Python 官方文档:入门教程 => 点击学习
文章目录 一、概述二、定义2.1 总体样本定义2.2 估算样本定义2.3 两种计算方式2.4 皮尔森距离 三、python 实现3.1 生成随机数据集3.2 绘制散点图3.3 计算相关系数
ρ X , Y = c o v ( X , Y ) σ X σ Y = E ( X − μ X ) E ( Y − μ Y ) σ X σ Y \begin{aligned} \rho_{X,Y} = \frac {cov(X,Y)} {\sigma_{X} \sigma_{Y}} = \frac {E(X-\mu_{X}) E(Y-\mu_{Y})} {\sigma_{X} \sigma_{Y}} \end{aligned} ρX,Y=σXσYcov(X,Y)=σXσYE(X−μX)E(Y−μY)
其中, σX = E { [ X − E ( X ) ] 2 } , σY = E { [ Y − E ( Y ) ] 2 } \sigma_{X} = \sqrt{E\{[X - E(X)]^{2}\}},\sigma_{Y} = \sqrt{E\{[Y - E(Y)]^{2}\}} σX=E{[X−E(X)]2},σY=E{[Y−E(Y)]2}
估算样本的协方差和标准差,可得到样本相关系数(即样本皮尔森相关系数),常用 r 表示:
r = ∑ i = 1 n ( X i − X ‾ ) ( Y i − Y ‾ ) ∑ i = 1 n ( X i − X ‾ ) 2 ∑ i = 1 n ( Y i − Y ‾ ) 2 \begin{aligned} r = \frac { \displaystyle \sum_{i=1}^{n} (X_{i} - \overline{X}) (Y_{i} - \overline{Y}) } { \sqrt{ \displaystyle \sum_{i=1}^{n} (X_{i} - \overline{X})^{2} } \sqrt{ \displaystyle \sum_{i=1}^{n} (Y_{i} - \overline{Y})^{2} } } \end{aligned} r=i=1∑n(Xi−X)2i=1∑n(Yi−Y)2i=1∑n(Xi−X)(Yi−Y)
还可以由(Xi,Yi)样本点的标准分数均值估计得到与上式等价的表达式
r = 1 n − 1 ∑ i = 1 n ( X i − X ‾ σ X) ( Y i − Y ‾ σ Y)\begin{aligned} r = \frac{1}{n-1} \sum_{i=1}^{n}{ (\frac {X_{i} - \overline{X}} {\sigma_{X}} ) (\frac {Y_{i} - \overline{Y}} {\sigma_{Y}} ) } \end{aligned} r=n−11i=1∑n(σXXi−X)(σYYi−Y)
其中,X i − X ‾ σ X \frac {X_{i} - \overline{X}} {\sigma_{X}} σXXi−X 是样本X的标准分数。
(1)
ρ X , Y = c o v ( X , Y ) σ X σ Y = E ( X − μ X ) E ( Y − μ Y ) σ X σ Y = E ( X Y ) − E ( X ) E ( Y ) E ( X 2 ) − E 2 ( X ) E ( Y 2 ) − E 2 ( Y ) \begin{aligned} \rho_{X,Y} = \frac {cov(X,Y)} {\sigma_{X} \sigma_{Y}} = \frac {E(X-\mu_{X}) E(Y-\mu_{Y})} {\sigma_{X} \sigma_{Y}} = \frac {E(XY) - E(X)E(Y)} { \sqrt{E(X^2) - E^{2}(X)} \sqrt{E(Y^2) - E^{2}(Y)} } \end{aligned} ρX,Y=σXσYcov(X,Y)=σXσYE(X−μX)E(Y−μY)=E(X2)−E2(X)E(Y2)−E2(Y)E(XY)−E(X)E(Y)
(2)
ρ X , Y = n ∑ X Y − ∑ X ∑ Y n ∑ X 2 − ( ∑ X ) 2 n ∑ Y 2 − ( ∑ Y ) 2 \begin{aligned} \rho_{X,Y} = \frac {n \sum{XY} - \sum{X}\sum{Y}} { \sqrt{n \sum{X^{2}} - (\sum{X})^{2}} \sqrt{n \sum{Y^{2}} - (\sum{Y})^{2}} } \end{aligned} ρX,Y=n∑X2−(∑X)2n∑Y2−(∑Y)2n∑XY−∑X∑Y
d X , Y =1− ρ X , Y d_{X,Y} = 1 - \rho_{X,Y} dX,Y=1−ρX,Y
import randomimport pandas as pdn = 10000X = [random.nORMalvariate(100, 10) for i in range(n)] # 随机生成服从均值100,标准差10的正态分布序列Y = [random.normalvariate(100, 10) for i in range(n)] # 随机生成服从均值100,标准差10的正态分布序列Z = [i*j for i,j in zip(X,Y)]df = pd.DataFrame({"X":X,"Y":Y,"Z":Z})
import matplotlib.pyplot as plt # 绘制散点图矩阵pd.plotting.scatter_matrix(df)plt.show()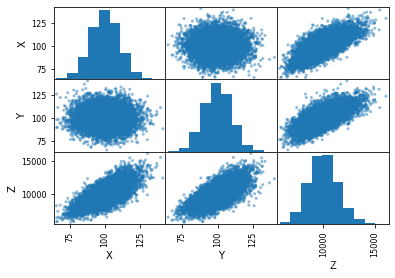
import mathdef PearsonFirst(X,Y): ''' 公式一 ''' XY = X*Y EX = X.mean() EY = Y.mean() EX2 = (X**2).mean() EY2 = (Y**2).mean() EXY = XY.mean() numerator = EXY - EX*EY # 分子 denominator = math.sqrt(EX2-EX**2)*math.sqrt(EY2-EY**2) # 分母 if denominator == 0: return 'NaN' rhoXY = numerator/denominator return rhoXYdef PearsonSecond(X,Y): ''' 公式二 ''' XY = X*Y X2 = X**2 Y2 = Y**2 n = len(XY) numerator = n*XY.sum() - X.sum()*Y.sum() # 分子 denominator = math.sqrt(n*X2.sum() - X.sum()**2)*math.sqrt(n*Y2.sum() - Y.sum()**2) # 分母 if denominator == 0: return 'NaN' rhoXY = numerator/denominator return rhoXY r1 = PearsonFirst(df['X'],df['Z']) # 使用公式一计算X与Z的相关系数r2 = PearsonSecond(df['X'],df['Z']) # 使用公式二计算X与Z的相关系数print("r1: ",r1)print("r2: ",r2)
pandas.corr 函数(无显著性检验)corr(df.corr(method="pearson")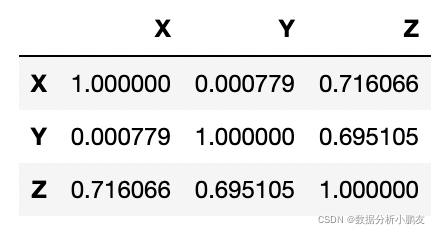
scipy.stats.pearsonr 函数 (有显著性检验)from scipy.stats import pearsonrr = pearsonr(df['X'],df['Z'])print("pearson系数:",r[0])print(" P-Value:",r[1])
pandas.corr 加 scipy.stats.pearsonr 获取相关系数检验P值矩阵def GetPvalue_Pearson(x,y): return pearsonr(x,y)[1]df.corr(method=GetPvalue_Pearson)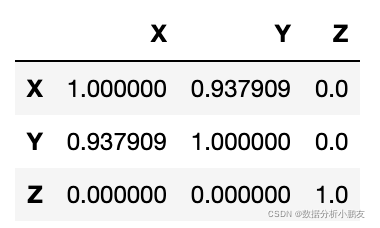
来源地址:https://blog.csdn.net/small__roc/article/details/123519616
--结束END--
本文标题: python 皮尔森相关系数(Pearson)
本文链接: https://www.lsjlt.com/news/385708.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答
一口价域名售卖能注册吗?域名是网站的标识,简短且易于记忆,为在线用户提供了访问我们网站的简单路径。一口价是在域名交易中一种常见的模式,而这种通常是针对已经被注册的域名转售给其他人的一种方式。
一口价域名买卖的过程通常包括以下几个步骤:
1.寻找:买家需要在域名售卖平台上找到心仪的一口价域名。平台通常会为每个可售的域名提供详细的描述,包括价格、年龄、流
443px" 443px) https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294.jpg https://www.west.cn/docs/wp-content/uploads/2024/04/SEO图片294-768x413.jpg 域名售卖 域名一口价售卖 游戏音频 赋值/切片 框架优势 评估指南 项目规模

官方手机版

微信公众号

商务合作




0