一、构造 Http 请求的方式: 基于 HTML / JS (客户端构造HTTP请求,最常见的 HTTP 客户端,就是浏览器) 基于 fORM 表单基于 ajax 基于 Java (这种方案是
form 的重要参数:
action : 构造的 HTTP 请求交给哪个服务器,是一个 URLmethod :构造的 HTTP 请求的 方法 是 GET 还是 POST (form 只支持 GET 和 POST,不区分大小写)光有这一个 form 标签,还没法提交,也没什么东西可提交的
还需要搭配 form 里面有一些其他的标签,比如 input
input 的重要参数:
type : 表示输入框的类型,``text表示文本, passWord 表示密码,submit` 表示提交按钮value : input 标签的值, 对于 type 为 submit 类型来说,value 就对应了按钮上显示的文本name : 不是 id,也不是 class,name 属性与样式无关。 from 表单给服务器提交的数据,本质上是键值对。此处的 name 就表示构造出的 HTTP 请求的 query string 的 key, query string 的 value 就是输入框的用户输入的内容<input type="text" name="username"> <input type="password" name="password"> 假设用户在此处输入的用户名是 zhangsan,密码是 123
此时 form 表单生成的要提交的数据,就形如:username=zhangsan&password=123
光有两个输入框,还不太够,还需要有一个 “提交按钮” submit ,来触发这里的 HTTP 请求
<form action="http://www.soGou.com/index.html" method="get"> <input type="text" name="username"> <input type="password" name="password"> <input type="submit" value="提交">form>此处的 query string 正是页面要提交给服务器的数据:

<form action="http://www.sogou.com/index.html" method="post"> <input type="text" name="username"> <input type="password" name="password"> <input type="submit" value="提交">form>此时就 url 中就没有 name

查看请求:
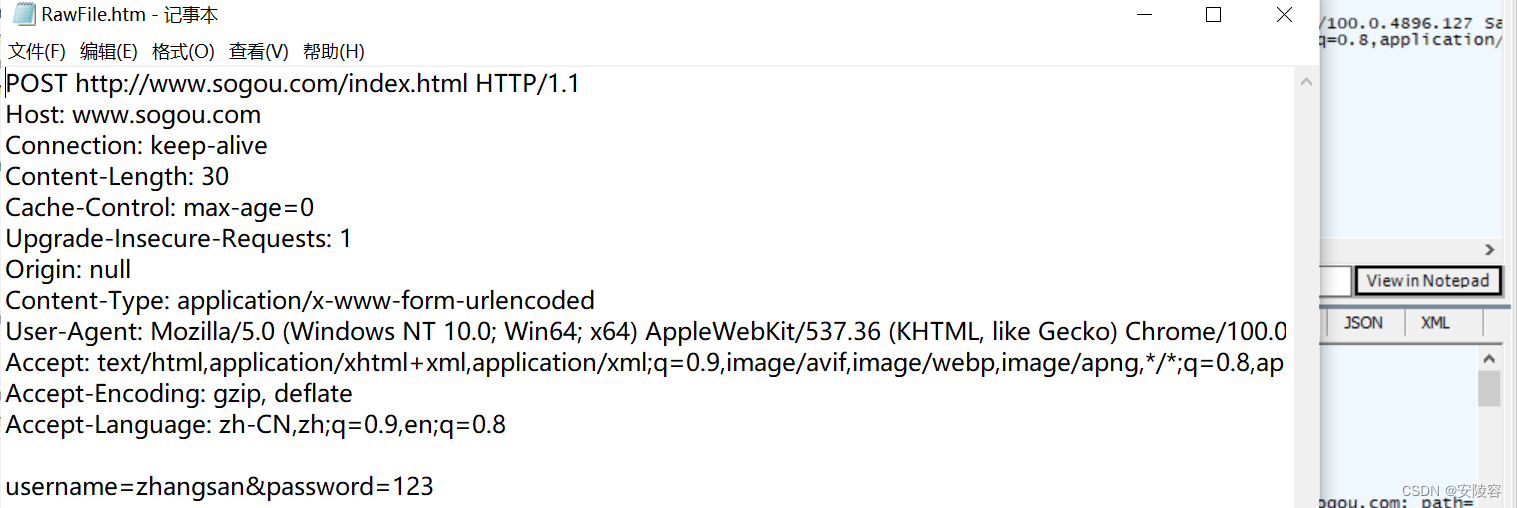
注意: 如果换成 lisi 123,提交还是搜狗的主页,因为当前咱们是把这样的请求直接提交给搜狗主页了,但是搜狗没有处理这样的参数
自己写服务器时,自己的服务器就可以针对前端提交来的参数进行处理,就可以实现一些不同的功能了
form 表单这种方式,是一个更加原始的构造方式,使用 form 一定会涉及到 页面跳转
浏览器需要加载出全新页面
这个事情就是非常的不科学了,尤其是页面非常复杂的时候
随着前端页面越来越复杂,就希望,能够让页面不去整个全部加载,而是只加载其中需要变化的某个小部分
这个情况,就可以使用 ajax 了
在 javascript 中可以通过 ajax 的方式构造 HTTP 请求,再通过 js 代码来处理这里的响应,并且把得到的一些数据给更新到页面上
- ajax 全称
Asynchronous Javascript And XML, 是 2005 年提出的一种 JavaScript 给服务器发送 HTTP 请求的方式- 特点是可以不需要 刷新页面/页面跳转 就能进行数据传输
异步概念,是计算机中,非常常见的一个概念。此处说的 同步 和 加锁 处所说的同步不是一个同步,一个计算机术语,在不同的上下文中,表示的意思,是可能不同的
比如和女朋友出去玩,约好了时间,我先到了,先等着她,这里的等待,这个就是一种 同步 的等待,我是调用者,女朋友是被调用者,调用者会一直在这里等着,主动来获取到被调用者的结果
异步 的等待 ,我就直接给她说,我找个凉快地方玩会手机,一会你下来了给我打电话,调用者发起一个调用请求之后,就不管了,等到被调用者结果出来之后,会主动来通知调用者
同步等待中:
- 阻塞式地等 (不见不散)
- 非阻塞式地等 (每隔一段时间,去查询一下结果)
再比如我去吃饭,来到店里:老板,来个蛋炒饭
同步阻塞等待:
我就蹲在前台这里,盯着后厨来做饭,直到饭做好,我自己端走
同步非阻塞等待:
我在前台这看一眼,发现饭没做好,我出去溜达一圈,
过一会又来到前台这里看,发现饭还是没做好,我去玩会手机… 经过若干次之后,发现饭好了,自己端走
异步等待:
一我就直接啥都不管了,就找个角落左下,玩手机,该干啥干啥,
筹到饭好了之后,人家直接给我端上来了
2 和 3 这两种方式,都是属于等的过程中可以干别的事情的,
区别就在于 第 2 种方式对于调用者来说开销要更大 (反复去查询结果),第 3 种方式往往是更优的
在 IO 的场景中,经常会涉及到这三种情况
IO 就包含,你通过 控制台输入输出 / 通过文件输入输出 / 通过网络输入输出
Scanner,输入流对象输出流对象,默认都是同步阻塞等待
Ajax 使用的是 异步等待
- 同步和异步 :区别主要就是看这个结果是调用者主动关注,还是被调用者来给调用者通知
- 阻塞和非阻塞 :区别是等的过程中,能不能干别的事情
Ajax 就是属于基于异步等待的方式来进行的
这是通过原生 JS 的 ajax 来构造请求并处理响应的,原生的写法非常麻烦,也比较抽象,不好理解
使用一个更加简单,也更好理解的方,基于 jQuery 中的 ajax 来演示相关代码
Jquery 是 JS 世界中,最知名的库 (没有之一), jQuery 在 js 中地位,相当于 spring 在 Java 中的地位
曾经的地位,最近几年 jQuery 的风头被 JS 新生的一些框架给抢走了不少,Vue,React,Angela 这三大框架

引入 jquery :
http://libs.baidu.com/jquery/2.0.0/jquery.min.js
使用 jquery 的 ajax : $
变量名 . js 允许 $ 作为变量名的一部分,这个 $ 就是 jquery 中最核心的对象,jquery 的各种 api,都是通过 $ 来触发的
$.ajax ({});通过 $ 对象来调用 ajax 函数,参数只有一个,但是是一个 “对象”
对象中的取值:
type :表示 HTTP 请求的方法,不仅仅支持 GET 和 POST,也支持 PUT,DELETE 等其他方法url :HTTP 请求的 urlsuccess :对应一个回调函数,这个回调函数会在正确获取到 HTTP 响应之后,调用,就是异步的过程ajax 参数这里还可以有一些其他的值: jQuery ajax - ajax() 方法
<script src="jquert.js"></script><script> $.ajax ({ type: 'get', url: 'http;//www.sogou.com/index.html', success: function(body) { // 回调函数的参数就是 HTTP 响应的 body 部分 console.log("获取到响应数据!" + body); }, error: function() { // error 也对应一个回调函数 会在请求失败后触发 也是异步 console.log("获取响应失败!"); } });</script>刚才 ajax 请求,通过抓包看到,响应里面是 200 OK,并且 body 也是 html 数据
但是浏览器仍然认为这是一个 “出错” 的请求

出现这个报错的原因,是浏览器禁止 ajax 进行跨域访问 ,跨越多个域名 / 多个服务器
当前页面处在的服务器,是本地文件,页面中 ajax 请求的 URL,域名是 www.sogou.com
当前页面处在的服务器,就是在 www.sogou.com中。页面中再通过 ajax 请求 URL,域名为 www.sogou.com 这种就不算跨域
上述行为是浏览器给出的限制 ,当然,我们也是有办法绕过这个限制的
如果对方服务器返回的响应中带有相关的响应头,允许跨域操作,就是可以正常被浏览器显示的
因此,当下咱们构造的 ajax 请求是无法被正确处理的,什么时候才能正确处理?就需要咱们自己有一个服务器,让页面和 ajax 的地址都是这一个服务器,就行了
java 构造一个 HTTP 请求,主要就是基于 tcp socket,按照 HTTP 请求的报文格式,构造出一个匹配的字符串,再写入 socket 即可
在实际开发中,确实也会有一些基于 java 构造 http 请求的情况,可以直接基于第三方库来实现,不一定非得是直接使用 socket
import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;import java.net.Socket;public class HttpClient { private Socket socket; private String ip; private int port; public HttpClient(String ip, int port) throws IOException { this.ip = ip; this.port = port; socket = new Socket(ip, port); } public String get(String url) throws IOException { StringBuilder request = new StringBuilder(); // 构造首行 request.append("GET " + url + " HTTP/1.1\n"); // 构造 header request.append("Host: " + ip + ":" + port + "\n"); // 构造 空行 request.append("\n"); // 发送数据 OutputStream outputStream = socket.getOutputStream(); outputStream.write(request.toString().getBytes()); // 读取响应数据 InputStream inputStream = socket.getInputStream(); byte[] buffer = new byte[1024 * 1024]; int n = inputStream.read(buffer); return new String(buffer, 0, n, "utf-8"); } public String post(String url, String body) throws IOException { StringBuilder request = new StringBuilder(); // 构造首行 request.append("POST " + url + " HTTP/1.1\n"); // 构造 header request.append("Host: " + ip + ":" + port + "\n"); request.append("Content-Length: " + body.getBytes().length + "\n"); request.append("Content-Type: text/plain\n"); // 构造 空行 request.append("\n"); // 构造 body request.append(body); // 发送数据 OutputStream outputStream = socket.getOutputStream(); outputStream.write(request.toString().getBytes()); // 读取响应数据 InputStream inputStream = socket.getInputStream(); byte[] buffer = new byte[1024 * 1024]; int n = inputStream.read(buffer); return new String(buffer, 0, n, "utf-8"); } public static void main(String[] args) throws IOException { HttpClient httpClient = new HttpClient("42.192.83.143", 8080); String getResp = httpClient.get("/AjaxMockServer/info"); System.out.println(getResp); String postResp = httpClient.post("/AjaxMockServer/info", "this is body"); System.out.println(postResp); }}使用 Java 构造的 HTTP 客户端不再有 “跨域” 限制了,此时也可以用来获取其他服务器的数据了
跨域只是浏览器的行为,对于 ajax 有效,对于其他语言来说一般都和跨域无关
HttpClient httpClient = new HttpClient("www.sogou.com", 80);String resp = httpClient.get("/index.html");System.out.println(resp);// 此时可以获取到 搜狗主页 的 html标准的http请求报文头中,以下哪个说法是正确的(ABCD)
- A.User-Agent: 声明用户的操作系统和浏览器版本信息
- B.Content-Type: 数据类型
- C.Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上
- D.location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问
HTTPS 也是一个应用层协议, HTTPS相当于HTTP的孪生兄弟,是在 HTTP 协议的基础上引入了一个加密层
HTTP 协议内容都是按照文本的方式明文传输的,这就导致在传输过程中出现一些被篡改的情况
臭名昭著的 "运营商劫持:
下载一个 天天动听
未被劫持的效果,点击下载按钮,就会弹出天天动听的下载链接
已被劫持的效果,点击下载按钮,就会弹出 QQ 浏览器的下载链接

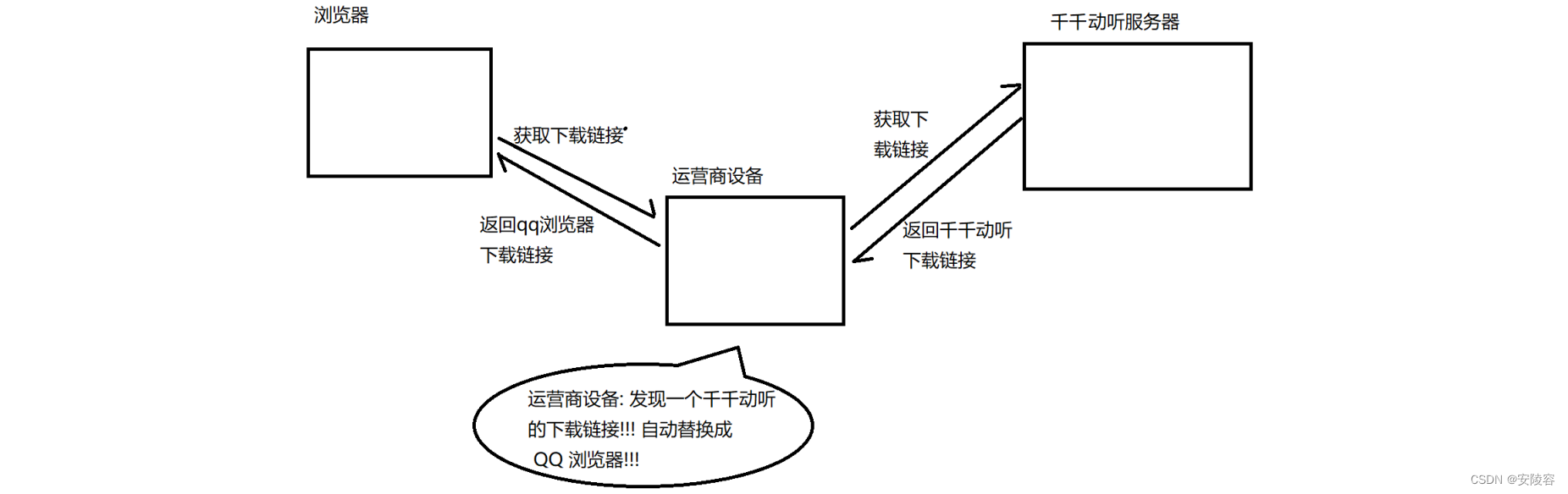
不止运营商可以劫持,其他的 黑客 也可以用类似的手段进行劫持,来窃取用户隐私信息,或者篡改内容
试想一下,如果黑客在用户登陆支付宝的时候获取到用户账户余额,甚至获取到用户的支付密码…
在互联网上,明文传输是比较危险的事情!!!
HTTPS 就是在 HTTP 的基础上进行了加密,进一步的来保证用户的信息安全
加密就是把 明文 (要传输的信息)进行一系列变换,生成 **密文 **
解密就是把 密文 再进行一系列变换,还原成 明文
在这个加密和解密的过程中,往往需要一个或者多个中间的数据,辅助进行这个过程,这样的数据称为 密钥 (正确发音 yue 四声,不过大家平时都读作 yao 四声,或 shi 二声)
加密解密到如今已经发展成一个独立的学科:密码学
密码学的奠基人,也正是计算机科学的祖师爷之一,艾伦·麦席森·图灵

对比我们另一位祖师爷冯诺依曼

图灵年少有为,不光奠定了计算机, 人工智, 密码学的基础,并且在二战中大破德军的 Enigma 机,使盟军占尽情报优势,才能扭转战局反败为胜,但是图灵遭到英国皇室的迫害,享年 41 岁,电影《模仿游戏》讲述的就是图灵
计算机领域中的最高荣誉就是以他名字命名的 “图灵奖”
83 版 <<火烧圆明园>>, 有人要谋反干掉慈禧太后,恭亲王奕䜣(洋务派代表人物之一) 给慈禧递的折子,折子内容只是扯一扯家常,套上一张挖了洞的纸就能看到真实要表达的意思
明文:要传输的原始信息,“当心肃顺,端华,戴恒” ,(肃顺、端华、戴桓三人是老皇帝驾崩前任命的辅政大臣,后来被慈禧一锅端了)
密文:奏折全文,即使被别人获取到了,拿着密文,也看不出什么
密钥:通过密钥,把明文,转成密文,或者是把密文还原成明文,这里就是带有窟窿的纸
加密和解密这个事情,本身是一个和数学密切相关的事情
咱们此处,只能简单讨论"流程",无法讨论加密解密的 “实现细节”
加密之后,也不是就绝对安全,只是说破解起来计算量很大,成本很高
有些数据经过加密之后,哪怕使用当前最牛的计算机,破解起来也需要个几十年,上百年的,这种就认为是安全的
只要破解成本高于数据本身的价值,就是安全的
(有个团伙,造假钞,造的贼好,以至于验钞机根本区分不出来… 但是造一个100块钱的假钞,实际成本,是110块钱…)
HTTPS 中引入的加密层,称为 SSL (旧的叫法) / TLS (新的叫法)
在SSL里面,涉及到的加密操作,其实主要是两种方式:
对称加密其实就是通过同一个 “密钥”,把明文加密成密文,并且也能把密文解密成明文
一个简单的对称加密,按位异或
- 假设 明文 a = 1234, 密钥 key = 8888
- 则加密 a ^ key 得到的密文 b 为 9834.
- 然后针对密文 9834 再次进行运算 b ^ key, 得到的就是原来的明文 1234.
- (对于字符串的对称加密也是同理, 每一个字符都可以表示成一个数字)
- 当然,按位异或只是最简单的对称加密. HTTPS 中并不是使用按位异或.
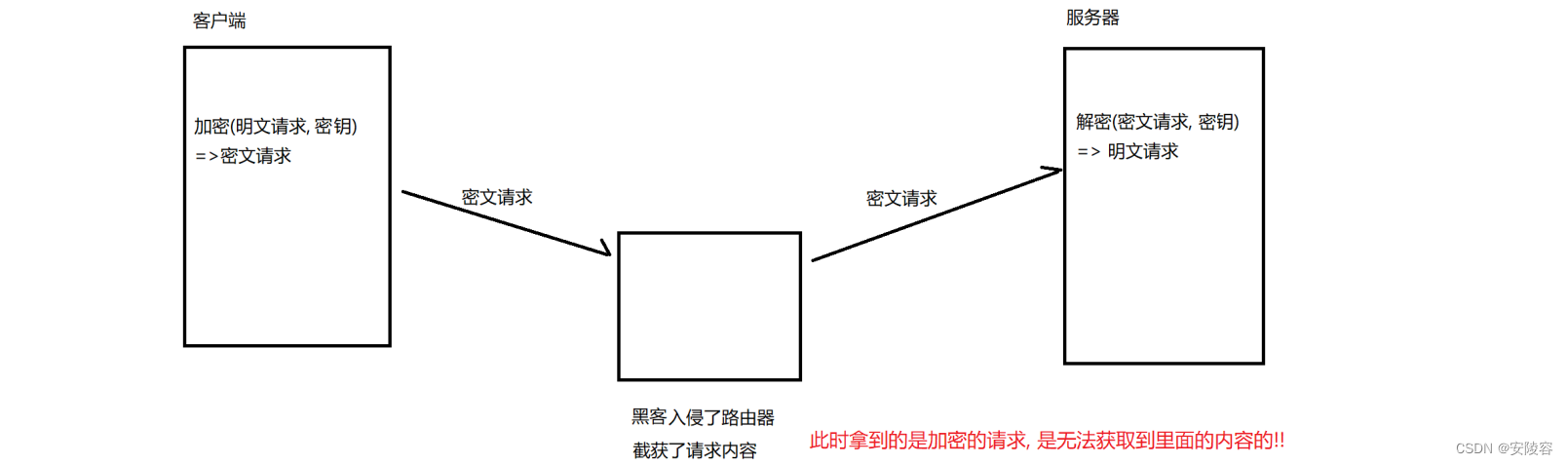
客户端和服务器持有同一个密钥
客户端传输的数据 (HTTP 请求的 header 和 body) 都通过这个密钥进行对称加密,实际在网络上传输的是密文
服务器收到密文之后,接下来就可以根据刚才的密钥,来进行解密,拿到明文
上面的这个过程,看起来挺美好的,但是存在一个致命缺陷
如何保证 客户端 和 服务器,持有同一个密钥?? 尤其是一个服务器,对应很多很多客户端的时候
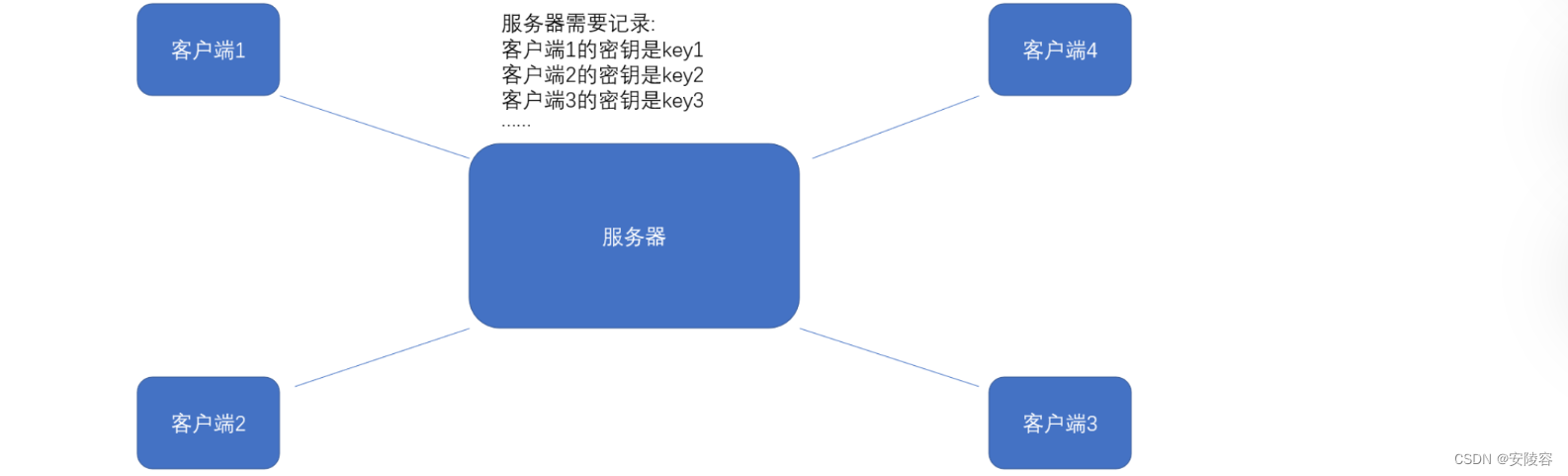
显然,必须是不同客户端用不同密钥,才行
如果各个客户端都是同一个密钥,这个密钥就太容易被黑客拿到了 (黑客只要自己启动一个客户端…)
既然需要是不同的密钥,就需要让服务器能够记录,不同的客户端的密钥都是什么
而且得让客户端和服务器之间能够传递这个密钥
因为需要不同的客户端有不同的密钥,要么是客户端主动生成一个密钥,告诉服务器,要么是服务器生成一个密钥,告诉客户端,需要把这个密钥,通过网络进行传递的
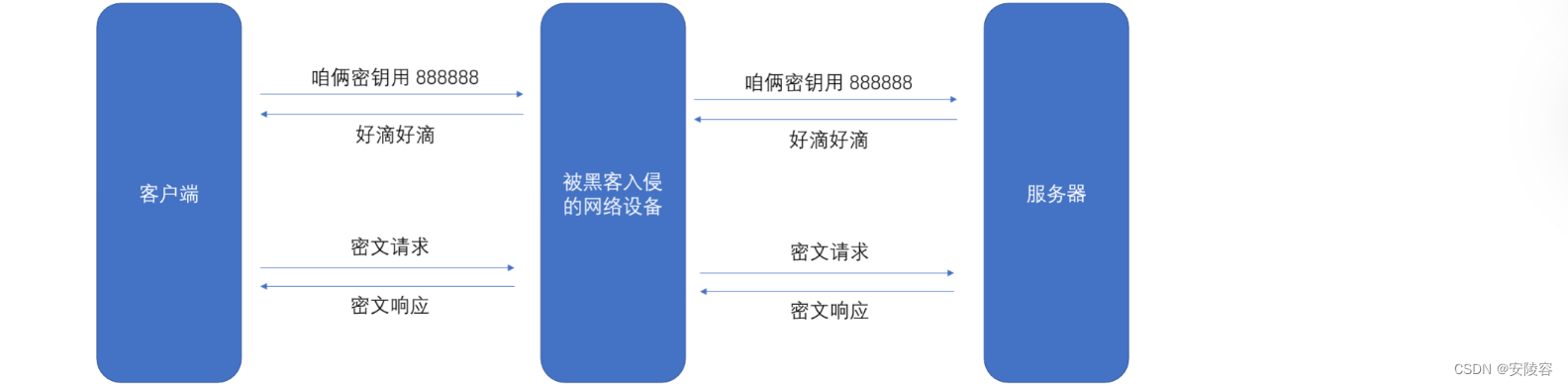
这个图里,是假设客户端生成的密钥,客户端就需要把密钥通过网络告诉服务器
客户端生成了密钥,888888,客户端就得告诉服务器,咱们的密钥是888888
由于设备可能早就被黑客入侵了
密钥是啥,如果明文传输,也就很容易被黑客拿到了,如果黑客知道了你的密钥,后面咋加密,都是形同虚设了
经过上述讨论,就明确了,使用对称加密,最大的问题,在于说密钥得能够传递过去,如果明文传递,是不行的,必须针对这个密钥再进行加密
这里解决问题的关键,就是需要引入,非对称加密了
非对称加密,有两个密钥,分别叫做公钥和私钥
公钥,就是人人都能获取到
私钥,就是只有自己才知道
就可以使用公钥来加密,使用私钥来解密
或者,使用私钥加密,使用公钥解密
直观上理解公钥私钥:
- 很多小区,单元门口,有一个 “信箱”
- 你有一把钥匙,和很多把锁头,你把这些锁头发给送信小哥
- 每个送信的小哥都可以凭这个锁头,把信锁到你的信箱里,只有你自己持有着这把钥匙,能够开箱,拿出信
- 此处锁头,就相当于公钥,你自己手里的钥匙,就是私钥
基于非对称加密,就可以让服务器自己生成一对公钥和私钥,公钥发出去(人人都能拿到),私钥自己保存
客户端生成一个对称密钥,客户端就可以使用服务器的公钥,对对称密钥进行加密,然后把数据传给服务器,服务器再通过私钥进行解密
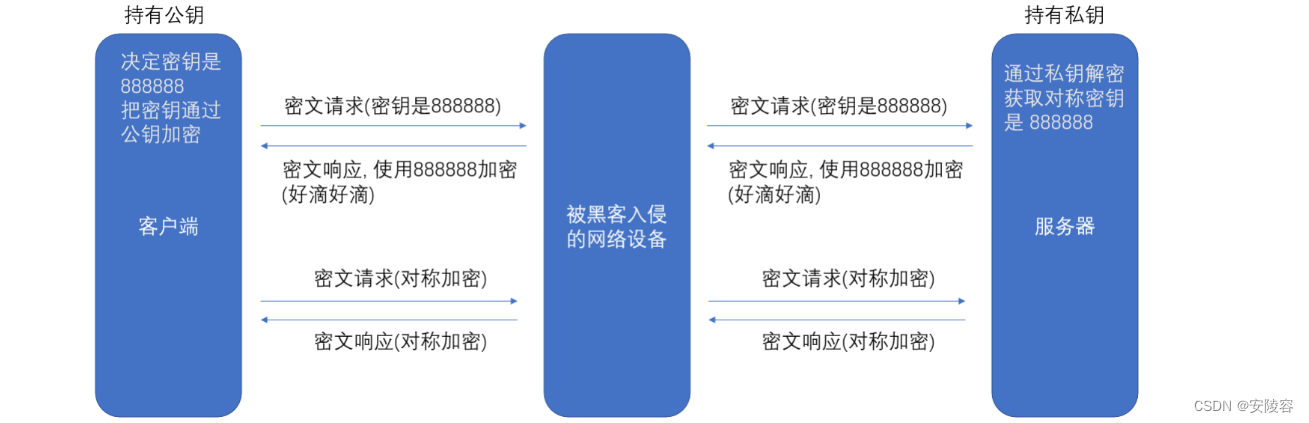
服务器自己持有私钥,客户端持有公钥,黑客可以拿到公钥,但是拿不到私钥
客户端生成了对称密钥,就可以基于刚才的公钥,对对称密钥进行加密
如果黑客拿到了这个密文,那么此时由于黑客没有私钥,是不能进行解密的,也就不知道对称密钥是啥
既然非对称加密这么好使,还要对称加密干啥?? 直接非对称加密一把梭就行了呗??
- 实际实现中,对称加密的计算开销 << 非对称加密
- 如果只是少来少去的,用用这个非对称加密,成本还好
- 但是如果所有数据都走非对称加密,这个事就成本太大了
上述过程看起来好像很完美了,其实不然。这里仍然存在一个非常巨大的漏洞!!!
服务器要把自己的公钥返回给客户端在这个操作中,就可能会涉及到一个非常经典的 “中间人攻击”
正常的情况:
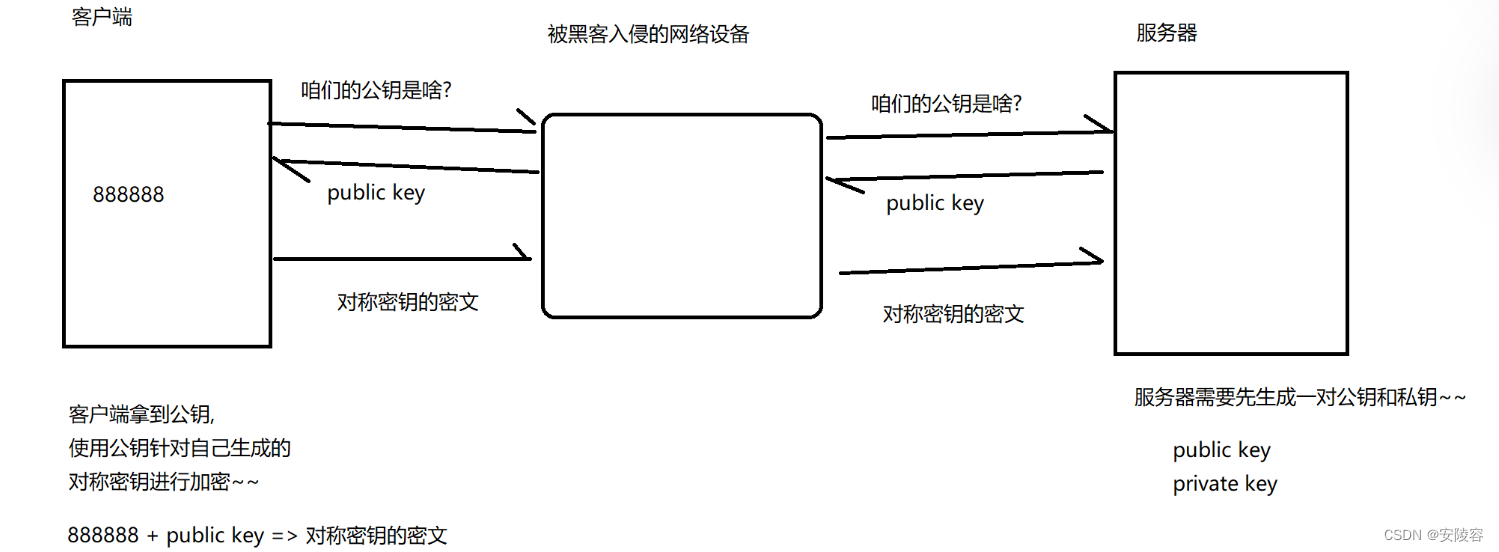
中间人攻击:
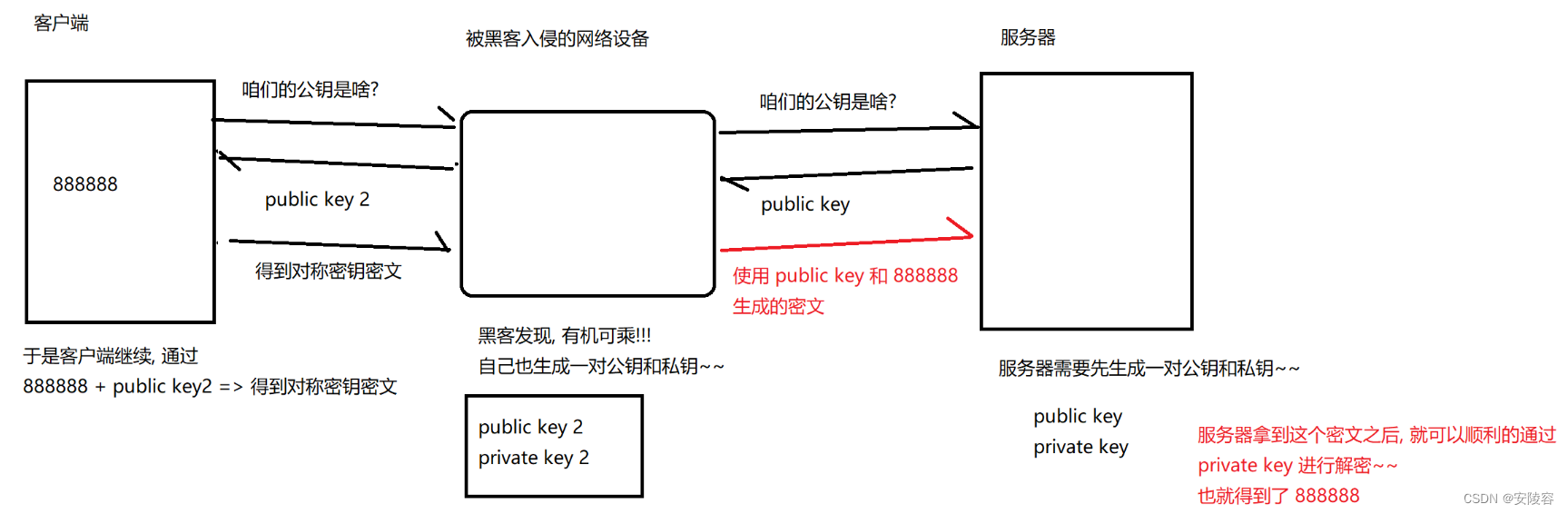
中间人攻击的关键,是黑客自己也生成一对公钥私钥
拦截到 服务器给客户端返回的公钥,用自己生成的公钥,替换之
黑客拦截到对称密钥的密文之后,由于这个密文是使用 public key2 来进行加密的!! 因此黑客就可以使用 private key2 进行解密!!! 黑客就拿到了对称密钥,888888
紧接着,黑客为了隐藏自己,把 888888 再使用之前从服务器拿到的 public key 进行加密,得到了另外一个密文,返回给服务器
既然存在中间人攻击,如何解决这个问题??
关键要点,得让客户端能够确认,当前的公钥,确实是来自于服务器,而不是由黑客伪造的
想想看,生活中其他场景是怎么验证的???
例如,你去网吧,或者去住小旅馆,需要进行身份登记
- 如何验证你的身份? 你有身份证
- 网管就会拿着你的身份证刷一下,这一刷,其实就是在访问公安局的相关服务器,验证你的身份信息
- 因此,就需要引入一个第三方公信机构,来证明这个公钥是一个合法的公钥
- 因为咱们是信任这个公信机构的 (就像咱们信任 jc 一样),公信机构说这个公钥 ok,我们就可以认为这个公钥可信!!!
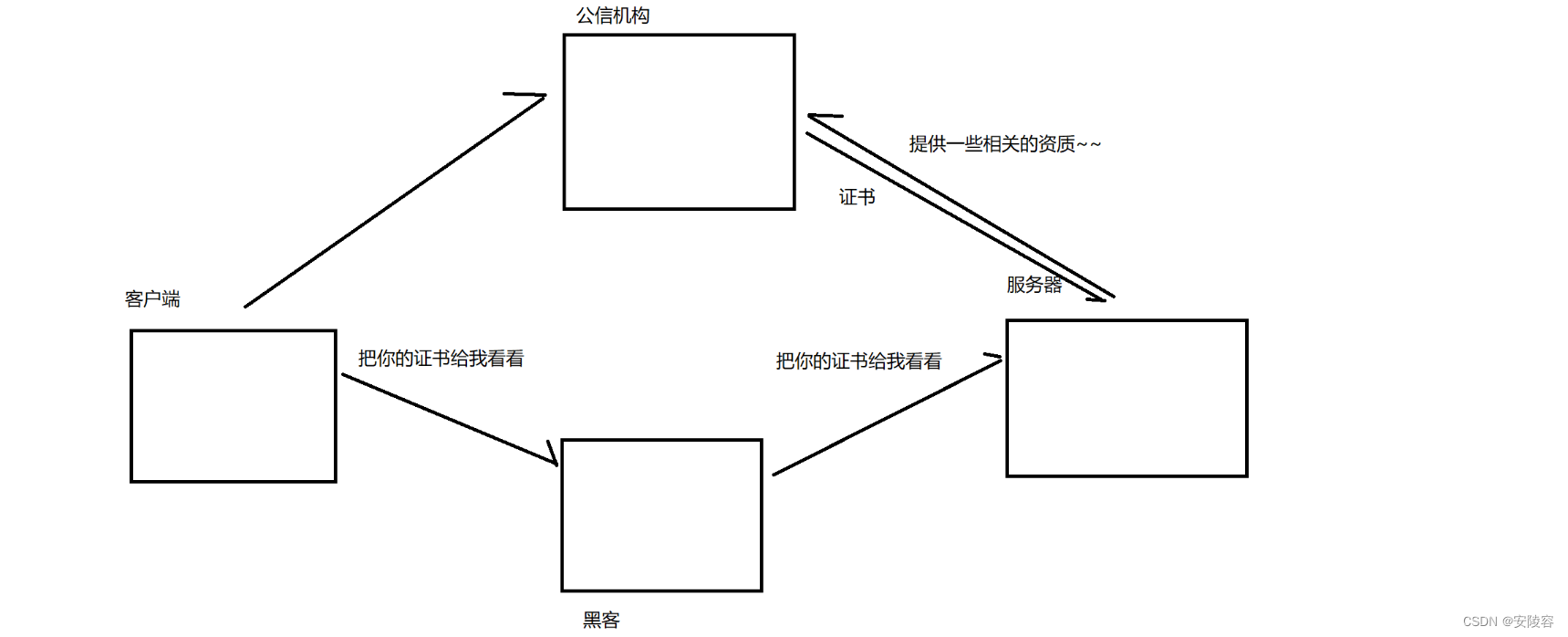
服务器在最开始上线的时候,就需要先去 CA机构 这里,申请一个证书!!
然后服务器自己生成的公钥,就放在这个证书中 (就是一段数据)
在客户端和服务器刚一建立连接的时候,服务器给客户端返回一个 证书,这个证书包含了刚才的公钥,也包含了网站的身份信息
这个 证书 可以理解成是一个结构化的字符串,里面包含了以下信息:
- 证书发布机构
- 证书有效期
- 公钥
- 证书所有者
- 签名
- …
客户端这里黑客也是有可能会伪造证书的,
当客户端获取到这个证书之后,会对证书进行校验 (防止证书是伪造的)
客户端如何验证这个证书是否合理?
证书上自身有一些校验机制
向公信机构进行求证
如果是黑客伪造了证书,此时就会露馅,于是浏览器就会弹框警报
- 判定证书的有效期是否过期
- 判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构)
- 验证证书是否被篡改: 从系统中拿到该证书发布机构的公钥, 对签名解密, 得到一个 hash 值(称为数据摘要), 设为 hash1. 然后计算整个证书的 hash 值, 设为 hash2. 对比 hash1 和 hash2 是否相等.
如果相等, 则说明证书是没有被篡改过的
如果每次都访问这个公信机构来求证,是不是太麻烦了呀?
确实如此,实际上,客户端自身就会包含一些公信机构的信息 (内置在操作系统里)
不需要通过服务器网络请求,直接本地就能进行认证 (这就好像一个非常牛的网吧,直接公安局派了一个 jc 长期驻扎在这里)
以上描述的东西都是包含在 SSL 中的,SSL 不仅仅是应用于HTTPS,很多其他地方也会用到 SSL
这整个的加密过程,预期说是去防止数据被拦截,不如说更重要是防止数据被篡改
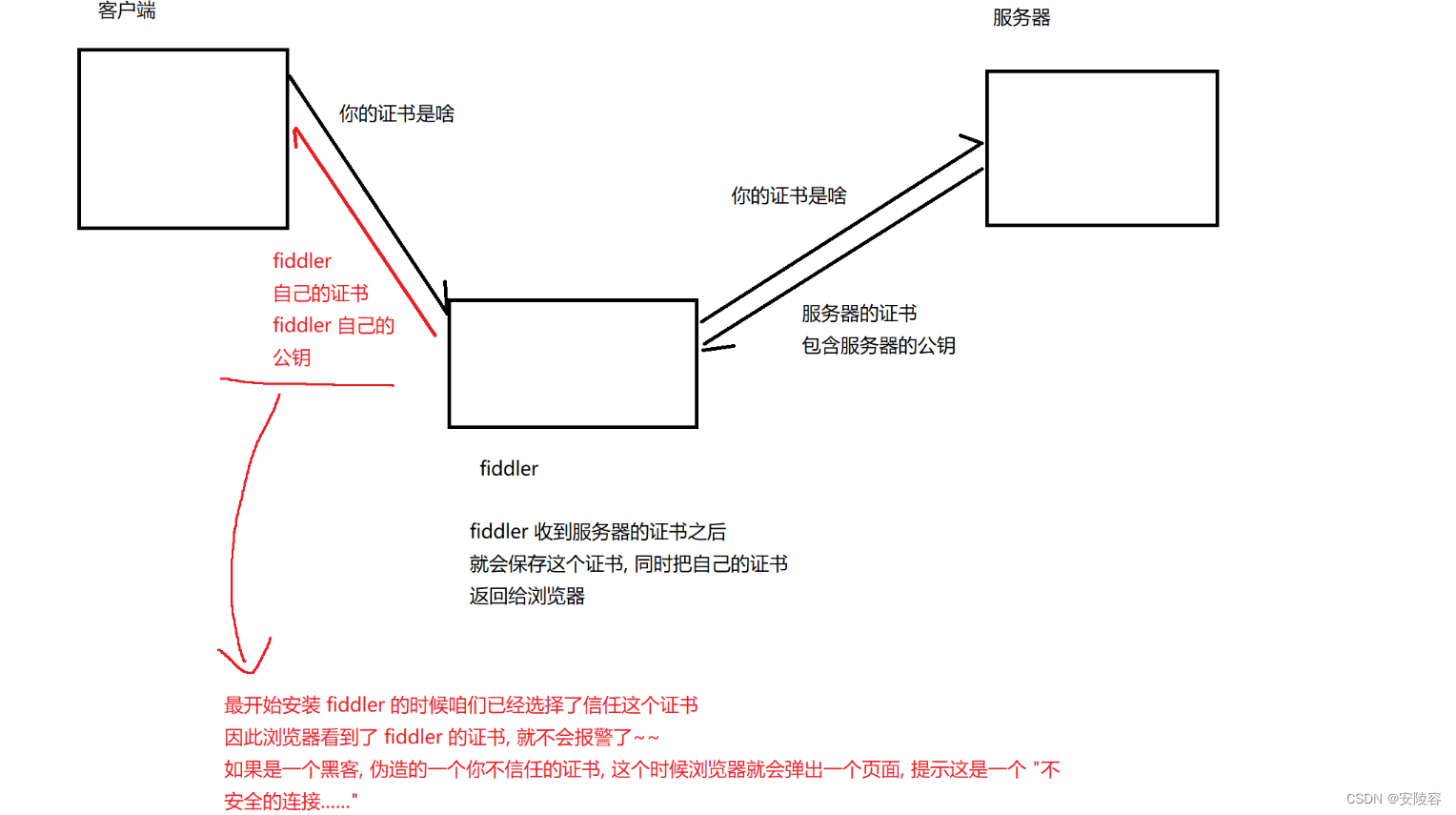
既然 HTTP 数据已经经过了加密了,为啥 fiddler 仍然能抓到并解析 HTTPS里的数据报?
- 之所以 fiddler 能抓包,是和咱们安装fiddler之后,第一次启用HTTPS功能时候,弹出的那个对话框密切相关的!!!
- 点是操作,其实就是让操作系统能够信任fiddler提供的证书
- 相当于用户给fiddler授权了,允许fiddler进行“中间人攻击"
查看浏览器的受信任证书发布机构:
Chrome 浏览器, 点击右上角的 选择 “设置”, 搜索 “证书管理” , 即可看到以下界面
理解数据摘要 / 签名:
以后我们参加工作后, 经常会涉及到 “报销” 的场景. 你拿着发票想报销, 需要领导批准. 但是领导又
不能和你一起去找财务. 那咋办?很简单, 领导给你签个字就行了. 财务见到领导的签字, “见字如见人”.
因为不同的人, “签名” 的差别会很大. 使用签名就可以一定程度的区分某个特定的人.类似的, 针对一段数据(比如一个字符串), 也可以通过一些特定的算法, 对这个字符串生成一个 “签
名”. 并保证不同的数据, 生成的 “签名” 差别很大. 这样使用这样的签名就可以一定程度的区分不同的数据.常见的生成签名的算法有: MD5 和 SHA 系列
以 MD5 为例, 我们不需要研究具体的计算签名的过程, 只需要了解 MD5 的特点:定长: 无论多长的字符串, 计算出来的 MD5 值都是固定长度 (16字节版本或者32字节版本)
分散: 源字符串只要改变一点点, 最终得到的 MD5 值都会差别很大.
不可逆: 通过源字符串生成 MD5 很容易, 但是通过 MD5 还原成原串理论上是不可能的.
正因为 MD5 有这样的特性, 我们可以认为如果两个字符串的 MD5 值相同, 则认为这两个字符串相同
理解判定证书篡改的过程 : (这个过程就好比判定这个身份证是不是伪造的身份证)
假设我们的证书只是一个简单的字符串 hello, 对这个字符串计算hash值(比如md5), 结果为
BC4B2A76B9719D91如果 hello 中有任意的字符被篡改了, 比如变成了 hella, 那么计算的 md5 值就会变化很大.
BDBD6F9CF51F2FD8然后我们可以把这个字符串 hello 和 哈希值 BC4B2A76B9719D91 从服务器返回给客户端, 此时
客户端如何验证 hello 是否是被篡改过?那么就只要计算 hello 的哈希值, 看看是不是 BC4B2A76B9719D91 即可
但是还有个问题, 如果黑客把 hello 篡改了, 同时也把哈希值重新计算下, 客户端就分辨不出来了呀
所以被传输的哈希值不能传输明文, 需要传输密文.
这个哈希值在服务器端通过另外一个私钥加密(这个私钥是申请证书的时候, 证书发布机构给服务
器的, 不是客户端和服务器传输对称密钥的私钥).然后客户端通过操作系统里已经存的了的证书发布机构的公钥进行解密, 还原出原始的哈希值, 再
进行校验.
来源地址:https://blog.csdn.net/qq_56884023/article/details/125121614
--结束END--
本文标题: 构造 HTTP 请求的方式、HTTPS 的工作过程
本文链接: https://www.lsjlt.com/news/408635.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作



0