今天小编给大家分享一下pandas库之DataFrame滑动窗口如何实现的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。(1)
今天小编给大家分享一下pandas库之DataFrame滑动窗口如何实现的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
提供滑动窗口计算,可用于时间序列(时间和日期)数据
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None, method='single')参数:
window:int, offset, or BaseIndexer subclass
移动窗口的大小,如果是整数,代表每个窗口覆盖的固定数量;如果是offset(pandas时间序列),代表每个窗口的时间段,每个窗口的大小将根据时间段中包含的观察值而变化,仅对datetimelike索引有效。
min_periods:int, default None
窗口计算值要求至少有min_periods个观测值。窗口由时间类型指定,则min_periods默认为1,窗口为整数,则min_periods默认为窗口大小
center:bool, default False
是否将窗口中间索引设为窗口计算后的标签
win_type:str, default None
观测值的权重分布。如果为None,则所有点的权重均相等。如果是字符串,要求是 scipy.signal window function函数
on:str, optional
对于 DataFrame,计算滚动窗口所依照的列标签或索引级别,而不是 DataFrame 的索引
axis:int or str, default 0
如果是0或’index’,按行滚动;如果是1或’columns’,按列滚动
closed:str, default None
‘right’:窗口中的第一个点将从计算中排除;‘left‘:窗口中的最后一个点将从计算中排除;‘both’:窗口中没有点将从计算中排除;‘neither’:窗口中的第一个点和最后一个点将从计算中排除;默认’right’
窗口大小为2的求和
>>> import pandas as pd>>> import numpy as np>>> df = pd.DataFrame({'B':[0,1,2,np.nan,4]})>>> df B0 0.01 1.02 2.03 NaN4 4.0>>> df.rolling(2).sum() B0 NaN1 1.02 3.03 NaN4 NaN窗口为2s的求和
>>> df_time = pd.DataFrame({'B':[0,1,2,np.nan,4]}, index = [ pd.Timestamp('20130101 09:00:00'), pd.Timestamp('20130101 09:00:02'), pd.Timestamp('20130101 09:00:03'), pd.Timestamp('20130101 09:00:05'), pd.Timestamp('20130101 09:00:06')]) >>> df_time B2013-01-01 09:00:00 0.02013-01-01 09:00:02 1.02013-01-01 09:00:03 2.02013-01-01 09:00:05 NaN2013-01-01 09:00:06 4.0>>> df_time.rolling('2s').sum() B2013-01-01 09:00:00 0.02013-01-01 09:00:02 1.02013-01-01 09:00:03 3.02013-01-01 09:00:05 NaN2013-01-01 09:00:06 4.0有 2 个观测值的前视窗口的滚动求和(a和a+1)
# 设置前向窗口>>> indexer = pd.api.indexers.FixedForwardWindowIndexer(window_size=2)>>> df = pd.DataFrame({'B': [0, 1, 2, np.nan, 4]})>>> df.rolling(window=indexer,min_periods=1).sum() B0 1.01 3.02 2.03 4.04 4.0窗口长度为 2 个观测值的滚动和,但至少需要 1 个观测值才可计算值
>>> df.rolling(2,min_periods=1).sum() B0 0.01 1.02 3.03 2.04 4.0滚动总和,并将结果分配到窗口索引的中心
>>> df.rolling(3, min_periods=1, center=True).sum() B0 1.01 3.02 3.03 6.04 4.0>>> df.rolling(3, min_periods=1, center=False).sum() B0 0.01 1.02 3.03 3.04 6.0高斯分布窗口
>>> df.rolling(2,win_type='gaussian').sum(std=3) B0 NaN1 0.9862072 2.9586213 NaN4 NaN窗口由从当前观测值回溯窗口长度组成
>>> import pandas as pd>>> s = pd.Series(range(5))>>> s0 01 12 23 34 4dtype: int64# 5个分区>>> for window in s.rolling(window=2):print(window)0 0dtype: int640 01 1dtype: int641 12 2dtype: int642 23 3Dtype: int643 34 4dtype: int64panadas支持4种窗口操作
Rolling window:值的固定/变动的滑动窗口
Weighted window:由 scipy.signal 库提供的加权非矩形窗口
Expanding window:值的累积窗口
Exponentially Weighted window:值的累积和指数加权窗
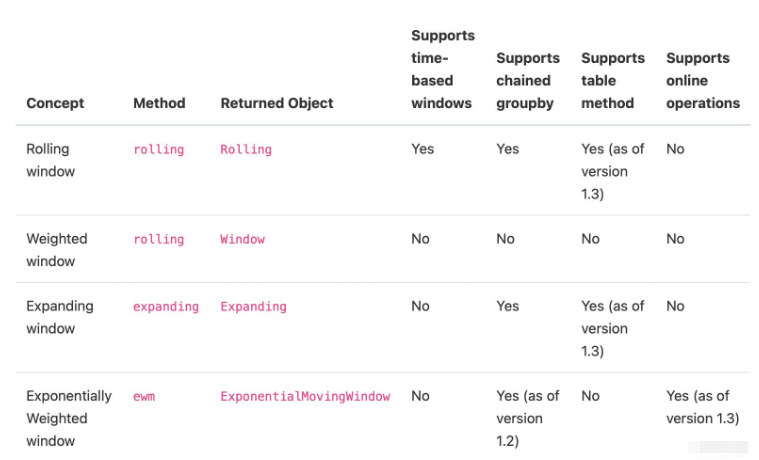
其中滑动窗口支持时间序列的计算
>>> s = pd.Series(range(5),index = pd.date_range('2020-01-01',periods=5,freq='1D'))>>> s2020-01-01 02020-01-02 12020-01-03 22020-01-04 32020-01-05 4Freq: D, dtype: int64>>> s.rolling(window='2D').sum()2020-01-01 0.02020-01-02 1.02020-01-03 3.02020-01-04 5.02020-01-05 7.0Freq: D, dtype: float64部分窗口支持先分组再执行窗口操作
>>> df = pd.DataFrame({'A':['a', 'b', 'a', 'b', 'a'],'B':range(5)})>>> df A B0 a 01 b 12 a 23 b 34 a 4>>> df.groupby('A').expanding().sum() BA a 0 0.0 2 2.0 4 6.0b 1 1.0 3 4.0>>> times = ['2020-01-01', '2020-01-03', '2020-01-04', '2020-01-05', '2020-01-29']>>> s = pd.Series(range(5),index = pd.DatetimeIndex(times))>>> s2020-01-01 02020-01-03 12020-01-04 22020-01-05 32020-01-29 4dtype: int64# 两个观测值的窗口>>> s.rolling(2).sum()2020-01-01 NaN2020-01-03 1.02020-01-04 3.02020-01-05 5.02020-01-29 7.0dtype: float64# 两天的窗口>>> s.rolling('2D').sum()2020-01-01 0.02020-01-03 1.02020-01-04 3.02020-01-05 5.02020-01-29 4.0dtype: float64窗口计算后默认标签是窗口的最后一个,center可以使中间索引作为标签
>>> s = pd.Series(range(10))>>> s.rolling(window=5).mean()0 NaN1 NaN2 NaN3 NaN4 2.05 3.06 4.07 5.08 6.09 7.0dtype: float64>>> s.rolling(window=5, center=True).mean()0 NaN1 NaN2 2.03 3.04 4.05 5.06 6.07 7.08 NaN9 NaNdtype: float64自定义窗口计算公式
>>> import numpy as np>>> def mad(x):return np.fabs(x - x.mean()).mean()>>> s = pd.Series(range(10))>>> s.rolling(window=4).apply(mad, raw=True)0 NaN1 NaN2 NaN3 1.04 1.05 1.06 1.07 1.08 1.09 1.0dtype: float64为窗口中的值添加权重
>>> s = pd.Series(range(10))>>> s.rolling(window=5, win_type="gaussian").mean(std=0.1)0 NaN1 NaN2 NaN3 NaN4 2.05 3.06 4.07 5.08 6.09 7.0dtype: float64以上就是“pandas库之DataFrame滑动窗口如何实现”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注编程网精选频道。
--结束END--
本文标题: pandas库之DataFrame滑动窗口如何实现
本文链接: https://www.lsjlt.com/news/354775.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
2024-05-24
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作



0