函数 Go 函数与函数声明 在 Go 语言中,函数是唯一一种基于特定输入,实现特定任务并可返回任务执行结果的代码块(Go 语言中的方法本质上也是函数)。在 Go 中,我们定义一个函数的最常用方式就是使用函数声明。 第一部分是关键字 f

func(io.Writer, string, ...interface{}) (int, error)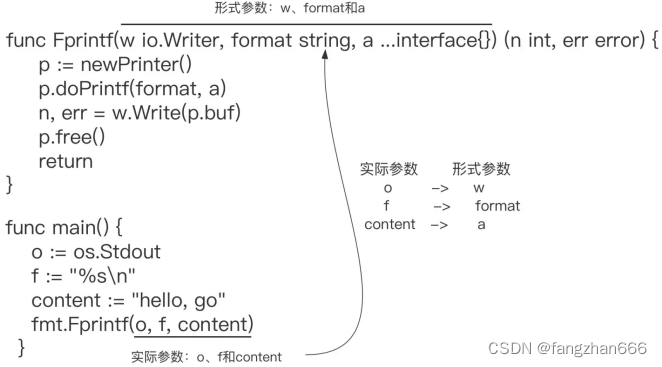
func foo() // 无返回值func foo() error // 仅有一个返回值func foo() (int, string, error) // 有2或2个以上返回值// $GOROOT/src/net/Http/server.gotype HandlerFunc func(ResponseWriter, *Request)// $GOROOT/src/sort/genzfunc.gotype visitFunc func(ast.node) ast.Visitor// $GOROOT/src/builtin/builtin.gotype interface error {Error() string}err := errors.New("your first demo error")errWithCtx = fmt.Errorf("index %d is out of bounds", i)// $GOROOT/src/errors/errors.gotype errorString struct {s string} func (e *errorString) Error() string {return e.s}// $GOROOT/src/net/net.gotype OpError struct {Op stringNet stringSource AddrAddr AddrErr error}err := doSomething()if err != nil {// 不关心err变量底层错误值所携带的具体上下文信息// 执行简单错误处理逻辑并返回... ...return err}data, err := b.Peek(1)if err != nil {switch err.Error() {case "bufio: negative count":// ... ...returncase "bufio: buffer full":// ... ...returncase "bufio: invalid use of UnreadByte":// ... ...returndefault:// ... ...return}}// $GOROOT/src/bufio/bufio.govar (ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte")ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune")ErrBufferFull = errors.New("bufio: buffer full")ErrNegativeCount = errors.New("bufio: negative count"))data, err := b.Peek(1)if err != nil {switch err {case bufio.ErrNegativeCount:// ... ...returncase bufio.ErrBufferFull:// ... ...returncase bufio.ErrInvalidUnreadByte:// ... ...returndefault:// ... ...return}}func bar() {defer func() {if e := recover(); e != nil {fmt.Println("recover the panic:", e)}}()println("call bar")panic("panic occurs in bar")zoo()println("exit bar")}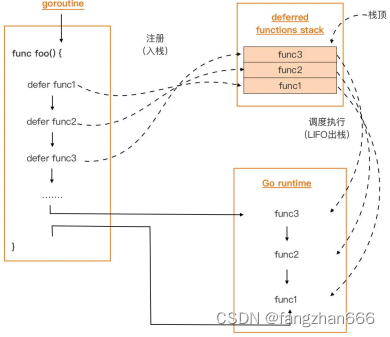
来源地址:https://blog.csdn.net/fangzhan666/article/details/132475536
--结束END--
本文标题: 《Go 语言第一课》课程学习笔记(十二)
本文链接: https://www.lsjlt.com/news/382590.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0