前些日子,监控显示线上偶尔发生请求两秒超时的情况。解决这个问题前前后后花了不少时间,也走了一些弯路。这里记录下来备忘。 前期分析 首先需要了解一下我们的服务: 我们的服务是一组无状态的前端服务器加上有状态的后端存储层。 这
前些日子,监控显示线上偶尔发生请求两秒超时的情况。解决这个问题前前后后花了不少时间,也走了一些弯路。这里记录下来备忘。
首先需要了解一下我们的服务:
第一件事是要定位问题出现在前端还是后端。通过日志,我们发现在出错时间段里,每个前端服务器都有报错,并且出错请求都是发往同一后端服务器的。由此可见,问题出现在后端服务上。
接下来,需要分析出错的特征。通过日志发现错误都是因为前端两秒超时导致,而后端在前端超时之后事实上是完成了请求。因为是存储服务,我们自然在第一时间就查看了磁盘的情况。果然,在出错时,磁盘的io.util非常高(sar -dp的输出,从第4列开始分别是tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util):
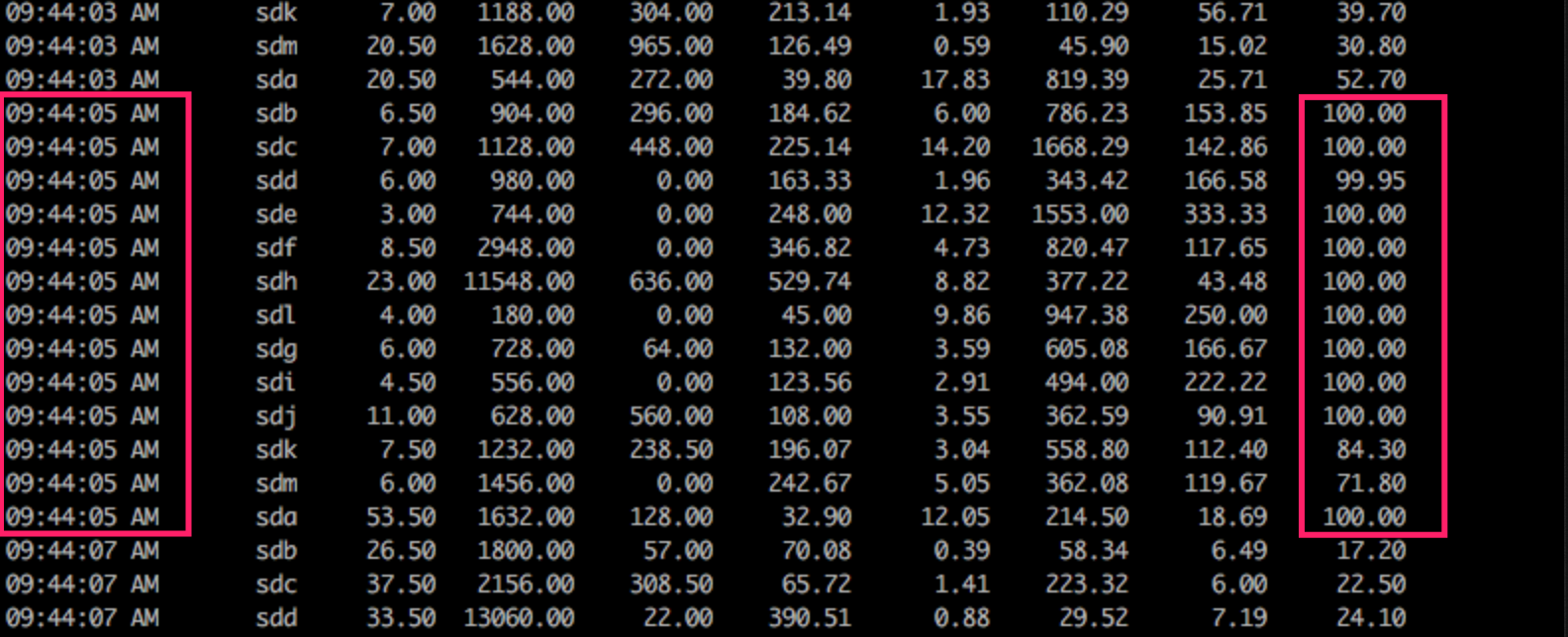
需要注意的是:
另外,还发现了另外一个规律:单台机器,大概每12小时左右会出现io.util高,并伴随着超时出错:
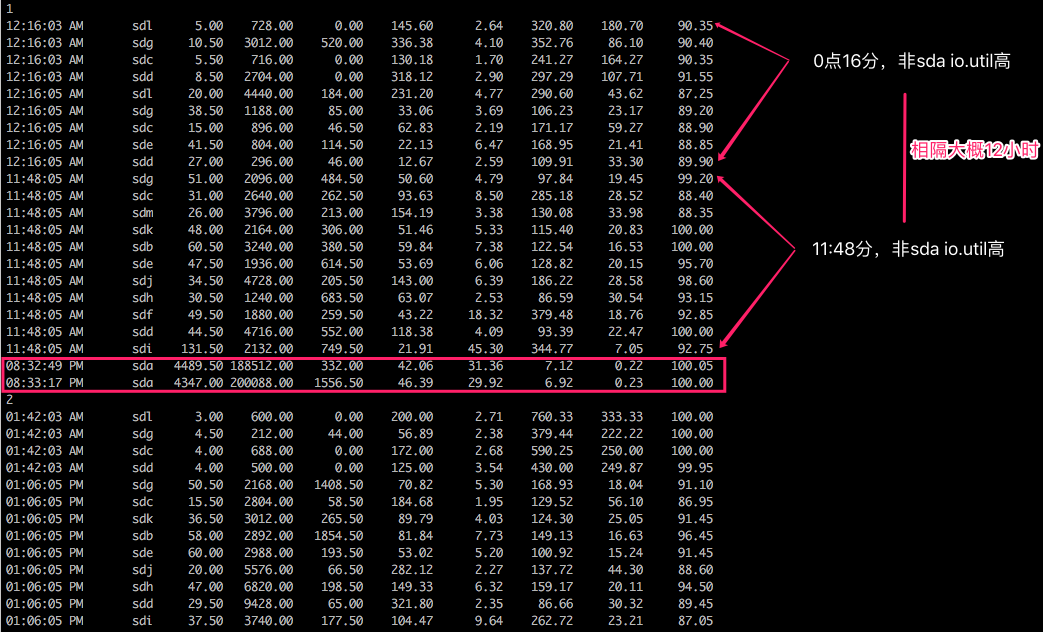
我们做了一些快速排查,试图以比较小的代价找到问题的根源:
可惜,都没有发现有价值的线索。于是推测,一定是有一个我们不知道的存在以12小时为周期在消耗IO。
先使用iotop来定位出错时刻是谁占用了大量IO:
python /sbin/iotop -bPto -n 86400 > iotop.log
上述命令以批处理的形式,每1秒一个输出,一共持续86400秒(24小时)。同样,并没有发现除了我们程序之外的可疑线程。
Iotop虽然是一个好工具,然而一个缺陷是并没有详细的文档说明它的工作原理。对于一个系统工具来说,原理性的文档还是很有必要的。在这种情况下,我们怀疑iotop并不能真实的反映进程的IO使用状况。为了再次确认,我们采用SystemTap来统计IO调用。下面是改良过的iotop.stp:
global count_stacks
global size_stacks
global max_seconds = 172800
global elapsed_seconds = 0
global interval = 2
probe ioblock.request {
if(devname == "sdd") {
count_stacks[pid(), execname(), bio_rw_str(rw), backtrace()]++
size_stacks[pid(), execname(), bio_rw_str(rw), backtrace()] += size
}
}
probe timer.s(1)
{
if (++elapsed_seconds % interval == 0) {
if (elapsed_seconds >= max_seconds) {
delete count_stacks
exit()
}
time_string = ctime(gettimeofday_s())
foreach ([process_id, process_name, read_write, stack] in count_stacks- limit 5) {
printf("==== %25s %6d %20s %s %d
", time_string, process_id, process_name, read_write, count_stacks[process_id, process_name, read_write, stack])
print_syms(stack)
}
foreach ([process_id, process_name, read_write, stack] in size_stacks- limit 5) {
printf("++++ %25s %6d %20s %s %d
", time_string, process_id, process_name, read_write, size_stacks[process_id, process_name, read_write, stack])
print_syms(stack)
}
delete count_stacks
delete size_stacks
}
}
这个脚本以2秒间隔,采样发生在/dev/sdd上的所有IO读写请求,并分别按照请求栈出现的次数以及IO总大小,打印前5名。执行脚本:
nohup stap --suppress-handler-errors -d xfs ./iotop.stp > stap.log &
一个典型的部分结果是:
==== Wed Oct 24 09:19:03 2018 1984 java W 20
0xffffffff812c7130 : generic_make_request+0x0/0x130 [kernel]
0xffffffff812cd89b : blkdev_issue_flush+0xab/0x110 [kernel]
0xffffffffa0681dc9 : xfs_blkdev_issue_flush+0x19/0x20 [xfs]
0xffffffffa066b506 : xfs_file_fsync+0x1e6/0x200 [xfs]
0xffffffff8120f975 : do_fsync+0x65/0xa0 [kernel]
0xffff882025940b80 : 0xffff882025940b80
0xffffffff8120fc40 : SyS_fsync+0x10/0x20 [kernel]
0xffffffff81645909 : system_call_fastpath+0x16/0x1b [kernel]
==== Wed Oct 24 09:19:03 2018 1984 java R 5
0xffffffff812c7130 : generic_make_request+0x0/0x130 [kernel]
0xffffffff8121f630 : do_mpage_readpage+0x2e0/0x6e0 [kernel]
0xffffffff8121fb1b : mpage_readpages+0xeb/0x160 [kernel]
0xffffffffa065fa5d : xfs_vm_readpages+0x1d/0x20 [xfs]
0xffffffff81175cdc : __do_page_cache_readahead+0x1cc/0x250 [kernel]
0xffff88201534cf00 : 0xffff88201534cf00
0xffffffff81175ee6 : ondemand_readahead+0x126/0x240 [kernel]
0xffffffff811762c1 : page_cache_sync_readahead+0x31/0x50 [kernel]
0xffffffff8120e0d6 : __generic_file_splice_read+0x556/0x5e0 [kernel]
0xffffffff8120c9b0 : spd_release_page+0x0/0x20 [kernel]
0xffffffff81513D48 : sk_reset_timer+0x18/0x30 [kernel]
0xffffffff81582ce5 : tcp_schedule_loss_probe+0x145/0x1e0 [kernel]
0xffffffff81583b40 : tcp_write_xmit+0x2b0/0xce0 [kernel]
0xffffffff8163cb5b : _raw_spin_unlock_bh+0x1b/0x40 [kernel]
0xffffffff815154a8 : release_sock+0x118/0x170 [kernel]
0xffffffff815769e6 : tcp_sendmsg+0xd6/0xc20 [kernel]
0xffffffff8120e19e : generic_file_splice_read+0x3e/0x80 [kernel]
0xffffffffa066bc5b : xfs_file_splice_read+0xab/0x140 [xfs]
0xffffffff8120d222 : do_splice_to+0x72/0x90 [kernel]
0xffffffff8120d2f7 : splice_direct_to_actor+0xb7/0x200 [kernel]
第一个栈是我们的程序在做fsync,第二个栈是程序在做read ahead。这两个我们都排除了:
blockdev也修改了,并没有效果至此,我们的调查陷入僵局:并没有谁在做IO,然而io.util就是高。
继续思考,我们推测:可能有某个操作并没有做大量的IO,但是可能会把盘给夯住。注意,这个推测和我们最初对IO的分析是一致的。
于是,我们想到用top来看看当时的进程状况(按道理这是第一个需要尝试的手段!):
nohup top -b -d 1 -n 86400 > top.log &
即,以批处理的方式,每1秒打印一次进程状况,一共持续24小时。然后,在发生问题的时刻,我们搜素所有处于D状态的(等IO)的进程。果然,发现一个可疑进程:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32289 root 20 0 2148 1528 212 D 0.0 0.0 0:00.00 sas3flash
sas3flash是个什么进程呢?先找到他的位置:
$ locate sas3flash
/usr/local/agenttools/agent/plugins/titan_tools/sas3flash
所在的目录貌似是属于一个agent的,嗯~相当可疑。看看他是被谁调用的:
/usr/local/agenttools/agent/plugins$ grep sas3flash * -r
Binary file titan_for_serverV1.0 matches
/usr/local/agenttools/agent/plugins$ strings titan_for_serverV1.0 | grep sas3flash
sas3flash
/usr/local/agenttools/agent/plugins/titan_tools/sas3flash -list
/usr/local/agenttools/agent/plugins/titan_tools/sas3flash
report_hba_by_sas3flash
report_hba_by_sas3flash
report_hba_by_sas3flash
再通过一通搜索,我们得知:
sas3flash --list看上去是一个查看命令,貌似人畜无害,但很可能是问题的元凶于是执行sas3flash --list,果然问题重现!用strace查看可知,该命令并没有发什么IO请求,而是做了一些ioctl的调用。实验证实这些查询调用会夯住IO。
在/usr/local/agenttools/agent/Agent_log.log日志文件中,我们能够找到这个命令执行的时间点和输出,考虑到执行-汇报时间差,可以发现该命令执行的时间点就是线上超时错误问题出现的时间点:
[2018-10-25 19:12:13] Send warning info, id:36149, value:[CollectID:
ServerSN:2102311YMD10J1000212
AvaGo Technologies SAS3 Flash Utility
Version 09.00.00.00 (2015.02.03)
Copyright 2008-2015 Avago Technologies. All rights reserved.
Adapter Selected is a Avago SAS: SAS3008(C0)
Controller Number : 0
Controller : SAS3008(C0)
PCI Address : 00:01:00:00
SAS Address : 5e86819-f-8f0a-f000
NVDATA Version (Default) : 0b.02.00.01
NVDATA Version (Persistent) : 0b.02.00.01
Firmware Product ID : 0x2721 (IR)
Firmware Version : 12.00.02.00
NVDATA Vendor : LSI
NVDATA Product ID : SAS3008
BiOS Version : 08.29.02.00
UEFI BSD Version : 17.00.04.00
FCODE Version : N/A
Board Name : SAS3008
Board Assembly : N/A
Board Tracer Number : 022CDECNHC010620
Finished Processing Commands Successfully.
Exiting SAS3Flash.
]
通过仔细查看这个目录下面的文件,就会发现,这个监控组件有着自己的一套定时任务逻辑以及日志输出。这就是为什么我们通过系统的crontab、cron.d以及系统日志无法定位问题的原因。
至于,为什么这个命令会导致IO夯,我们还在等腾讯云的答复。临时的解决方案是禁掉这个命令的执行(这也需要腾讯云出一个监控组件的hotfix包才能完成,单纯的删除sas3flash没有用)。
纵观整个排查过程,我们其实是走了一些弯路,通过分析IO特征,如果第一时间采用top就能更快的发现问题。
同时,我也深深感受到了以下一些痛点:
--结束END--
本文标题: 服务器诡异的请求超时问题
本文链接: https://www.lsjlt.com/news/5074.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-11
2024-05-11
2024-05-10
2024-05-07
2024-04-30
2024-04-30
2024-04-30
2024-04-29
2024-04-29
2024-04-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0