这篇文章主要介绍“PyTorch Distributed Data Parallel如何使用”,在日常操作中,相信很多人在PyTorch Distributed Data Para
这篇文章主要介绍“PyTorch Distributed Data Parallel如何使用”,在日常操作中,相信很多人在PyTorch Distributed Data Parallel如何使用问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”PyTorch Distributed Data Parallel如何使用”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Distributed Data Parallel 简称 DDP,是 PyTorch 框架下一种适用于单机多卡、多机多卡任务的数据并行方式。由于其良好的执行效率及广泛的显卡支持,熟练掌握 DDP 已经成为深度学习从业者所必备的技能之一。
具体讲解 DDP 之前,我们先了解了解它和 Data Parallel (DP) 之间的区别。DP 同样是 PyTorch 常见的多 GPU 并行方式之一,且它的实现非常简洁:
# 函数定义torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)'''module : 模型device_ids : 参与训练的 GPU 列表output_device : 指定输出的 GPU, 通常省略, 即默认使用索引为 0 的显卡'''# 程序模板device_ids = [0, 1]net = torch.nn.DataParallel(net, device_ids=device_ids)基本原理及固有缺陷:在 Data Parallel 模式下,数据会被自动切分,加载到 GPU。同时,模型也将拷贝至各个 GPU 进行正向传播。在多个进程之间,会有一个进程充当 master 节点,负责收集各张显卡积累的梯度,并据此更新参数,再统一发送至其他显卡。因此整体而言,master 节点承担了更多的计算与通信任务,容易造成网络堵塞,影响训练速度。
常见问题及解决方案:Data Parallel 要求模型必须在 device_ids[0] 拥有参数及缓冲区,因此当卡 0 被占用时,可以在 nn.DataParallel 之前添加如下代码:
# 按照 PIC_BUS_ID 顺序自 0 开始排列 GPU 设备os.environ['CUDA_DEVICE_ORDER'] = 'PIC_BUS_ID'# 设置当前使用的 GPU 为 2、3 号设备os.environ['CUDA_VISIBLE_DEVICES'] = '2, 3'如此,device_ids[0] 将被默认为 2 号卡,device_ids[1] 则对应 3 号卡
相较于 DP, Distributed Data Parallel 的实现要复杂得多,但是它的优势也非常明显:
DDP 速度更快,可以达到略低于显卡数量的加速比;
DDP 可以实现负载的均匀分配,克服了 DP 需要一个进程充当 master 节点的固有缺陷;
采用 DDP 通常可以支持更大的 batch size,不会像 DP 那样出现其他显卡尚有余力,而卡 0 直接 out of memory 的情况;
另外,在 DDP 模式下,输入到 data loader 的 bacth size 不再代表总数,而是每块 GPU 各自负责的 sample 数量。比方说,batch_size = 30,有两块 GPU。在 DP 模式下,每块 GPU 会负责 15 个样本。而在 DDP 模式下,每块 GPU 会各自负责 30 个样本;
DDP 基本原理:倘若我们拥有 N 张显卡,则在 Distributed Data Parallel 模式下,就会启动 N 个进程。每个进程在各自的卡上加载模型,且模型的参数完全相同。训练过程中,各个进程通过一种名为 Ring-Reduce 的方式与其他进程通信,交换彼此的梯度,从而获得所有的梯度信息。随后,各个进程利用梯度的平均值更新参数。由于初始值和更新量完全相同,所以各个进程更新后的参数仍保持一致。
rank
进程号
多进程上下文中,通常假定 rank = 0 为主进程或第一个进程
物理节点,表示一个容器或一台机器
节点内部可以包含多个 GPU
local_rank
一个 node 中,进程的相对序号
local_rank 在 node 之间独立
world_size
全局进程数
一个分布式任务中 rank 的数量
group
进程组
一个分布式任务就对应一个进程组
只有当用户创立多个进程组时,才会用到
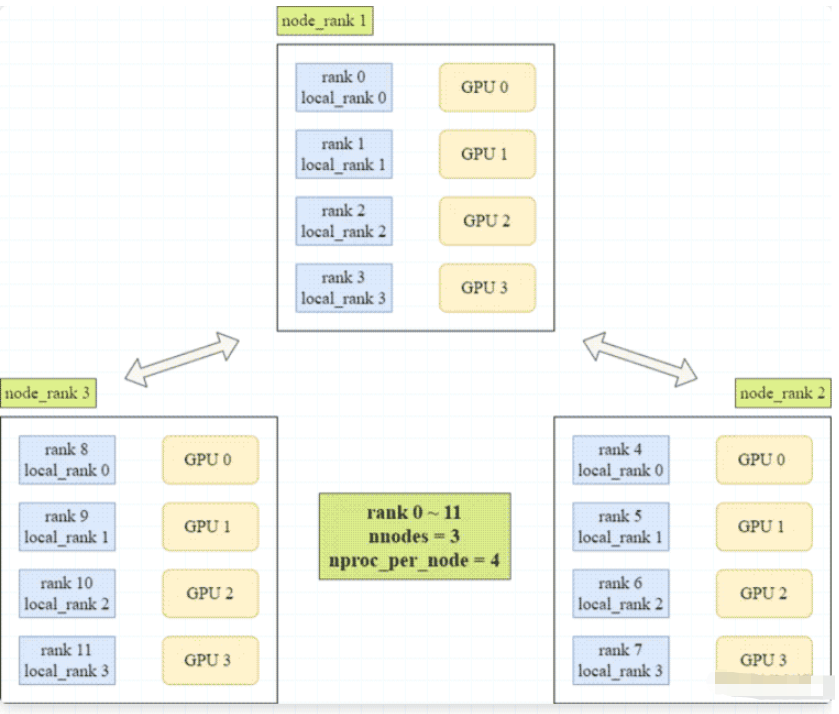
Distributed Data Parallel 可以通过 python 的 torch.distributed.launch 启动器,在命令行分布式地执行 Python 文件。执行过程中,启动器会将当前进程(其实就是 GPU)的 index 通过参数传递给 Python,而我们可以利用如下方式获取这个 index:
import argparseparser = argparse.ArgumentParser()parser.add_argument('--local_rank', default=-1, type=int, metavar='N', help='Local process rank.')args = parser.parse_args()# print(args.local_rank)# local_rank 表示本地进程序号随后,初始化进程组。对于在 GPU 执行的任务,建议选择 nccl (由 NVIDIA 推出) 作为通信后端。对于在 CPU 执行的任务,建议选择 gloo (由 Facebook 推出) 作为通信后端。倘若不传入 init_method,则默认为 env://,表示自环境变量读取分布式信息
dist.init_process_group(backend='nccl', init_method='env://')# 初始化进程组之后, 通常会执行这两行代码torch.cuda.set_device(args.local_rank)device = torch.device('cuda', args.local_rank)# 后续的 model = model.to(device), tensor.cuda(device)# 对应的都是这里由 args.local_rank 初始化得到的 device数据部分,使用 Distributed Sampler 划分数据集,并将 sampler 传入 data loader。需要注意的是,此时在 data loader 中不能指定 shuffle 为 True,否则会报错 (sampler 已具备随机打乱功能)
dev_sampler = data.DistributedSampler(dev_data_set)train_sampler = data.DistributedSampler(train_data_set)dev_loader = data.DataLoader(dev_data_set, batch_size=dev_batch_size, shuffle=False, sampler=dev_sampler)train_loader = data.DataLoader(train_data_set, batch_size=train_batch_size, shuffle=False, sampler=train_sampler)模型部分,首先将将模型送至 device,即对应的 GPU 上,再使用 Distributed Data Parallel 包装模型(顺序颠倒会报错)
model = model.to(device)model = nn.parallel.DistributedDataParallel( model, device_ids=[args.local_rank], output_device=args.local_rank)Distributed Data Parallel 模式下,保存模型应使用 net.module.state_dict(),而非 net.state_dict()。且无论是保存模型,还是 LOGGER 打印,只对 local_rank 为 0 的进程操作即可,因此代码中会有很多 args.local_rank == 0 的判断
if args.local_rank == 0: LOGGER.info(f'saving latest model: {output_path}') torch.save({'model': model.module.state_dict(), 'optimizer': None, 'epoch': epoch, 'best-f1': best_f1}, open(os.path.join(output_path, 'latest_model_{}.pth'.fORMat(fold)), 'wb'))利用 torch.load 加载模型时,设置 map_location=device,否则卡 0 会承担更多的开销
load_model = torch.load(best_path, map_location=device)model.load_state_dict(load_model['model'])dist.barrier() 可用于同步多个进程,建议只在必要的位置使用,如初始化 DDP 模型之前、权重更新之后、开启新一轮 epoch 之前
计算 accuracy 时,可以使用 dist.all_reduce(score, op=dist.ReduceOp.SUM),将各个进程计算的准确率求平均
计算 f1-score 时,可以使用 dist.all_gather(all_prediction_list, prediction_list),将各个进程获得的预测值和真实值汇总到 all_list,再统一代入公式
torch.distributed.launch
# 此处 --nproc_per_node 4 的含义是 server 有 4 张显卡python torch.distributed.launch --nproc_per_node 4 train.py# 倘若使用 nohup, 则注意输入命令后 exit 当前终端python torch.distributed.launch --nproc_per_node 4 train.pytorchrun,推荐使用这种方式,因为 torch.distributed.launch 即将弃用
代码中,只需将 Argument Parser 相关的部分替换为
local_rank = int(os.environ['LOCAL_RANK'])然后将 args.local_rank 全部改为 local_rank 即可
启动命令
# 单机多卡训练时, 可以不指定 nnodestorchrun --nnodes=1 --nproc_per_node=4 train.py# 倘若使用 nohup, 则注意输入命令后 exit 当前终端nohup torchrun --nnodes=1 --nproc_per_node=4 train.py > nohup.out &到此,关于“PyTorch Distributed Data Parallel如何使用”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: PyTorch Distributed Data Parallel如何使用
本文链接: https://www.lsjlt.com/news/352093.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0