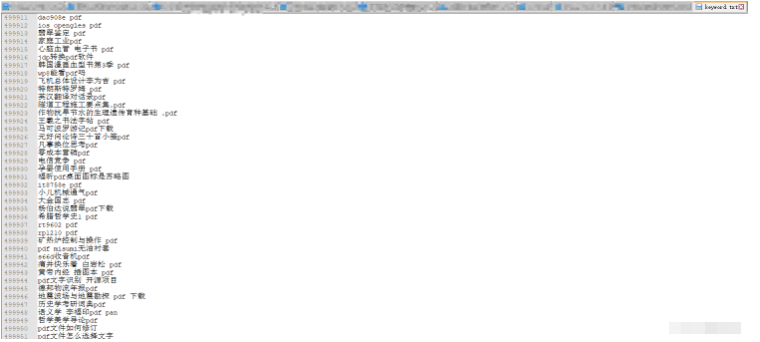
最后的输出result.txt 就是将里面的含有关键词相同的句子统一输出出来:
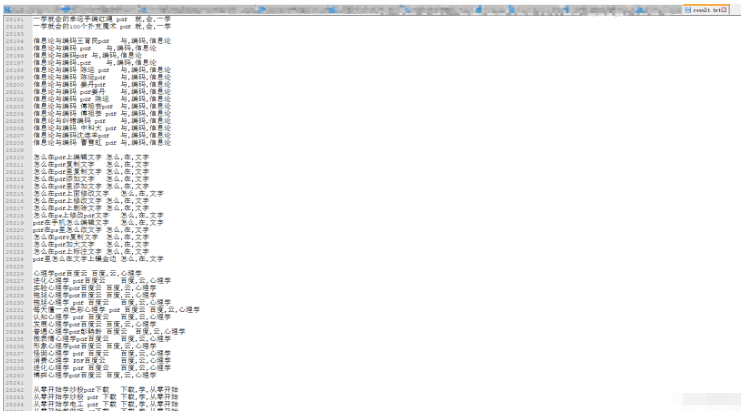
这里会将一个句子的3个关键词输出出来 关键词是根据词频排序的。
最后将所有关键词一样的句子组合在一起,就可以知道这些句子表达的意思大致一致
keyword_list 是从keyword.txt读取到的所有的句子
not_flag 是要排除的标记,不统计这些标记
not_word 是要排除的单词,不统计这些单词
keyword_split 是句子对应到他的所有单词的字典,key是句子,value是他的所有单词的集合
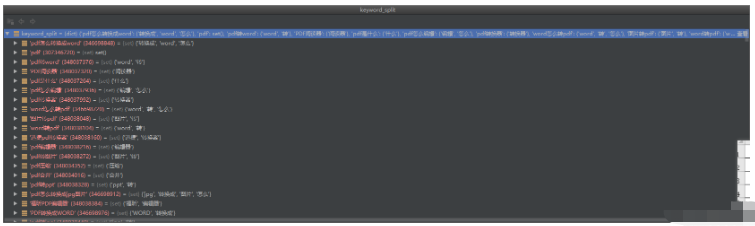
word_count 是所有的拆分后的单词的次数的字典,key是单词,value是单词出现的次数
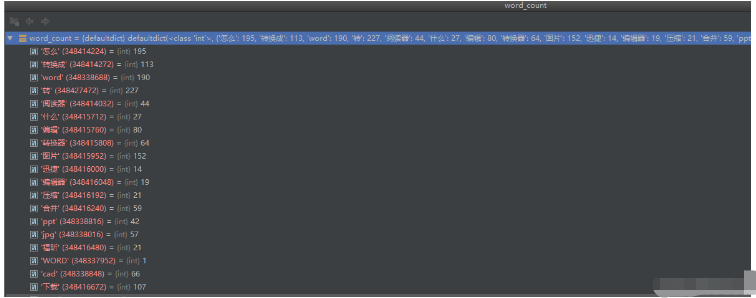
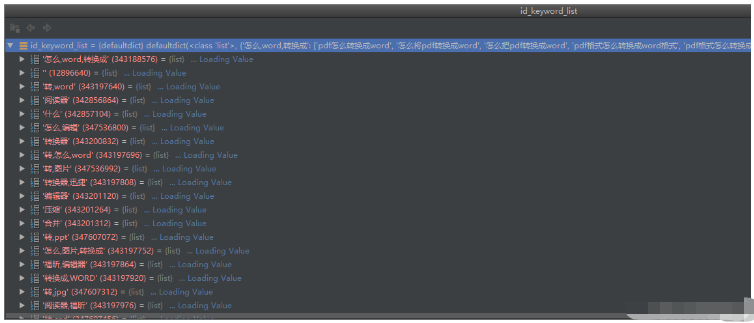
id_keyword_list 是一个字典,它的key是一个字符串 value是列表

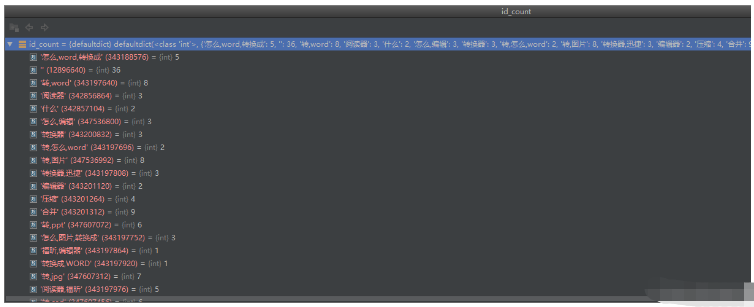
id_count 是一个字典,它的key是一个字符串,value是int

最后对id_count处理 将结果输出出来
id_count = sorted(id_count.items(), key=lambda x: x[1], reverse=True)for word_id, count in id_count: if count < 3: continue for keyword in id_keyword_list[word_id]: result.append('%s\t%s' % (keyword, word_id)) result.append('')关于“Python基于词频排序如何实现快速挖掘关键词”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注编程网Python频道,小编每天都会为大家更新不同的知识点。
--结束END--
本文标题: Python基于词频排序如何实现快速挖掘关键词
本文链接: https://www.lsjlt.com/news/350713.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0