客户端查询请求流程 先来看客户端运行一条查询 sql 会经过哪些流程: Mysql 基本组成结构 从上面的图中可以看出,mysql 大致由 server 层 和 存储引擎层组成。 为了管理方便,mysql 把连接管理、查询缓存、语法解析、

先来看客户端运行一条查询 sql 会经过哪些流程:
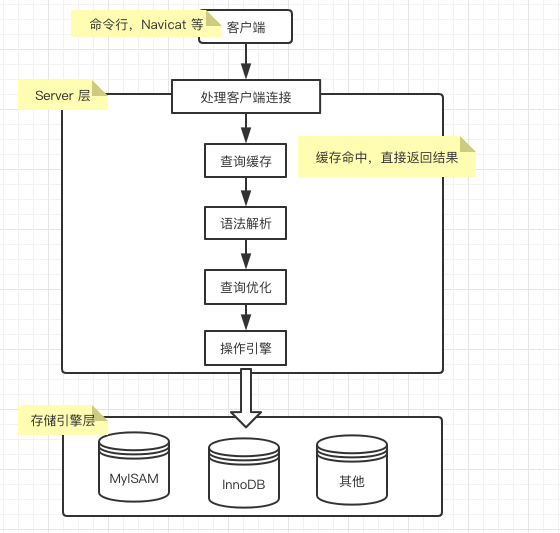
从上面的图中可以看出,mysql 大致由 server 层 和 存储引擎层组成。
为了管理方便,mysql 把连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存储的功能划分为 server 层的功能,把真实存取数据的功能划分为存储引擎的功能。
下面详细说明下各个模块的功能:
server 层又分别由 连接器、查询缓存、分析器、优化器、执行器组成。
mysql 是 C/S 架构,每当有一个客户端连接到服务器时,服务器都会创建一个线程来专门处理与这个客户端的交互。
客户端和服务端的连接方式总共有三种。
注意:
如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
也就是说即使管理员在此时修改了用户的数据库权限,只有用户重新建立连接才会生效。
当客户端与服务端建立连接后,客户端就会以文本消息的方式与服务端通信(CRUD)。服务端接收到消息后(比如一个查询请求),还要进行一系列处理,才能返回数据给客户端。
上一步连接建立完成后,就可以执行查询语句了。这时候执行流程就来到了第二步:查询缓存
mysql 拿到一个查询语句请求后,会先到查询缓存看看,之前是不是执行过这条查询语句。之前执行的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,mysql 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
但是大多数情况不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
当然,MySQL服务器并没有人聪明,如果两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。另外,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如mysql、infORMation_schema、 performance_schema 数据库中的表,那这个请求就不会被缓存。以某些系统函数举例,可能同样的函数的两次调用会产生不一样的结果,比如函数NOW,每次调用都会产生最新的当前时间,如果在一个查询请求中调用了这个函数,那即使查询请求的文本信息都一样,那不同时间的两次查询也应该得到不同的结果,如果在第一次查询时就缓存了,那第二次查询的时候直接使用第一次查询的结果就是错误的!
不过既然是缓存,那就有它缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了INSERT、 UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或 DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!
注意:
查询缓存会造成一些开销,比如每次都要去查询缓存中检索,查询请求处理完需要更新查询缓存,维护该查询缓存对应的内存区域。
从MySQL 5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除
如果没有命中查询缓存,就要开始真正执行语句了。
首先,mysql 需要知道你要做什么,因此需要对 SQL 语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么。
MySQL从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名T”,把字符串“ID”识别成“列ID”。
做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个SQL语句是否满足MySQL语法。
如果你的语句不对,就会收到 “You have an error in your SQL syntax”
语法解析之后,服务器程序获得到了需要的信息,比如要查询的列是哪些,表是哪个,搜索条件是什么等等。
但光有这些是不够的,因为我们写的 SQL 语句执行起来效率可能并不是很高,MySQL 的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等一系列 ‘骚操作’。
优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是啥样的。我们可以使用EXPLaiN语句来查看某个语句的执行计划。
MySQL通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句
开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示。
mysql> select * from table1 where ID=10;
ERROR 1142 (42000): SELECT command denied to user "b"@"localhost" for table "T"
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
比如我们这个例子中的表T中,ID字段没有索引,那么执行器的执行流程是这样的:
调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这行存在结果集中;
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。
对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。
你会在数据库的慢查询日志中看到一个rows_examined的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。
在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的。
截止到服务器程序完成了查询优化为止,还没有真正的去访问真实的数据表,mysql 服务端把数据的存储和提取操作都封装到了一个叫 存储引擎 的模块里。
我们知道表是由一行一行的记录组成的,但这只是一个逻辑上的概念,物理上如何表示记录,怎么从表中读取数据,怎么把数据写入具体的物理存储器上,这都是存储引擎负责的事情。
为了实现不同的功能,MySQL 提供了各式各样的存储引擎,常用的如 InnoDB,MyISAM。不同存储引擎管理的表具体的存储结构可能不同,采用的存取算法也可能不同。
各种不同的存储引擎向上边的 server 层提供统一的调用接口(也就是存储引擎api),包含了几十个底层函数,像"读取索引第一条内容"、"读取索引下一条内容"、"插入记录"等等。
所以在 server 层 完成了查询优化后,只需按照生成的执行计划调用底层存储引擎提供的 API,获取到数据后返回给客户端就好了。
--结束END--
本文标题: mysql 学习笔记 01 - mysql 的组成结构
本文链接: https://www.lsjlt.com/news/4908.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0