1、故障现象 某客户反馈,在利用binlog日志的解析内容做基于时间点的恢复时,出现hang死(超过12小时那种),恢复过程无法继续,而且100%重现 基于时间点恢复的实现方式为:使用Mysqlb
[root@localhost ~]# ps aux |grep mysqlbinlog
root 27822 1.3 0.0 24568 3204 pts/2 R+ 15:11 0:04 mysqlbinlog --stop-datetime='2019-07-14 16:30:00' mysql-bin.000014 mysql-bin.000015 mysql-bin.000016 mysql-bin.000017 mysql-bin.000018 mysql-bin.000019
......然后,查看了当前正在运行的线程状态信息,发现一个sleep长达157269S的线程,这是什么鬼。。大事务未提交吗?窃喜!
admin@localhost : test 02:18:27> show processlist;
+----+-------+-----------+------+---------+--------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------+-----------+------+---------+--------+----------+------------------+
| 14 | admin | localhost | test | Query | 0 | starting | show processlist |
| 15 | admin | localhost | test | Sleep | 157269 | | NULL |
+----+-------+-----------+------+---------+--------+----------+------------------+
2 rows in set (0.00 sec)接着,我们查看了事务和锁信息
# 先查看事务信息
admin@localhost : test 03:02:36> select * from infORMation_schema.innodb_trx\G
Empty set (0.00 sec) # 纳尼!!,居然不存在事务正在运行
# 然后查看锁信息
admin@localhost : test 03:30:25> select * from information_schema.innodb_locks;
Empty set, 1 warning (0.00 sec) # WTF!!居然也没有锁信息再接着,我们查看了一下系统负载,内存、网络、磁盘都几乎无负载,CPU也没啥负载,但却有一个奇怪的现象,有一个CPU核心的利用率为100%,如下
top - 15:40:50 up 117 days, 8:09, 5 users, load average: 1.97, 1.36, 1.15
Tasks: 496 total, 2 running, 494 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
# 利用率为100%的CPU核心在这里
%Cpu2 : 34.4 us, 65.6 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu7 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
......最后,在恢复库中,我们查看了一下GTID信息,发现GTID号不连续,少了一个事务的GTID(3759)
admin@localhost : (none) 03:52:08> show master status;
+------------------+----------+--------------+------------------+---------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+---------------------------------------------+
| mysql-bin.000013 | 500 | | | 5de97c46-a496-11e9-824b-0025905b06da:1-3758,3760-3767 |
+------------------+----------+--------------+------------------+---------------------------------------------+
1 row in set (0.00 sec)通过查看从库中的GTID(也就是恢复库的数据源对应的库),并没有少GTID号为3759的事务,为什么莫名在恢复库中会少,而不是连续的?带着好奇,我们使用该GTID号解析了从库中的所有被指定用于恢复的binlog file列表(这里指的就是mysql-bin.000014 mysql-bin.000015 mysql-bin.000016 mysql-bin.000017 mysql-bin.000018 mysql-bin.000019),从这些binlog中提取了GTID号为3759的事务的binlog日志内容
[root@localhost binlog]# mysqlbinlog mysql-bin.000014 mysql-bin.000015 mysql-bin.000016 mysql-bin.000017 mysql-bin.000018 mysql-bin.000019 --include-gtids='5de97c46-a496-11e9-824b-0025905b06da:3759' > b.sql
[root@localhost binlog]# ls -lh b.sql
-rw-r--r-- 1 root root 996M Jul 14 15:59 b.sql # My God,GTID号为3759的一个事务binlog日志量快接近一个G了
# 使用mysqlbinlog命令加-vv选项重新解析(使用-vv选项解析,会导致解析结果的大小翻3倍左右),查看事务的原始语句是怎样的(binlog_rows_query_log_events=ON才会记录事务的原始语句文本)
[root@localhost binlog]# mysqlbinlog -vv mysql-bin.000014 mysql-bin.000015 mysql-bin.000016 mysql-bin.000017 mysql-bin.000018 mysql-bin.000019 --include-gtids='5de97c46-a496-11e9-824b-0025905b06da:3759' > c.sql
# vim打开c.sql文件查看
[root@localhost binlog]# ls -lh
total 12G
-rw-r--r-- 1 root root 994M Jul 14 16:38 b.sql
-rw-r--r-- 1 root root 2.7G Jul 14 16:40 c.sql
......
[root@localhost binlog]# vim c.sql
......
# at 336
#190714 16:29:10 server id 3306102 end_log_pos 422 CRC32 0x3b2c9b07 Rows_query
# 发现一个400W行的大事务(经查看sbtest.sbtest1表中的数据量,确认该语句会往test.sbtest1表中插入400W行)
# insert into sbtest1 select * from sbtest.sbtest1 limit 4000000
......
BINLOG '
1ucqXRN2cjIAOQAAAN8BAAAAAHUAAAAAAAEABHRlc3QAB3NidGVzdDEABAMD/v4E7mj+tABkzbY1
1ucqXR52cjIADSAAAOwhAAAAAHUAAAAAAAAAAgAE//ABAAAAlyomAHcAMzMzNjgzMDQzMTQtMjYx
MDIwNDA4ODktMTU4NzIxODA4NzYtMTU0NDIxOTgxNjQtNDYzOTM1NDIxMzEtMTQwODg3NzUzNTQt
NzY4MDU0ODgyMTEtNzg0ODM1NTU5NjEtNjMyMDM5NjA0ODEtNDcxNjQ5MDg4MjY7NTA3NzUyOTM0
MzctMjE4MzMzNTAzNzYtODc2MTE2NjU0NTYtNjI4NTU3NjAyOTItNDQ3Mjc0MzA4MTjwAwAAAA0z
HQB3ADM4NjUyNzU5NDQwLTg4NjY4MjU5MDE3LTk0MDk4ODI4Nzc1LTYxMzMzNjEwMjg0LTYyODc3
NDgxMTY3LTY1NzM3Mjg3NTExLTA4MDYwNzA5NTU1LTIzMTUyNjI5NTcxLTE2MDMzMDM2NDE5LTYy
MjA0MDgxMzc0OzczOTE3OTQ0NjMzLTc0ODMwMjgwMjE3LTAxMTYzODkwMzkzLTU3NTEzNDA4MDY1
LTMwNjgzOTA1MTQ08AUAAAAlNCYAdwAwMjU2MTIyODQ3MC05OTAwMzk1ODMyOC0zMDQ1OTgyMzQw
NC0zMTY1MTgyNzE4OC02MDMxODU1MDA5OS03Njk5Njk5MTY3Mi02MTI1Nzg5NTU5MC03NDA3OTQz
MDg4MC01NzMyMDA4MzY4NC0zNjAzMDY2NDE4NjszOTA4Nzk4NjM5NC02MjA0NjQ4MDk0Ny01NjQ0
NTE4NzA3My0yODQxNDg5MzQyNC03OTYxOTMzMTg1N/AHAAAAn1MmAHcAODgxMzg4MjkxMjEtMDkx
NTk1NDI1OTctNzc4ODUwODczMzMtMjA1MzE3NDM2MjktODE3NTQ0NDc2MjgtMjczNDMyMzQ2ODEt
...... # 这就是这个大事务对应的BINLOG编码,整个b.sql文件的994MB的内容主要就是这些BINLOG编码使用strace工具查看登录MySQL并加载binlog解析文本过程中的一些输出信息(这里直接使用上文中提到的b.sql)
[root@localhost ~]# strace mysql 2> strace.txt
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 22
Server version: 5.7.26-log MySQL CommUnity Server (GPL)
Copyright (c) 2000, 2019, oracle and/or its affiliates. All rights reserved.
Oracle is a reGIStered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
admin@localhost : (none) 10:49:36> use test
Database changed
admin@localhost : test 10:49:38> source /data/mysqldata1/binlog/b.sql;
......
Charset changed
......
Warning (Code 1681): Updating 'collation_database' is deprecated. It will be made read-only in a future release.
Query OK, 0 rows affected (0.00 sec)
# 卡在这里了,此时你可以先去干点别的,20分钟之后再回来看看导入成功了没有,不过,不管你等不等,这个客户端要留着后续排查用,不能断开了现在,另起一个终端会话,查看strace.txt文件中的内容
[root@localhost ~]# tailf strace.txt
......
munmap(0x7f8d6607d000, 58281984) = 0
read(4, "wMjE4ODQzLTE5MTYzMTE4NDk4LTQwNTA"..., 4096) = 4096
mmap(NULL, 58290176, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f8d5f150000
...... # 发现不断地打印类似下面这一段信息,貌似卡在内存分配这里了
munmap(0x7f8d628e1000, 58298368) = 0
read(4, "UxNzUtODUyMjQ1MTkxMDEtMTM4MTk3OD"..., 4096) = 4096
mmap(NULL, 58306560, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f8d66077000
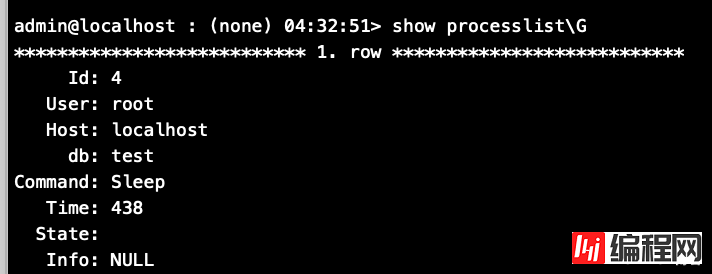
......注意:如果你在跟随我们的复现过程玩耍,建议你查看一下show processlist的信息,你可能会发现之前导入b.sql文件的客户端连接在数据库中并没有被断开,如果发现此情况,则需要在数据库中手工执行kill操作
admin@localhost : (none) 11:14:54> show processlist;
+----+-------+-----------+------+---------+-------+----------------------------------+----------------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------+-----------+------+---------+-------+----------------------------------+----------------------------------------------------------------------+
| 22 | admin | localhost | test | Sleep | 67545 | | NULL |
......
| 32 | admin | localhost | NULL | Query | 0 | starting | show processlist |
+----+-------+-----------+------+---------+-------+----------------------------------+----------------------------------------------------------------------+
admin@localhost : (none) 11:14:55> kill 22;
Query OK, 0 rows affected (0.00 sec)登录到MySQL并执行导入b.sql文件操作(不要用strace)
[root@localhost ~]# mysql -uadmin -ppassWord
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 31
Server version: 5.7.26-log MySQL Community Server (GPL)
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
admin@localhost : (none) 11:08:58> use test
Database changed
admin@localhost : test 11:09:00> source /data/mysqldata1/binlog/b.sql;
......使用pstack工具查看MySQL客户端连接的进程堆栈信息
# 查看MySQL客户端连接进程号
[root@localhost ~]# ps aux |grep 'mysql -uadmin' |grep -v grep
root 4614 81.2 0.0 175080 41284 pts/21 R+ 11:18 0:20 mysql -uadmin -px xxxx
# 使用pstack工具查看
[root@localhost ~]# pstack 4614 |tee -a pstack.txt
# 发现它卡在__memmove_ssse3_back ()内存拷贝的阶段了。此时你可以看到系统的某一个CPU的idle是0%(与上文中发现的CPU负载诡异现象吻合),这个CPU被耗尽的CPU做的事情就是,持续申请内存、拷贝数据、释放内存,自然把一个CPU给用完了
#0 0x00007f1009f5c315 in __memmove_ssse3_back () from /lib64/libc.so.6
#1 0x0000000000422adf in my_realloc (key=<optimized out>, ptr=0x7f0ffde45030, size=30197464, flags=<optimized out>) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/mysys/my_malloc.c:100
#2 0x000000000041a2ba in String::mem_realloc (this=0xa45460 <glob_buffer>, alloc_length=30197460, force_on_heap=<optimized out>) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/sql-common/sql_string.cc:121
#3 0x0000000000417922 in add_line (truncated=false, ml_comment=<optimized out>, in_string=<optimized out>, line_length=76, line=0x16b4309 "NDQ4NDA0LTE5MjQ2NjgzMDgxLTY2MTA0Mjk0ODQ2LTYzNzk3MjcwMjU0LTQ3NjA2Nzk0MTY0LTEx\nODQwNjExOTY5OzY5NTQ1Mjc5MDA2LTM5NTgwMjUzMDEzLTgzMjQxNjU0MzQ1LTA4MDkxMDEzODk1\nLTk5NzMxMDYyMzU58B2TAwABKiYAdwAwNTEzMjEzNDUzNC"..., buffer=...) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/client/mysql.cc:2795
#4 read_and_execute (interactive=false) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/client/mysql.cc:2364
#5 0x00000000004181ef in com_source (buffer=<optimized out>, line=<optimized out>) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/client/mysql.cc:4709
#6 0x0000000000417099 in add_line (truncated=false, ml_comment=<optimized out>, in_string=<optimized out>, line_length=37, line=0x16b2a10 "source /data/mysqldata1/binlog/b.sql;", buffer=...) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/client/mysql.cc:2664
#7 read_and_execute (interactive=true) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/client/mysql.cc:2364
#8 0x0000000000418c98 in main (arGC=15, argv=0x160c348) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/client/mysql.cc:1447由于是在MySQL 5.7.26版本中发生的故障,所以我们首先查看了MySQL 5.7.26版本的客户端源码,MySQL客户端在读取一个文件时(或者说判断什么时候可以将一个操作发送给服务端时),碰到';'分号会直接将前面读取到的内容作为一整个数据包丢给服务端,对上文中提到的b.sql文件中的BINLOG编码,整个BINLOG编码只有一个分号,所以会等到整个BINLOG编码读取完成之后才会发送给服务端,在读取这个超大BINLOG编码的过程中,MySQL客户端会一行一行的读,并记录到global_buffer中。当global_buffer申请的空间不足时,就需要扩展内存空间,,扩展内存空间的代码如下:
// client/mysql.cc 文件
if (buffer.length() + length >= buffer.alloced_length())
buffer.mem_realloc(buffer.length()+length+IO_SIZE); # 每次除了扩展不够的内存以外(原有的内存长度+新读取的内容长度),额外只多扩展了4k的空间(也就是IO_SIZE,IO_SIZE变量的定义大小详见代码段后续的"include/my_global.h 文件")
// mysys/my_malloc.c 文件
new_ptr= my_malloc(key, size, flags); # 扩展内存时先申请一段新的更大空间的内存(新申请的一段内存的大小为client/mysql.cc 文件中描述的扩展之后的内存大小)
if (likely(new_ptr != NULL))
{
#ifndef DBUG_OFF
my_memory_header *new_mh= USER_TO_HEADER(new_ptr);
#endif
DBUG_ASSERT((new_mh->m_key == key) || (new_mh->m_key == PSI_NOT_INSTRUMENTED));
DBUG_ASSERT(new_mh->m_magic == MAGIC);
DBUG_ASSERT(new_mh->m_size == size);
min_size= (old_size < size) ? old_size : size;
memcpy(new_ptr, ptr, min_size); # 然后把数据拷贝过去
my_free(ptr);
return new_ptr;
}
// include/my_global.h 文件
#define OS_FILE_LIMIT UINT_MAX
#define IO_SIZE 4096 # IO_SIZE 变量的大小定义为4K接下来,我们解决第二个问题,比对MySQL 5.7.26和MySQL 8.0.16版本中,关于客户端缓存读取文件数据这块的内存分配代码有什么不同?
# 以下只列出MySQL 8.0.16版本中的代码
// client/mysql.cc 文件
if (buffer.length() + length >= buffer.alloced_length())
buffer.mem_realloc(buffer.length() + length + batch_io_size); ## 8.0中每次扩内存时,额外分配的内存大小变更为了batch_io_size,在5.7中,batch_io_size位置是IO_SIZE
// client/my_readline.h 文件
static const unsigned long int batch_io_size = 16 * 1024 * 1024; ## 这里定义batch_io_size为16M,从4K变为16M,这就使得客户端在缓存读取的数据时,发现内存不够之后的内存分配效率提高几个数量级最后,多说一句,MariaDB虽然也同样解决了这个问题,但是解决方法完全不同(粗略看了一下代码,没细看),通过比对解析的BINLOG编码,发现MariaDB的BINLOG编码是存在一个个的空缺,所以猜测可能是采用了"mysqlbinlog的解析格式变更"配合"mysql客户端的解析逻辑变更"来解决该问题的(MariaDB在执行导入binlog解析内容时,show processlist查看线程状态也能发现导入数据的线程一直在干活,并不是一直处于Sleep状态),类似如下
MariaDB
* BINLOG编码格式
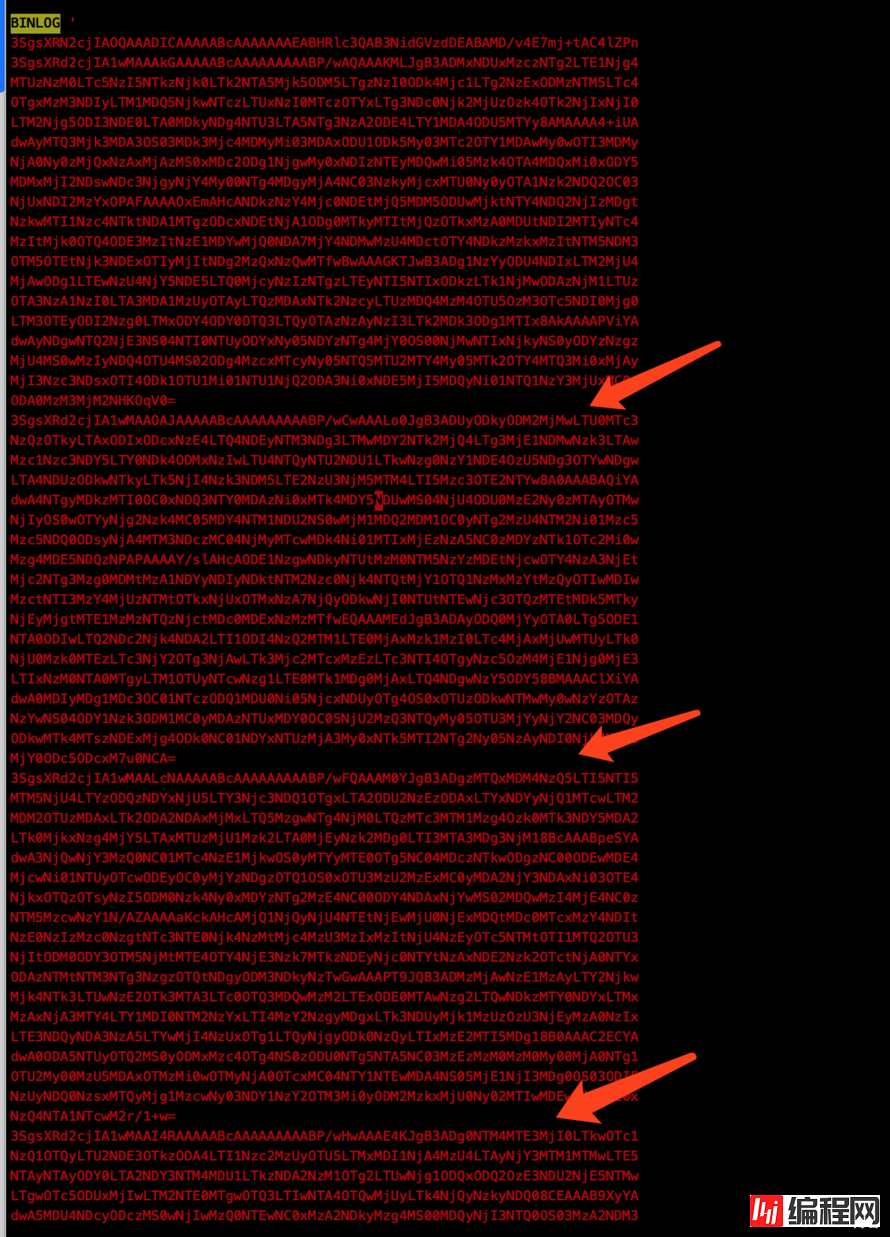
* show processlist状态

MySQL
* BINLOG编码格式

* show processlist状态
| 作者简介
罗小波·沃趣科技高级数据库技术专家
IT从业多年,主要负责MySQL 产品的数据库支撑与售后二线支撑。曾参与版本发布系统、轻量级监控系统、运维管理平台、数据库管理平台的设计与编写,熟悉MySQL体系结构,Innodb存储引擎,喜好专研开源技术,多次在公开场合做过线下线上数据库专题分享,发表过多篇数据库相关的研究文章。
--结束END--
本文标题: MySQL 一个让你怀疑人生的hang死现象
本文链接: https://www.lsjlt.com/news/48238.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0