Python 官方文档:入门教程 => 点击学习
【HSI】高光谱的数据集分类深度学习实战及代码理解 文章目录 【HSI】高光谱的数据集分类深度学习实战及代码理解一、配置文件编写二、高光谱图像的处理2.1图像数据变换2.2 数据整合2.3 数
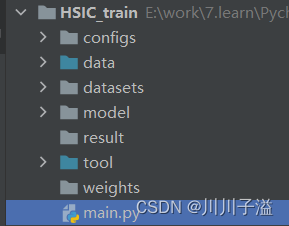
在不同的文件下面进行相应的编写,同时便于阅读和后续的修改和移植性的提高
datasets_type = 'HSI Data Sets'data_root = '/home/students/master/2022/wangzy/PyCharm-Remote/HSIC_train/datasets/PaviaU.mat'image_name = 'paviaU'gt_name = 'paviaU_gt' # 在数据库上标注好的label一般被默认为是真实的值,也就是GT了phase = ['train', 'test', 'no_gt']pca_num = 1train_set_num = 30patch_size = 27data = dict( data_path=data_root, image_name=image_name, gt_name=gt_name, train_set_num=train_set_num, patch_size=patch_size, pca=pca_num, train_data=dict( phase=phase[0] ), test_data=dict( phase=phase[1] ), no_gt_data=dict( phase=phase[2] ))train = dict( # 优化器的相应数据 optimizer=dict( typename='SGD', lr=lr, momentum=0.9, # 动量 weight_decay=1e-4 # 权重衰减 ), train_model=dict( gpu_train=True, gpu_num=1, workers_num=16, epoch=100, batch_size=32, # 学习率的相应参数 lr=lr, lr_adjust=True, lr_gamma=0.1, lr_step=60, save_folder='./weights/', save_name='model_CNN1D', reuse_model=False, reuse_file='./weights/model_CNN1D_Final.pth' ))test = dict( batch_size=1000, gpu_train=True, gpu_num=1, workers_num=16, model_weights='./weights/model_CNN1D_Final.pth', save_folder='./result')配置文件的编写主要是为了,在后续调整模型时,方便修改相应的数据参数,常用的使用和调整的包含了:
data_root = '/home/students/master/2022/wangzy/PyCharm-Remote/HSIC_train/datasets/PaviaU.mat' #高光谱数据集lr = 1e-2#学习步长pca_num = 1#高光谱图像PCA后的通道数train_set_num = 30#训练的次数patch_size = 27#对高光谱数据集划分patch的尺寸 27*27epoch=100,#epoch的次数batch_size=32,#图像的数量在训练模型调参时,基本的改动都在configs的文件中来进行修改
在现在的处理中,主要时mat文件的导入,一张图像的数据大体上分为了[W,H,C],长宽和通道数,以paviaU数据集来进行举例,torch([32, 103, 610, 340]),大约包含了这些参数,32为图片数量,103的通道数和[610,340]的长宽
对原始图像的处理基本分为:
可以根据自己对图像处理的需求来构建相应的子函数
(1)图像数据归一化
def one_zero_nORM(image): channel, height, width = image.shape data = image.view(channel, height * width) data_max = data.max(dim=1)[0] data_min = data.min(dim=1)[0] data = (data - data_min.unsqueeze(1)) / (data_max.unsqueeze(1) - data_min.unsqueeze(1)) # 在第二个维度上插入一个维度 return data.view(channel, height, width)def pos_neg_norm(image): channel, height, width = image.shape data = image.view(channel, height * width) data_max = data.max(dim=1)[0] data_min = data.min(dim=1)[0] data = -1 + 2 * (data - data_min.unsqueeze(1)) / (data_max.unsqueeze(1) - data_min.unsqueeze(1)) return data.view(channel, height, width)def std_norm(image): image = image.permute(1, 2, 0).numpy() trans = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(torch.tensor(image).mean(dim=[0, 1]), torch.tensor(image).std(dim=[0, 1])) ]) return trans(image)根据要求的不同来对图像进行相应的处理
# (x - mean(x))/std(x) normalize to mean: 0, std: 1# (x - min(x))/(max(x) - min(x)) normalize to (0, 1) for each channel# -1 + 2 * (x - min(x))/(max(x) - min(x)) normalize to (-1, 1) for each channel数据的分布范围不同,采用不同的函数
(2)标签转换
def label_transform(gt): ''' function:tensor label to 0-n for training input: gt output:gt tensor([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.]) -> tensor([-1., 0., 1., 2., 3., 4., 5., 6., 7., 8.]) ''' label = torch.unique(gt) # 返回标签label中的不同值 gt_new = torch.zeros_like(gt) # zeros_like(a)的目的是构建一个与a同维度的数组,并初始化所有变量为零。 # zeros,则需要代入参数 for each in range(len(label)): # 长度为10 indices = torch.where(gt == label[each]) if label[0] == 0: gt_new[indices] = each - 1 else: gt_new[indices] = each # tensor([-1., 0., 1., 2., 3., 4., 5., 6., 7., 8.]) # labeL_new = torch.unique(gt_new) return gt_new将标签依次向下减小,将图像的背景label定义为-1,从而使标签信息可以分隔开来
(3)提取PCA图像数据
高光谱的数据通道数太多了,进行空间卷积的话,会受到影响,通过PCA下降后更方便进行2D卷积
def extract_pc(image, pc=3): channel, height, width = image.shape data = image.contiguous().reshape(channel, height * width) # 存在contiguous函数,在改变data的值后 data_c = data - data.mean(dim=1).unsqueeze(1) # 计算一个矩阵或一批矩阵 input 的奇异值分解 u, s, v = torch.svd(data_c.matmul(data_c.T)) # data_c矩阵乘以data_c的转置 sorted_data, indices = s.sort(descending=True) # 将s中的数按降序进行排列 image_pc = u[:, indices[0:pc]].T.matmul(data) return image_pc.reshape(pc, height, width)(4)构建样本和划分训练集,测试集和地图信息
def select_sample(gt, ntr):构建函数用于划分数据集的数量和返回相应的参数
train_num_array = [30, 150, 150, 100, 150, 150, 20, 150, 15, 150, 150, 150, 150, 150, 50, 50]sel_num = train_num_array[each-1]sel_num = torch.tensor(sel_num) # tensor(30)# 将标签进行打乱rand_indices0 = torch.randperm(class_num) # torch.randperm 给定参数n,返回一个从0到n-1的随机整数排列rand_indices = indices_vector[rand_indices0]# 划分训练集train,测试集test# 划分打乱后的随机整数排列tr_ind0 = rand_indices0[0:sel_num] # torch.Size([30])te_ind0 = rand_indices0[sel_num:] # 将剩下的数据用作测试集# 划分随机整数排列对应的gttr_ind = rand_indices[0:sel_num] # torch.Size([30])te_ind = rand_indices[sel_num:]以数组的形式来存储数据集中不同类别的训练集和划分数据集,将相应的数据和指标进行划分来存储和返回
# 将6种数据参数进行保存data_sample = {'train_indices': train_indices, 'train_num': train_num, 'test_indices': test_indices, 'test_num': test_num, 'no_gt_indices': no_gt_indices, 'no_gt_num': no_gt_num.unsqueeze(0) }def get_train_test_set(cfg): # 从cfg中导入设定好的参数 data_path = cfg['data_path'] # 导入存放的地址 image_name = cfg['image_name'] # paviaU # 这个其实就是103通道的整个图像的信息 gt_name = cfg['gt_name'] # 'paviaU_gt' # 这个是地图的特征信息,同时具有标签值 # [0,0,1,1,1,4,4,4,]这种的标签图 train_set_num = cfg['train_set_num'] # 30,每一次数据集训练的次数 patch_size = cfg['patch_size'] # 27,用于切分图像的尺寸 data = io.loadmat(data_path) # 从相应的文件夹导入 img = data[image_name].astype('float32') # .astype转换数组的数据类型 (610, 340, 103) [w,h,c] gt = data[gt_name].astype('float32') # 转换成float32 (610, 340) ,这个数据从数据库中导入,只有一个数据 img = torch.from_numpy(img) # 转tensor # torch.Size(610, 340, 103) gt = torch.from_numpy(gt) # torch.Size(610, 340) img = img.permute(2, 0, 1) # 变换tensor的维度,把channel放到第一维CxHxW # torch.Size(103, 610, 340) img = pre_fun.std_norm(img) # 归一化,torch.Size(103, 610, 340) 将数据分布在(0,1)之间 # label transform 0~9 -> -1~8 # 将标签值进行转换,应该在mat文件中,对不同的物体的label值就做好了定义 img_gt = pre_fun.label_transform(gt) # torch.size(610, 340) # construct_sample:切分patch,储存每个patch的坐标值 # img_pad的值为([103, 636, 366]), # img_pad_indices的值为([207400, 4]) img_pad, img_pad_indices = pre_fun.construct_sample(img, patch_size) # (1)select_sample:用img_gt的标签信息划分样本 # (2)得到的data_sample = {'train_indices': train_indices, 'train_num': train_num, # 'test_indices': test_indices, 'test_num': test_num, # 'no_gt_indices': no_gt_indices, 'no_gt_num': no_gt_num.unsqueeze(0) # } data_sample = pre_fun.select_sample(img_gt, train_set_num) # data_sample再添加几项数据 data_sample['pad_img'] = img_pad data_sample['pad_img_indices'] = img_pad_indices data_sample['img_gt'] = img_gt # 转化后的特征标签图的数据 data_sample['ori_gt'] = gt # 原始特征标签图的数据 # print('data_sample.keys()',data_sample.keys()) # dict_keys(['train_indices', 'train_num', 'test_indices', 'test_num', # 'no_gt_indices', 'no_gt_num', 'pad_img', 'pad_img_indices', 'img_gt', 'ori_gt']) if cfg['pca'] > 0: img_pca = pre_fun.extract_pc(img, cfg['pca']) img_pca = pre_fun.one_zero_norm(img_pca) img_pca = pre_fun.std_norm(img_pca) img_pca_pad, _ = pre_fun.construct_sample(img_pca, patch_size) data_sample['img_pca_pad'] = img_pca_pad return data_sample主要功能:
在这个函数中主要调用2.1中构建的子函数,来对图像数据进行处理,储存相应的处理完的图像数据
输出参数:
‘train_indices’, ‘train_num’, 训练集的坐标,训练集的数目
‘test_indices’, ‘test_num’, 测试集的坐标,测试集的数目
‘no_gt_indices’, ‘no_gt_num’, 背景图的坐标和数目
‘pad_img’, ‘pad_img_indices’, patch后的图像数据和坐标
‘img_gt’, ‘ori_gt’ 图像划分的原始数据
主要使用的是class HSI_data(data.Dataset),将get_train_test_set(cfg)返回的参数进行带入
(1)函数作用
def __getitem__(self, idx):来对具体的数值进行提取,根据之前训练集,测试集划分的不同,会返回相应的不同的长度,在编写训练函数的时候,借由
batch_data = DataLoader(train_data, batch_size, shuffle=True, \ num_workers=num_workers, collate_fn=collate_fn, pin_memory=True)这种形式将相应的数据通过Dataloader来进行加载读入,从而在设定好的epoch里面实现训练
(2)返回的参数
index = self.data_indices[idx]img_index = self.img_indices[index[0]] # img_index 坐标# 从pad_img中根据坐标截取样本img = self.img[:, img_index[0]:img_index[1], img_index[2]:img_index[3]]label = self.gt[index[1], index[2]]以idx来随机定位相应的索引的数据,返回图像数据为(可以根据自己的需求来进行返回):
在深度学习的过程中,主要使用了高光谱图像作为数据集来进行训练
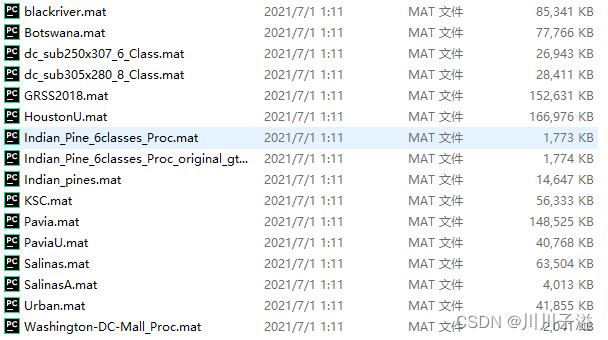
数据集的格式为mat文件
matdata = scio.loadmat(data_root)print(matdata.keys()) # 查看mat数据集的keydict_keys(['__header__', '__version__', '__globals__', 'fea', 'gnd', 'paviaU', 'paviaU_gt'])读取存放文件的地址位,来调用loadmat读取相应的数据,返回字典中的keys,来查看数据集中存在哪几类数据来进行调用
在读取数据集时,不仅要注意图像的【C,H,W】,还需要注意其中的,keys的选择
例如:
data_root = '/home/students/master/2022/wangzy/PyCharm-Remote/datasets/PaviaU.mat'image_name = 'paviaU'gt_name = 'paviaU_gt'# paviaU的特征分为了9类# torch([32, 103, 610, 340])data_root = '/home/students/master/2022/wangzy/PyCharm-Remote/datasets/Indian_pines.mat'image_name = 'indian_pines_corrected'gt_name = 'R'# indian_pines的特征分为了16类# torch([32, 220, 145, 145])paviaU的特征分类为9,在最后模型的全连接过程分类应该为9,在使用不同的数据集时需要注意特征数的不同,indian_pines的特征分为了16类。
数据集在训练的时候一般会分为空间信息和光谱信息,空间信息一般是pca处理后进行,通道数自己定义,光谱信息一般是对单像素的进行处理,在调用的时候,patch处理后的img图像正中间就是对应的图像原始像素点的数据。
在整个编写的过程中主要就是模型的编写,其他的部分基本是理解完成后进行细微的调整,这里用最基本的CNN2D来举例
class CNN2D(nn.Module): def __init__(self, in_fea_num, out_fea_num): super(CNN2D, self).__init__() self.conv1 = nn.Conv2d(in_fea_num, 32, kernel_size=4, stride=1) self.conv2 = nn.Conv2d(32, 64, kernel_size=5, stride=1) self.fc = nn.Linear(64, out_fea_num) def forward(self, origin_data, pca_data): output = self.conv1(pca_data) output = F.relu(output) output = F.max_pool2d(output, 2) output = self.conv2(output) output = F.relu(output) output = torch.flatten(output, 1) output = self.fc(output) return outputdef main(): net = CNN2D(1, 9) tmp = torch.randn(32, 1, 27, 27) out = net(tmp) print(out.shape)这是一个最基本的2D卷积神经网络,2个卷积层,中间插入relu和max_pool来实现卷积,最后进行相应的全连接
输入的是img_pca,这里是对HSI的空间信息进行处理,一般的空间卷积都是使用pca降维后的来进行使用,因为最后的paviaU的特征分为了9类,所以在后面的全连接层最后输出的为9,代表对9类特征值的判断概率
训练和测试模型基本上的代码框架差不多,在后面主要就是介绍训练模型使用的代码框架的理解,主体上包含了以下部分:
导入之前设定的参数值
加载模型和设定是否采用上次编写的来进行训练
在设定的epoch中进行数据的遍历
训练模型和存储
打印数据
(1)导入之前设定的参数值
num_workers = cfg['workers_num'] # 导入同时工作的线程数gpu_num = cfg['gpu_num'] # 几个GPU工作save_folder = cfg['save_folder'] #'./weights/'save_name = cfg['save_name'] #'model_CNN1D'lr_init = cfg['lr']lr_gamma = cfg['lr_gamma']lr_step = cfg['lr_step'] # 步进为60lr_adjust = cfg['lr_adjust'] # 设置为Tureepoch_size = cfg['epoch']batch_size = cfg['batch_size']主要是导入在初始文件configs中的设定值,在后面的修改中也基本是在configs里进行相应的修改
(2)加载模型和设定是否采用上次编写的来进行训练
if gpu_num > 1 and cfg['gpu_train']: # 采用多卡GPU服务器 model = torch.nn.DataParallel(model).to(device) # 使用样例 # model = model.cuda() # device_ids = [0, 1] # id为0和1的两块显卡 # model = torch.nn.DataParallel(model, device_ids=device_ids)else: model = model.to(device)model.train()if cfg['reuse_model']: print('loading model') checkpoint = torch.load(cfg['reuse_file'], map_location=device) # 用来加载torch.save() 保存的模型文件 start_epoch = checkpoint['epoch'] model_dict = model.state_dict() # state_dict其实就是一个字典,该自点中包含了模型各层和其参数tensor的对应关系。 pretrained_dict = {k: v for k, v in checkpoint['model'].item() if k in model_dict} # 再用预训练模型参数更新model_dict model_dict.update(pretrained_dict) model.load_state_dict(model_dict) # 装载已经训练好的模型else: start_epoch = 0可以通过选择是否采用上一次的模型或者,重新开始训练新的模型
(3)在设定的epoch中进行数据的遍历
for epoch in range(start_epoch + 1, epoch_size + 1): epoch_time0 = time.time() batch_data = DataLoader(train_data, batch_size, shuffle=True, \num_workers=num_workers, collate_fn=collate_fn, pin_memory=True) if lr_adjust: lr = adjust_lr(lr_init, lr_gamma, optimizer, epoch, lr_step) else: lr = lr_init epoch_loss = 0 predict_correct = 0 label_num = 0 for batch_idx, batch_sample in enumerate(batch_data): # 遍历加载的数据集 iteration = (epoch - 1) * batch_num + batch_idx + 1 batch_time0 = time.time() # (1)导入图片和标签 if len(batch_sample) > 3: img, target, indices, img_pca = batch_sample img_pca = img_pca.to(device) else: img, target, indices = batch_sample img = img.to(device) target = target.to(device)在这里主要是在一个中epoch,对图像数据进行导入和遍历,在DataLoader的作用下,batch_size=32决定了一次提取的图片数目,在HSI_Data的索引下,对划分好的训练集进行相应的随机提取,主要是用的是img和img_pca
(4)训练模型
# 前向传播prediction = model(img, img_pca) # 在CNN2D中只用了img_pca# 计算损失loss = loss_fun(prediction, target.long()) # 这里target应该是标签值# 优化器,反向传播optimizer.zero_grad() # 将梯度归零loss.backward() # 反向传播计算得到每个参数的梯度值optimizer.step() # 通过梯度下降执行一步参数更新这几步基本上是固定的,先进行前向传播,后面再进行反向传播更新梯度权重
if not os.path.exists(save_folder): os.makedirs(save_folder) # 递归创建目录 # 存储最终的模型save_model = dict( model=model.state_dict(), epoch=epoch_size)将训练完成的模型进行存储,用于下次的测试
(5)打印数据
# 将相应的数据进行打印print('Epoch: {}/{} || lr: {} || loss: {} || Train acc: {:.2f}% || ' 'Epoch time: {:.4f}s || Epoch ETA: {}' .format(epoch, epoch_size, lr, epoch_loss/batch_num, 100*predict_correct/label_num, epoch_time, str(datetime.timedelta(seconds=epoch_eta)) ) )将相应的参数打印,再训练的过程中可以进行观察
Epoch: 6/100 || lr: 0.01 || loss: 0.3411703225639131 || Train acc: 90.74% || Epoch time: 0.7305s || Epoch ETA: 0:01:08Epoch: 7/100 || lr: 0.01 || loss: 0.2682735058996413 || Train acc: 90.74% || Epoch time: 0.6298s || Epoch ETA: 0:00:58Epoch: 8/100 || lr: 0.01 || loss: 0.20451137092378405 || Train acc: 93.33% || Epoch time: 0.5340s || Epoch ETA: 0:00:49Epoch: 9/100 || lr: 0.01 || loss: 0.2426785926024119 || Train acc: 90.74% || Epoch time: 0.6558s || Epoch ETA: 0:00:59在main函数文件中,主要是调用前面的包装好的子函数进行调用,很简单和容易理解
主体上分为:
(1)基本参数配置
# 基本参数配置cfg_data = cfg.datacfg_model = cfg.modelcfg_train = cfg.train['train_model']cfg_optim = cfg.train['optimizer'] # 导入优化模型的相应参数cfg_test = cfg.test# 数据导入和数据集的划分data_sets = fun_get_set(cfg_data)train_data = fun_data(data_sets, cfg_data['train_data'])test_data = fun_data(data_sets, cfg_data['test_data'])no_gt_data = fun_data(data_sets, cfg_data['no_gt_data'])(2)加载模型和优化
device = torch.device("cuda:5")# 加载模型model = fun_model(cfg_model['in_fea_num'], cfg_model['out_fea_num']).to(device)# 损失函数loss_fun = nn.CrossEntropyLoss()# 优化器optimizer = optim.SGD(model.parameters(), lr=cfg_optim['lr'], momentum=cfg_optim['momentum'], weight_decay=cfg_optim['weight_decay'])(3)训练测试
# 训练fun_train(train_data, model, loss_fun, optimizer, device, cfg_train)# 测试pred_train_label = fun_test(train_data, data_sets['ori_gt'], model, device, cfg_test)pred_test_label = fun_test(test_data, data_sets['ori_gt'], model, device, cfg_test)pred_no_gt_label = fun_test(no_gt_data, data_sets['ori_gt'], model, device, cfg_test)predict_label = torch.cat([pred_train_label, pred_test_label, pred_no_gt_label], dim=0)(4)显示图像
直接显示相应的图像HSI = show.Predict_Label2Img(pred_no_gt_label)plt.imshow(HSI)plt.show()main函数也代表了整个HSI深度学习的代码框架,以这个框架在相应的文件子函数中进行编写和修改,但进行不同模型的训练最主要的还是修改不同的模型和训练集,对模型准确度的判定都差不多
--结束END--
本文标题: 【HSI】高光谱的数据集分类深度学习实战及代码理解
本文链接: https://www.lsjlt.com/news/422273.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0