一. 前言 当Mysql单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化。 二. 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种
当Mysql单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化。
除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度,一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的。而事实上很多时候mysql单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量。
索引并不是越多越好,要根据查询有针对性的创建,考虑在WHERE和ORDER BY命令上涉及的列建立索引,可根据EXPLaiN来查看是否用了索引还是全表扫描
可通过开启慢查询日志查找出较慢的SQL。
SELECT id WHERE age+1=10!= <>操作,否则将导致引擎放弃索引使用全表扫描BETWEEN而不用IN目前广泛使用的是MyISAM引擎和InnoDB两种引擎。
MyISAM适合SELECT密集型的表,不支持事务。
InnoDB适合insert和update密集型的表,支持事务。
也是目前常用的优化,从库读主库写,一般不要采用双主或多主引入很多复杂性,尽量采用文中的其他方案来提高性能。同时目前很多拆分的解决方案同时也兼顾考虑了读写分离。
MySQL数据库 + Docker主从同步搭建配置:https://blog.csdn.net/qq_43030934/article/details/129669236
Django+Docker实现MySQL读写分离基本使用介绍:https://blog.csdn.net/qq_43030934/article/details/129671074
缓存可以发生在这些层次:
分库分表的中心思想都是将数据分散存储,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
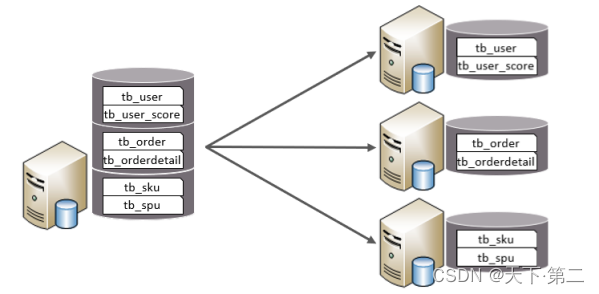
以表为依据,根据业务将不同表拆分到不同库中。所以拆分完的每个库的表结构都不一样。每个库的数据也不一样。所有库的并集是全量数据。
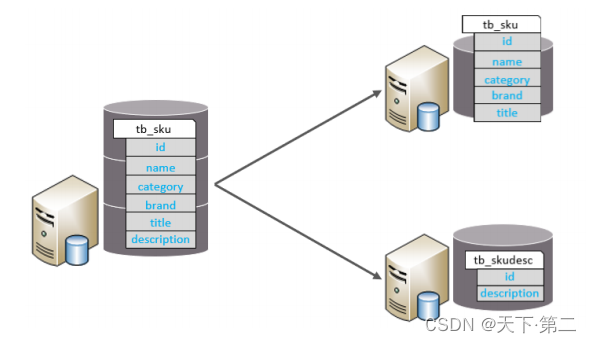
以字段为依据,根据字段属性将不同字段拆分到不同表中。并且每个表的结构都不一样。每个表的数据也不一样,一般通过一列(主键/外键)关联。所有表的并集是全量数据。
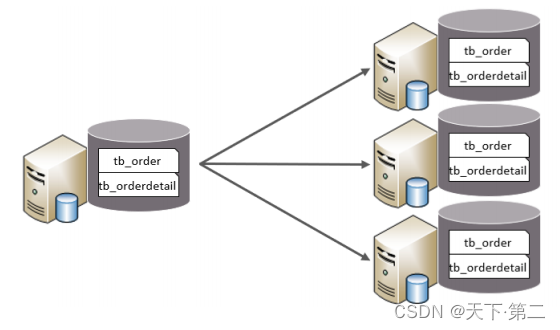
以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。在水平分库中每个库的表结构都一样。每个库的数据都不一样。所有库的并集是全量数据。
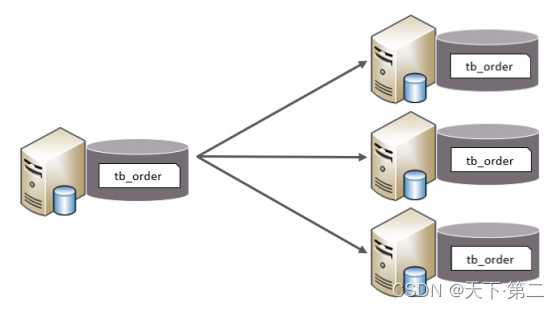
以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。特点:每个表的表结构都一样。每个表的数据都不一样。所有表的并集是全量数据。
在业务系统中,为了缓解磁盘io及CPU的性能瓶颈,到底是垂直拆分,还是水平拆分;具体是分库,还是分表,都需要根据具体的业务需求具体分析。
Scale up,这个不多说了,根据MySQL是CPU密集型还是I/O密集型,通过提升CPU和内存、使用SSD,都能显著提升MySQL性能。
来源地址:https://blog.csdn.net/qq_43030934/article/details/131288829
--结束END--
本文标题: MySQL - 单表数据量大表优化方案
本文链接: https://www.lsjlt.com/news/422032.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0