Python 官方文档:入门教程 => 点击学习
在网络时代,数据是最宝贵的资源之一。而爬虫技术就是一种获取数据的重要手段。python 作为一门高效、易学、易用的编程语言,自然成为了爬虫技术的首选语言之一。而 BeautifulSoup 则是 Py
在网络时代,数据是最宝贵的资源之一。而爬虫技术就是一种获取数据的重要手段。python 作为一门高效、易学、易用的编程语言,自然成为了爬虫技术的首选语言之一。而 BeautifulSoup 则是 Python 中最常用的爬虫库之一,它能够帮助我们快速、简单地解析 html 和 XML 文档,从而提取出我们需要的数据。
本文将介绍如何使用 BeautifulSoup 爬取网页数据,并提供详细的代码和注释,帮助读者快速上手。
在开始之前,我们需要先安装 BeautifulSoup。可以使用 pip 命令进行安装:
pip install beautifulsoup4在本文中,我们将以爬取豆瓣电影 Top250 为例,介绍如何使用 BeautifulSoup 爬取网页数据。
首先,我们需要导入必要的库:
import requestsfrom bs4 import BeautifulSoup然后,我们需要获取网页的 HTML 代码。可以使用 requests 库中的 get() 方法来获取网页:
url = 'https://movie.douban.com/top250'response = requests.get(url)html = response.text接下来,我们需要使用 BeautifulSoup 解析 HTML 代码。可以使用 BeautifulSoup 的构造方法来创建一个 BeautifulSoup 对象:
soup = BeautifulSoup(html, 'html.parser')这里我们使用了 ‘html.parser’ 作为解析器,也可以使用其他解析器,如 lxml、HTML5lib 等。
现在,我们已经成功地将网页的 HTML 代码解析成了一个 BeautifulSoup 对象。接下来,我们可以使用 BeautifulSoup 对象中的方法来提取我们需要的数据。
在豆瓣电影 Top250 页面中,每个电影都包含了电影名称、导演、演员、评分等信息。我们可以使用 BeautifulSoup 提供的 find()、find_all() 等方法来提取这些信息。
首先,我们需要找到包含电影信息的 HTML 元素。可以使用浏览器的开发者工具来查看网页的 HTML 代码,找到对应的元素。在豆瓣电影 Top250 页面中,每个电影都包含在一个 class 为 ‘item’ 的 div 元素中:
1 
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
1057904人评价 希望让人自由。
我们可以使用 find_all() 方法来找到所有 class 为 ‘item’ 的 div 元素:
items = soup.find_all('div', class_='item')这里我们使用了 class_ 参数来指定 class 属性,因为 class 是 Python 中的关键字。
现在,我们已经成功地找到了所有电影的 HTML 元素。接下来,我们可以使用 BeautifulSoup 对象中的方法来提取电影信息。
例如,我们可以使用 find() 方法来找到电影名称所在的 HTML 元素:
title = item.find('span', class_='title').text这里我们使用了 text 属性来获取 HTML 元素的文本内容。
类似地,我们可以使用其他方法来提取导演、演员、评分等信息。完整的代码如下:
import requestsfrom bs4 import BeautifulSoupurl = 'Https://movie.douban.com/top250'response = requests.get(url)html = response.textsoup = BeautifulSoup(html, 'html.parser')items = soup.find_all('div', class_='item')for item in items: title = item.find('span', class_='title').text director = item.find('div', class_='bd').p.text.split()[1] actors = item.find('div', class_='bd').p.text.split()[2:] rating = item.find('span', class_='rating_num').text print('电影名称:', title) print('导演:', director) print('演员:', ' '.join(actors)) print('评分:', rating) print('------------------------')本文介绍了如何使用 BeautifulSoup 爬取网页数据,并提供了详细的代码和注释。通过本文的学习,读者可以掌握如何使用 BeautifulSoup 解析 HTML 和 XML 文档,从而提取出需要的数据。同时,读者也可以将本文中的代码应用到其他网页数据的爬取中。
当下这个大数据时代不掌握一门编程语言怎么跟的上脚本呢?当下最火的编程语言Python前景一片光明!如果你也想跟上时代提升自己那么请看一下.

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
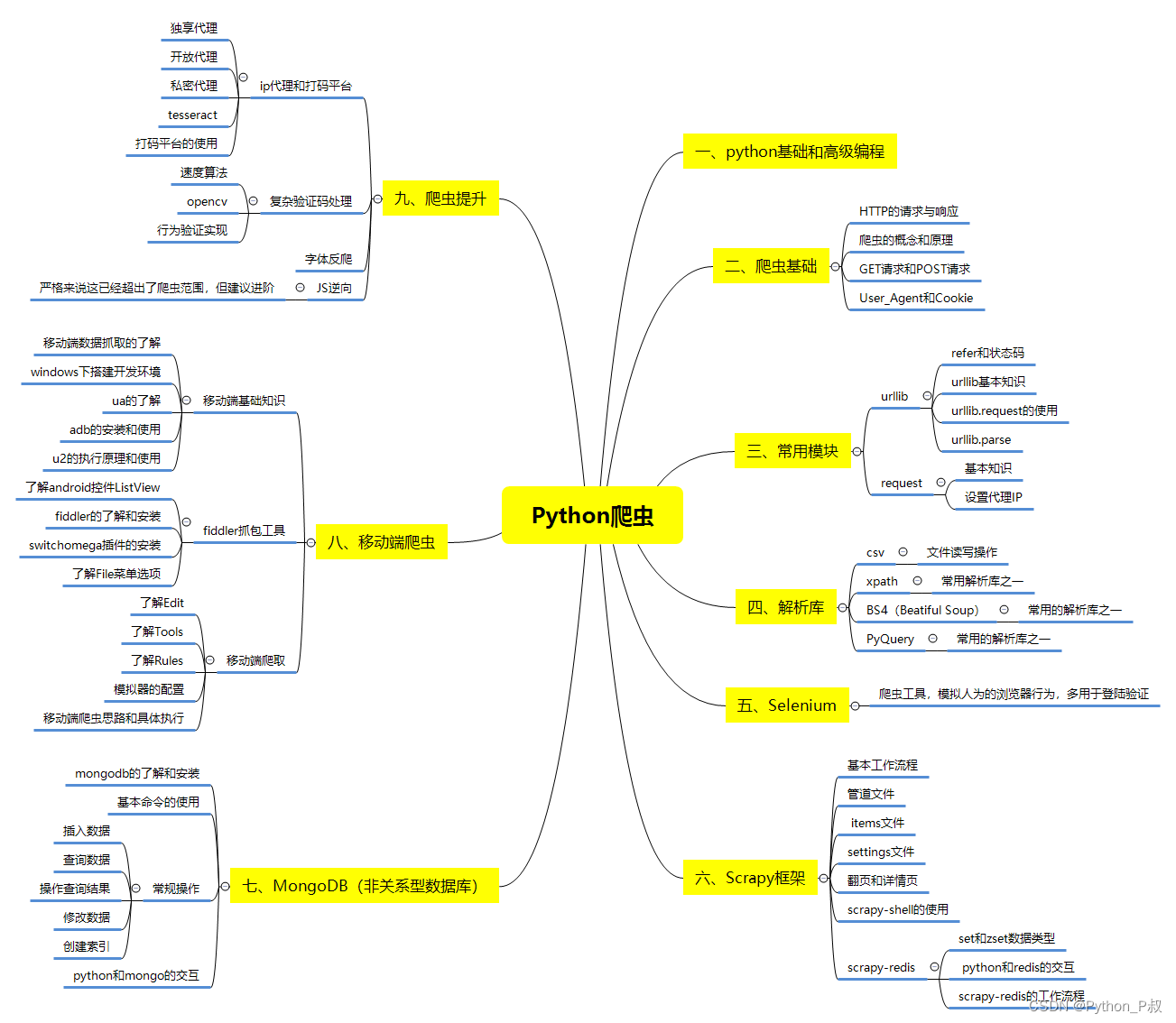
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典

 👉 CSDN大礼包:gift::[全网最全《Python学习资料》免费赠送:free:!](https://blog.csdn.net/weixin_68789096/article/details/132275547?spm=1001.2014.3001.5502) (安全链接,放心点击)
👉 CSDN大礼包:gift::[全网最全《Python学习资料》免费赠送:free:!](https://blog.csdn.net/weixin_68789096/article/details/132275547?spm=1001.2014.3001.5502) (安全链接,放心点击) 若有侵权,请联系删除
来源地址:https://blog.csdn.net/cxyxx12/article/details/133125488
--结束END--
本文标题: Python 爬虫:如何用 BeautifulSoup 爬取网页数据
本文链接: https://www.lsjlt.com/news/440213.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0