实训笔记8.29 8.29笔记一、《白龙马电商用户行为日志分析平台》项目概述--大数据离线项目1.1 项目的预备知识1.1.1 电商平台1.1.2 用户行为数据1.1.3 常见的软件/网站的组成和技术实现1.1.4 大数据中数据计算
数据产生环节(不属于我们项目的一部分,只不过因为我们没有数据产生的源头,所以我们需要根据白龙马网站脱敏数据格式我们模拟数据产生即可)–才有数据供大数据环境去存储和处理,同时数据产生是不会停止的,除非网站不使用了。
数据采集存储阶段:将网站产生的用户行为数据采集存储到大数据环境中,保证数据能持久化、海量化、高可靠的保存下来
技术选项:Flume+hdfs
执行周期:7*24小时不停止的执行的
数据清洗预处理阶段:采集存储的数据中把数据质量不好的数据剔除,把格式不规整的数据统一格式,得到高质量数据。
技术选项:mapReduce+HDFS
执行周期:周期性调度执行的(一天执行一次,第二天处理前一天采集存储的数据)
数据统计分析阶段:在清洗预处理完成的高质量数据基础之上,我们采用一些统计分析的技术,从数据中统计分析相关的功能指标
技术选项:Hive
执行周期:同数据清洗预处理的周期
数据迁移导出阶段:将Hive统计分析完成的结果指标迁移导出到RDBMS中,留备后期的大数据环节操作 技术选项:sqoop+Mysql 执行周期:同数据统计分析的执行周期
步骤3~5:大数据离线计算环节–周期性(一天执行一次)调度执行 而是7、任务调度阶段(azkaban)
步骤2~5:大数据开发人员的工作
数据可视化阶段(严格意义上不属于大数据开发工程师的工作范围):将指标结果以图表的形式进行展示
技术选项:代码可视化、DataV
执行周期:7*24小时执行的
254.126.32.169 - - 2018-02-10 05:14:31 "POST https://www.bailongma.com/cateGory/a Http/1.0" 500 92077 https://www.bailongma.com/category/a Safari WEBkitwindows 甘肃 36.04 103.51 27 模拟电商网站中用户触发行为之后,网站后端自动记录用户行为数据到日志文件的过程
通过Java代码+io流+随机数+for循环+时间格式化类 实现的数据模拟
让数据产生更加契合真实的业务数据产生场景。将数据产生的代码打成jar包,然后再服务器上借助java -jar|-cp xxx.jar [全限定类名]
电商网站产生的用户行为数据记录到一个日志文件中**/root/project/data-gen/userBehavior.log**,但是文件是直接存储在我们服务器的硬盘上的,但是服务器的硬盘是有大小的,而且服务器的硬盘也不是分布式的,因此无法存储海量数据,而我们网站的用户行为数据因为它是7*24小时不停止的采集的,因此就会出现计算机无法存储userBehavior.log海量的数据。所以我们需要通过数据采集存储技术将userBehavior.log产生的用户行为数据采集存储到大数据分布式文件系统HDFS中。 同时因为userBehavior.log无法记录海量数据,userBehavior.log文件真正的业务场景下会有定期的清理规则。
大数据中数据采集技术有很多的 Flume、SQOOP、DataX、Cancl…
采集日志文件数据到大数据环境中,符合要求的只有一个技术Flume技术
Flume+HDFS
核心思想就是编写Flume数据采集存储脚本,脚本中指定Flume的agent进程中source、channel、sink的类型
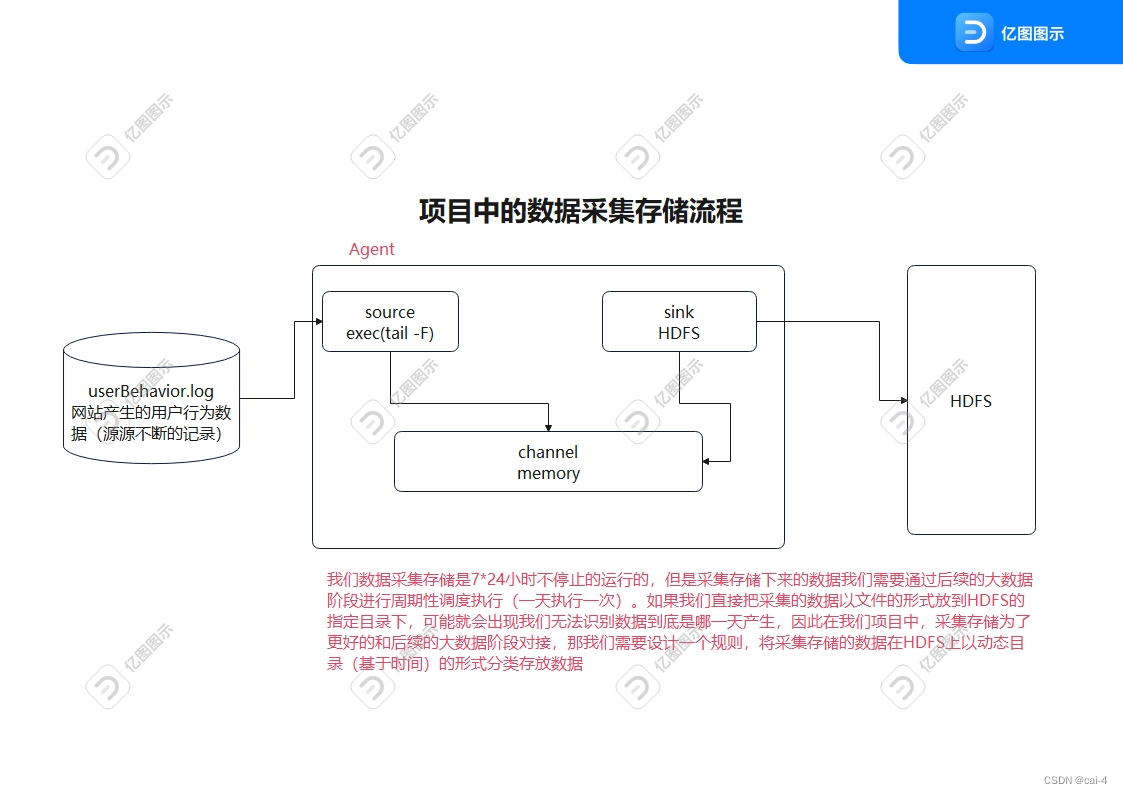
# 1、给Flume进程agent起名别 source channel sink组件起别名project.sources=s1project.channels=c1project.sinks=k1# 2、配置source关联的数据源 记录用户行为数据的日志文件/root/project/data-gen/userBehavior.logproject.sources.s1.type=execproject.sources.s1.command=tail -F /root/project/data-gen/userBehavior.log# 3、配置channel管道 基于内存的project.channels.c1.type=memoryproject.channels.c1.capacity=20000project.channels.c1.transactionCapacity=10000project.channels.c1.byteCapacity=104857600# 4、配置sink关联的目的地 HDFS HDFS的目的地是一个基于时间的动态目录project.sinks.k1.type=hdfsproject.sinks.k1.hdfs.path=hdfs://single:9000/dataCollect/%Y-%m-%dproject.sinks.k1.hdfs.round=trueproject.sinks.k1.hdfs.roundValue=24project.sinks.k1.hdfs.roundUnit=hourproject.sinks.k1.hdfs.filePrefix=dataproject.sinks.k1.hdfs.fileSuffix=.logproject.sinks.k1.hdfs.useLocalTimeStamp=true# 文件滚动设置只基于文件的大小的滚动 不基于event滚动、时间滚动project.sinks.k1.hdfs.rollInterval=0project.sinks.k1.hdfs.rollCount=0project.sinks.k1.hdfs.rollSize=134217728project.sinks.k1.hdfs.fileType=DataStream# 5、关联agent的各个组件project.sources.s1.channels=c1project.sinks.k1.channel=c1【问题】:采集到HDFS上文件的格式文件
采集存储的数据我们是没有做任何的校验的,也就意味着不管数据正确与否(价值密度低),全部采集存储了下来,但是这样的话,我们对数据在进行统计分析的时候,有问题的数据可能就会造成我们的统计结果准确性收到影响。
其中数据正确与否的问题在大数据中是有一个专业的名词–数据质量问题。
简而言之,数据清洗预处理就是把采集的数据中质量不好的数据过滤掉,同时把数据格式统一化,得到高质量数据。
数据清洗预处理其实说白就是一种数据计算。而且因为我们采集的数据量比较庞大,因此我们不能使用普通技术完成数据的计算过程,最起码我们得使用大数据计算框架才能完成。
本次我们项目对计算的时间没有要求,同时因为数据中到底哪些数据有问题我们都不太清楚,所以我们可以选择使用MapReduce技术完成,使用Hive的话因为数据问题可能导致表格出现很大的偏差。
不同的网站/软件采集的用户行为数据都是不一样的,因此我们数据的清洗预处理的规则(哪些数据是合法数据、哪些数据是不合法的数据)不是固定的。而是基于不同的业务场景,不同的数据场景给出合适的清洗预处理规则。
清洗之前的数据格式如下:
120.191.181.178 - - 2018-02-18 20:24:39 "POST https://www.bailongma.com/item/b HTTP/1.1" 203 69172 https://www.bailongma.com/reGISter UCBrowser Webkit X3Android 8.0 海南 20.02 110.20 36 采集的一条完整的用户行为日志是以空格分割的多个字段组成的
ip 两个无意义的中划线字段 时间字段(两个字段组成的) 行为触发之后访问网址(三个字段组成的) 响应状态码 响应字节数 来源网址 用户使用的浏览器信息(至少有一个字段) 地址信息(三个字段组成的) 年龄 一条完成的用户行为数据最少应该由16个字段组成。因为我们只需要对数据进行过滤和预处理操作,不涉及到聚合操作,因此MR程序中不需要包含Reduce阶段,只需要有Map阶段即可
MapReduce程序在去处理数据时,周期性调度执行的,第二天处理前一天采集存储的数据,因此MR程序在编写时,待处理的输入文件路径应该是一个动态目录(采集存储的昨天的数据目录)
package com.sxuek;import java.io.*;import java.text.SimpleDateFORMat;import java.util.*;public class DataGenerator { //1、定义一个存储IP地址的集合 一会产生模拟数据的时候,模拟数据当中ip地址从集合中随机获取一个 private static List<String> ipList = new ArrayList<>(); //2、定义一个集合,集合存放请求的白龙马的网址 模拟数据当中请求网址时从集合中随机获取一个即可 private static List<String> requestList = new ArrayList<>(); //3、定义一个集合,集合存放来源网站信息,模拟数据的来源网站时候我们可以从集合中随机获取一个即可 private static List<String> refererList = new ArrayList<>(); //4、定义一个集合 存放请求的响应状态码 private static List<String> codeList = new ArrayList<>(); //5、定义一个集合 存放浏览器信息 一会模拟产生数据时,浏览器信息从集合中随机获取 private static List<String> userAgentList = new ArrayList<>(); //6、定义一个集合,集合存放地理位置信息 private static List<String> addressList = new ArrayList<>(); private static void init(){ codeList.addAll(Arrays.asList("200","203","300","301","200","203","300","301","200","203","300","301","200","203","300","301","400","401","403","500","503")); userAgentList.add("Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)"); userAgentList.add("Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1"); userAgentList.add("Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0"); userAgentList.add("Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (Khtml, like Gecko) Version/3.1 Safari/525.13"); userAgentList.add("Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13"); userAgentList.add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11"); userAgentList.add("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .net CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400) "); userAgentList.add("Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0"); userAgentList.add("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11"); BufferedReader bufferedReader = null; try { //如果将项目打成jar包之后,a.log文件不识别,此时我们需要使用类加载器读取jar包中的文件 要求文件必须在一个resources格式的目录下 //这行代码只能在jar包中使用 如果项目没有打jar包的话 这行代码无法识别a.log文件 InputStream inputStream = DataGenerator.class.getClassLoader().getResourceAsStream("b.log"); bufferedReader = new BufferedReader(new InputStreamReader(inputStream));// bufferedReader = new BufferedReader(new FileReader("a.log")); String line = null; //这个数据是我们给大家发送的脱敏数据 脱敏数据大数据没法使用 原因是因为是旧数据 while((line = bufferedReader.readLine()) != null){ String[] array = line.split(" "); //脱敏数据中的IP地址放到ipList集合中 ipList.add(array[0]); //需要把请求方式 请求网站 请求协议三个字段以空格组合放到requestList集合中 requestList.add(array[5]+" "+array[6]+" "+array[7]); //来源信息把它加到来源列表当中 refererList.add(array[10]); refererList.add("https://www.baidu.com/search"); refererList.add("https://www.baidu.com/search"); refererList.add("https://www.baidu.com/search"); refererList.add("https://www.sougou.com/search"); refererList.add("https://www.google.com/search"); //把省份 维度 经度 加到地理位置数据中 addressList.add(array[array.length-4]+" "+array[array.length-3]+" "+array[array.length-2]); } } catch (FileNotFoundException e) { throw new RuntimeException(e); } catch (IOException e) { throw new RuntimeException(e); } finally { if (bufferedReader != null){ try { bufferedReader.close(); } catch (IOException e) { throw new RuntimeException(e); } } } } public static void main(String[] args) throws IOException, InterruptedException { //1、填充模拟数据集合 init(); Scanner scanner = new Scanner(System.in); System.out.println("请输入网站产生的用户行为日志数据文件的路径"); String path = scanner.next(); //定义IO输出流 用于模拟一会数据产生之后输出到日志文件的的过程 BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(path)); //随机类 用于产生随机数的 Random random = new Random(); //定义时间格式类 用于格式化时间的 SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); while (true){ //1、先获取数据产生的一个时间 Calendar calendar = Calendar.getInstance(); boolean judgeNight = isJudgeNight(calendar); // num代表一次产生num条数据 int num = 0; // time代表产生一次数据 休息多长时间 int time = 0; if (judgeNight){ //代表是凌晨的时间 num = random.nextInt(10); time = 30000+random.nextInt(60001); }else{ //代表的是非凌晨的时间 num = random.nextInt(50); time = 1000+ random.nextInt(20001); } for (int i = 0; i < num; i++) { //1、获取ip地址 [0,ipList.size()-1] String ip = ipList.get(random.nextInt(ipList.size())); //2、获取数据的生成时间 Date date = new Date(); //2023-08-28 18:00:00 String dataGenTime = sdf.format(date); //3、随机获取请求的网址--行为触发之后请求的网址 String request = requestList.get(random.nextInt(requestList.size())); //4、随机获取一个状态码 String code = codeList.get(random.nextInt(codeList.size())); //5、随机产生一个响应字节数 int bytes = random.nextInt(100000); //6、随机获取一个来源网站 String referer = refererList.get(random.nextInt(refererList.size())); //7、随机获取一个浏览器信息 String userAgent = userAgentList.get(random.nextInt(userAgentList.size())); //8、随机获取一个地理位置信息 String address = addressList.get(random.nextInt(addressList.size())); //9、随机产生一个年龄 int age = 18+ random.nextInt(71); //组装数据 可以使用StringBuffer完成 数据和数据之间一定要以空格分割 String data = ip+" - - "+dataGenTime+" "+request+" "+code+" "+bytes+" "+referer+" "+userAgent+" "+address+" "+age; //将数据输出 bufferedWriter.write(data); //写出一个换行符 保证一条用户行为数据独占一行 bufferedWriter.newLine(); //bufferWriter是处理流 输出数据必须加flush bufferedWriter.flush(); } //生成num条数据之后 间隔time时间之后再继续生成 Thread.sleep(time); System.out.println("间隔了"+time+"秒之后生成了"+num+"条数据"); } } public static boolean isJudgeNight(Calendar cal){ //先获取当前的时间 Date currentTime = cal.getTime(); //先获取当前日期下的凌晨时间段 两个时间 一个是开始的时间 一个是结束的时间 //开始的时间是当天的00:00:00 结束时间 06:00:00 cal.set(Calendar.HOUR_OF_DAY,0); cal.set(Calendar.MINUTE,0); cal.set(Calendar.SECOND,0); //获取当前时间对应的凌晨的开始时间 Date startTime = cal.getTime(); cal.set(Calendar.HOUR_OF_DAY,6); cal.set(Calendar.MINUTE,0); cal.set(Calendar.SECOND,0); //获取当前时间对应的结束时间 Date endTime = cal.getTime(); if (currentTime.after(startTime) && currentTime.before(endTime)){ return true; }else{ return false; } }}--结束END--
本文标题: 实训笔记8.29
本文链接: https://www.lsjlt.com/news/383160.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答
一口价域名售卖能注册吗?域名是网站的标识,简短且易于记忆,为在线用户提供了访问我们网站的简单路径。一口价是在域名交易中一种常见的模式,而这种通常是针对已经被注册的域名转售给其他人的一种方式。
一口价域名买卖的过程通常包括以下几个步骤:
1.寻找:买家需要在域名售卖平台上找到心仪的一口价域名。平台通常会为每个可售的域名提供详细的描述,包括价格、年龄、流
443px" 443px) https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294.jpg https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294-768x413.jpg 域名售卖 域名一口价售卖 游戏音频 赋值/切片 框架优势 评估指南 项目规模

官方手机版

微信公众号

商务合作




0