这篇文章主要介绍“为什么不能用uuid作为数据库主键”,在日常操作中,相信很多人在为什么不能用uuid作为数据库主键问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”为什么不能用
这篇文章主要介绍“为什么不能用uuid作为数据库主键”,在日常操作中,相信很多人在为什么不能用uuid作为数据库主键问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”为什么不能用uuid作为数据库主键”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
在日常开发中,数据库中主键id的生成方案,主要有三种
数据库自增ID
采用随机数生成不重复的ID
采用jdk提供的uuid
对于这三种方案,我发现在数据量少的情况下,没有特别的差异,但是当单表的数据量达到百万级以上时候,他们的性能有着显著的区别,光说理论不行,还得看实际程序测试,今天小编就带着大家一探究竟!
首先,我们在本地数据库中创建三张单表tb_uuid_1、tb_uuid_2、tb_uuid_3,同时设置tb_uuid_1表的主键为自增长模式,脚本如下:
CREATE TABLE `tb_uuid_1` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='主键ID自增长';CREATE TABLE `tb_uuid_2` ( `id` bigint(20) unsigned NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='主键ID随机数生成';CREATE TABLE `tb_uuid_3` ( `id` varchar(50) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='主键采用uuid生成';下面,我们采用SpringBoot + mybatis来实现插入测试。
2.1、数据库自增
以数据库自增为例,首先编写好各种实体、数据持久层操作,方便后续进行测试
public class UUID1 implements Serializable { private Long id; private String name; //省略set、get } public interface UUID1Mapper { @Insert("INSERT INTO tb_uuid_1(name) VALUES(#{name})") void insert(UUID1 uuid1); } @Test public void testInsert1(){ long start = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { uuid1Mapper.insert(new UUID1().setName("张三")); } long end = System.currentTimeMillis(); System.out.println("花费时间:" + (end - start)); }2.2、采用随机数生成ID
这里,我们采用twitter的雪花算法来实现随机数ID的生成,工具类如下:
public class SnowflakeIdWorker { private static SnowflakeIdWorker instance = new SnowflakeIdWorker(0,0); private final long twepoch = 1420041600000L; private final long workerIdBits = 5L; private final long datacenterIdBits = 5L; private final long maxWorkerId = -1L ^ (-1L << workerIdBits); private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); private final long sequenceBits = 12L; private final long workerIdShift = sequenceBits; private final long datacenterIdShift = sequenceBits + workerIdBits; private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; private final long sequenceMask = -1L ^ (-1L << sequenceBits); private long workerId; private long datacenterId; private long sequence = 0L; private long lastTimestamp = -1L; public SnowflakeIdWorker(long workerId, long datacenterId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.fORMat("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId)); } this.workerId = workerId; this.datacenterId = datacenterId; } public synchronized long nextId() { long timestamp = timeGen(); // 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常 if (timestamp < lastTimestamp) { throw new RuntimeException( String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } // 如果是同一时间生成的,则进行毫秒内序列 if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; // 毫秒内序列溢出 if (sequence == 0) { //阻塞到下一个毫秒,获得新的时间戳 timestamp = tilNextMillis(lastTimestamp); } } // 时间戳改变,毫秒内序列重置 else { sequence = 0L; } // 上次生成ID的时间截 lastTimestamp = timestamp; // 移位并通过或运算拼到一起组成64位的ID return ((timestamp - twepoch) << timestampLeftShift) // | (datacenterId << datacenterIdShift) // | (workerId << workerIdShift) // | sequence; } protected long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } protected long timeGen() { return System.currentTimeMillis(); } public static SnowflakeIdWorker getInstance(){ return instance; } public static void main(String[] args) throws InterruptedException { SnowflakeIdWorker idWorker = SnowflakeIdWorker.getInstance(); for (int i = 0; i < 10; i++) { long id = idWorker.nextId(); Thread.sleep(1); System.out.println(id); } } }其他的操作,与上面类似。
2.3、uuid
同样的,uuid的生成,我们事先也可以将工具类编写好:
public class UUIDGenerator { public static String getUUID(){ return UUID.randomUUID().toString(); } }最后的单元测试,代码如下:
@RunWith(springRunner.class) @SpringBootTest() public class UUID1Test { private static final Integer MAX_COUNT = 1000000; @Autowired private UUID1Mapper uuid1Mapper; @Autowired private UUID2Mapper uuid2Mapper; @Autowired private UUID3Mapper uuid3Mapper; @Test public void testInsert1(){ long start = System.currentTimeMillis(); for (int i = 0; i < MAX_COUNT; i++) { uuid1Mapper.insert(new UUID1().setName("张三")); } long end = System.currentTimeMillis(); System.out.println("自增ID,花费时间:" + (end - start)); } @Test public void testInsert2(){ long start = System.currentTimeMillis(); for (int i = 0; i < MAX_COUNT; i++) { long id = SnowflakeIdWorker.getInstance().nextId(); uuid2Mapper.insert(new UUID2().setId(id).setName("张三")); } long end = System.currentTimeMillis(); System.out.println("花费时间:" + (end - start)); } @Test public void testInsert3(){ long start = System.currentTimeMillis(); for (int i = 0; i < MAX_COUNT; i++) { String id = UUIDGenerator.getUUID(); uuid3Mapper.insert(new UUID3().setId(id).setName("张三")); } long end = System.currentTimeMillis(); System.out.println("花费时间:" + (end - start)); } }程序环境搭建完成之后,啥也不说了,直接撸起袖子,将单元测试跑起来!
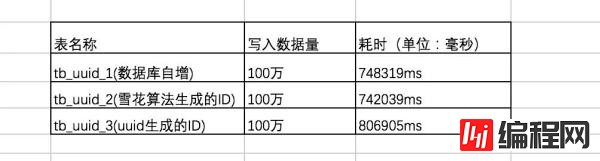
首先测试一下,插入100万数据的情况下,三者直接的耗时结果如下:
在原有的数据量上,我们继续插入30万条数据,三者耗时结果如下:
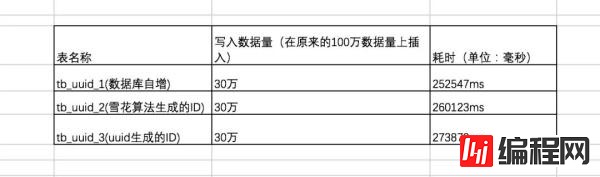
可以看出在数据量 100W 左右的时候,uuid的插入效率垫底,随着插入的数据量增长,uuid 生成的ID插入呈直线下降!
时间占用量总体效率排名为:自增ID > 雪花算法生成的ID >> uuid生成的ID。
在数据量较大的情况下,为什么uuid生成的ID远不如自增ID呢?
关于这点,我们可以从 Mysql 主键存储的内部结构来进行分析。
3.1、自增ID内部结构
自增的主键的值是顺序的,所以 Innodb 把每一条记录都存储在一条记录的后面。
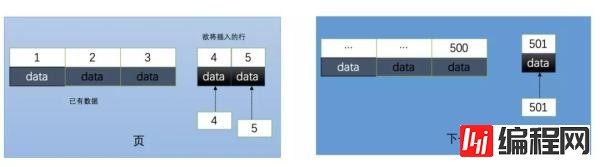
当达到页面的最大填充因子时候(innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的修改),会进行如下操作:
下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
3.2、使用uuid的索引内部结构
uuid相对顺序的自增id来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以innodb无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。
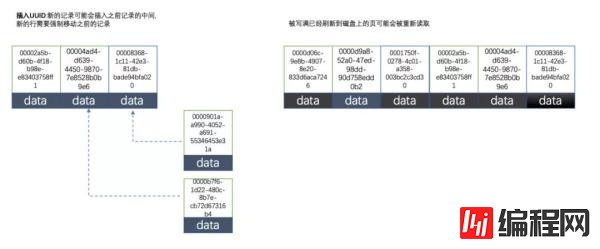
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机IO
因为写入是乱序的,innodb不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上
由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片
在把值载入到聚簇索引(innodb默认的索引类型)以后,有时候会需要做一次OPTIMEIZE TABLE来重建表并优化页的填充,这将又需要一定的时间消耗。
因此,在选择主键ID生成方案的时候,尽可能别采用uuid的方式来生成主键ID,随着数据量越大,插入性能会越低!
在实际使用过程中,推荐使用主键自增ID和雪花算法生成的随机ID。
但是使用自增ID也有缺点:
1、别人一旦爬取你的数据库,就可以根据数据库的自增id获取到你的业务增长信息,很容易进行数据窃取。2、其次,对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争。
总结起来,如果业务量小,推荐采用自增ID,如果业务量大,推荐采用雪花算法生成的随机ID。
到此,关于“为什么不能用uuid作为数据库主键”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注编程网网站,小编会继续努力为大家带来更多实用的文章!
--结束END--
本文标题: 为什么不能用uuid作为数据库主键
本文链接: https://www.lsjlt.com/news/56251.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-04-28
2024-04-28
2024-04-28
2024-04-28
2024-04-28
2024-04-28
2024-04-28
2024-04-28
2024-04-28
2024-04-28
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0