定义 索引(Index)是帮助Mysql高效获取数据的数据结构。那么什么数据结构可以用来高效的获取数据呢? 查看索引 mysql> show index from user; +-------+------------+----------

索引(Index)是帮助Mysql高效获取数据的数据结构。那么什么数据结构可以用来高效的获取数据呢?
mysql> show index from user;
+-------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| user | 0 | PRIMARY | 1 | id | A | 5 | NULL | NULL | | BTREE | | |
| user | 1 | idx_name_address | 1 | name | A | 5 | NULL | NULL | YES | BTREE | | |
| user | 1 | idx_name_address | 2 | address | A | 5 | NULL | NULL | YES | BTREE | | |
+-------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set
各列的含义:
Table:索引所在的表名。Non_unique:非唯一的索引,可以看到primary key是0,因为必须是唯一的。Key_name:索引的名字,用户可以通过这个名字来执行DROP INDEX。Seq_in_index:索引中该列的位置,如果看联合索引idx_name_address就比较直观了。Column_name:索引列的名称。Cardinality:非常关键的值,表示索引中唯一值的数目的估计值。Cardinality/表的行数(Cardinality/n_rows_in_table)应尽可能接近1,如果非常小,那么用户需要考虑是否可以删除此索引。Sub_part:是否是列的部分被索引。如果看idx_b这个索引,这里显示100,表示只对b列的前100字符进行索引。如果索引整个列,则该字段为NULL。Packed:关键字如何被压缩。如果没有被压缩,则为NULL。Null:是否索引的列含有NULL值。可以看到idx_b这里为Yes,因为定义的列b允许NULL值。Index_type:索引的类型。InnoDB存储引擎只支持B+树索引,所以这里显示的都是BTREE。Comment:注释。我们平常见到的检索效率比较高的数据结构有二叉树,平衡二叉树等。
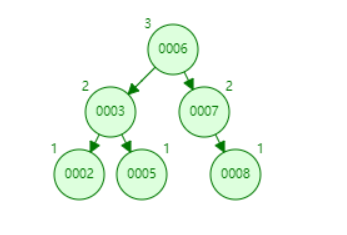
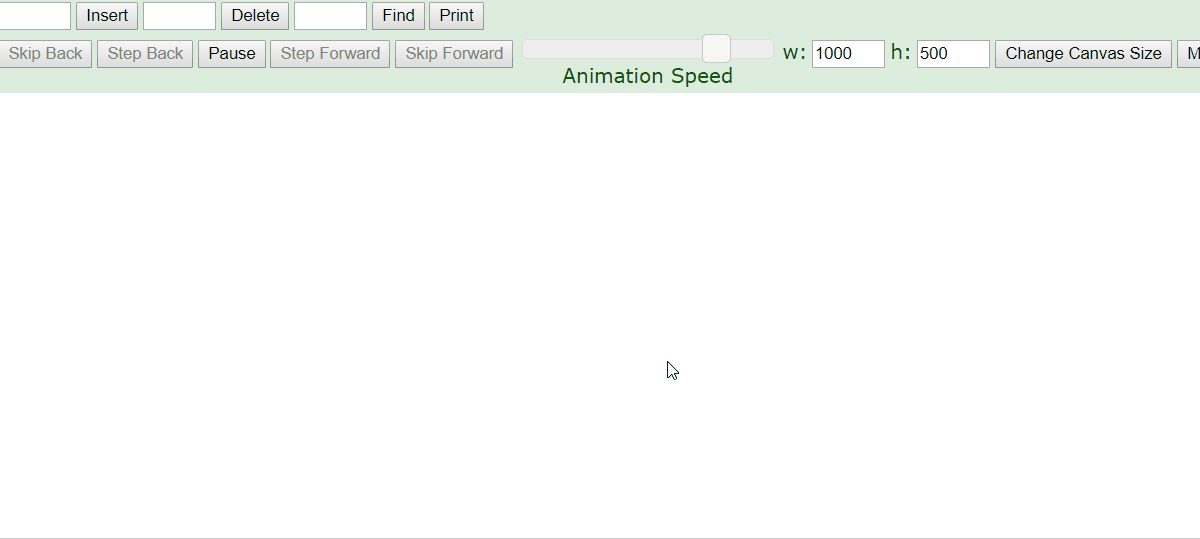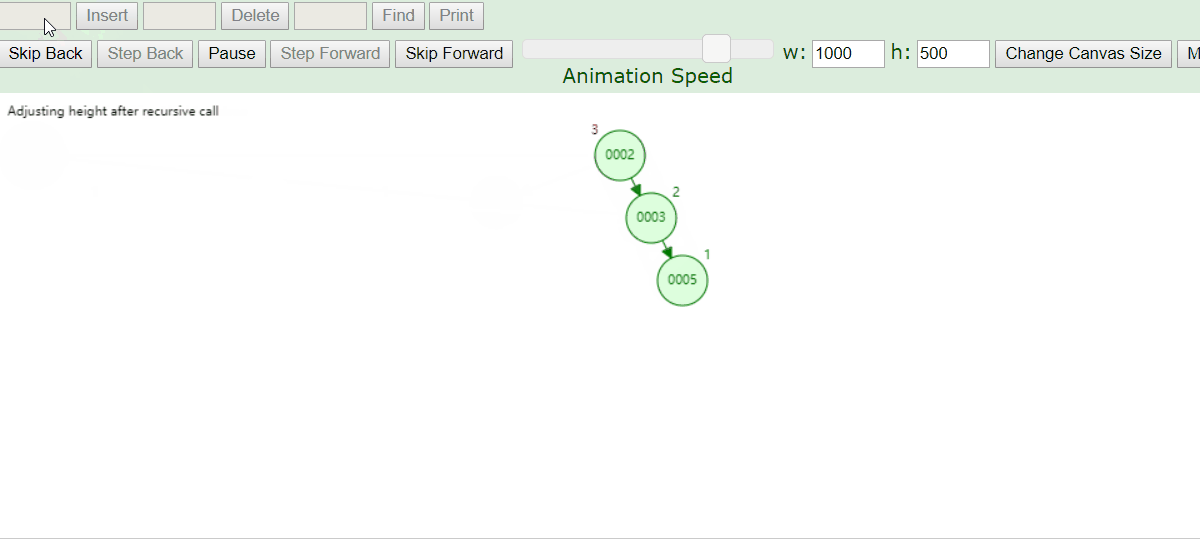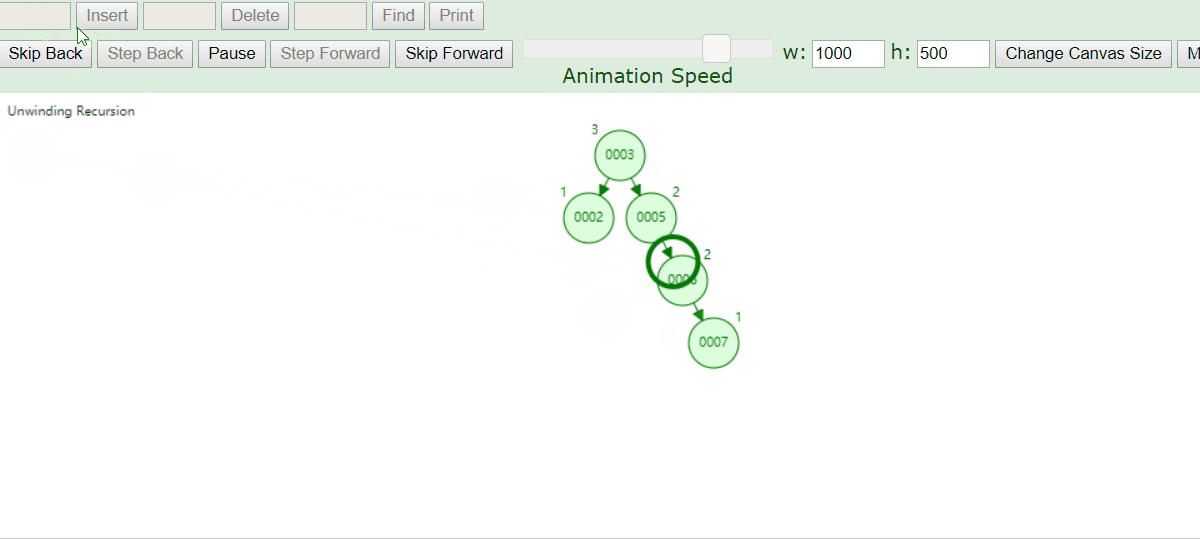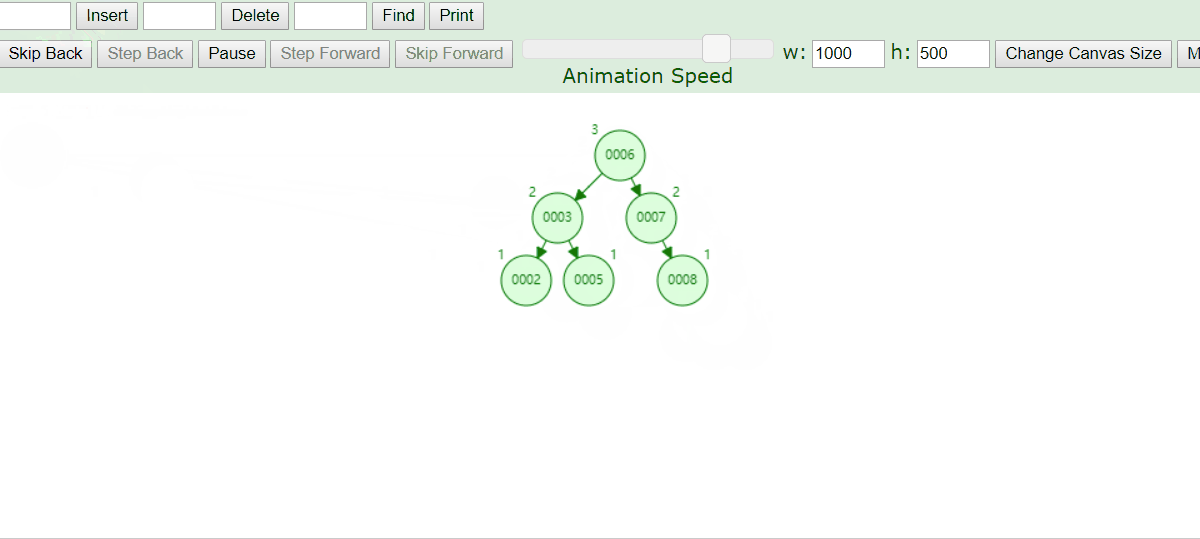
左子树的键值总是小于根的键值,右子树的键值总是大于根的键值。
如图如果我们查询8只需要查找3次就行了,但是二叉树可以任意构造,同样是2、3、5、6、7、8也可以构造成如下:
这时我们同样是查询8这个节点,我们需要查询5次,查询效率就比较低了。
因为二叉树存在构造方式的不同会导致查询效率比较低的情况,所以后来又提出了平衡二叉树。
首先符合二叉查找树的定义,其次必须满足任何节点的两个子树的高度最大差为1。
上图是一个平衡二叉树的动态示例,通过示例我们可以发现,为了保证二叉树的平衡我们需要对树进行一定的转换操作。但是为什么没用平衡二叉树来做索引呢?下面我们来看下查找元素9的过程:
如果红圈每移动一次就代表一次IO操作的话,那么查找元素9就需要3次I/O,而在我们计算机系统里面,IO成本是远高于内存中查找的过程。
我们从磁盘读取数据大致可以分为三步:寻道、旋转延迟和数据传输:
60*1000/7200/2 = 4.17ms。根据上面的计算方式,刚刚查找9这个数值,就IO需要花费27ms,现在才7个数据,要是数据量一大,树的高度就会很高,就IO所花费的时间我们就无法接受。
为了降低树的高度,进而减少IO操作,于是又在平衡二叉树上有进行了演化,设计出了B树。
[(指针)(数据)(指针)];这是一颗最大度是3的B树,依次插入数据1,2,3,4,5,6 效果如下:
为了进一步减小数的高度,在B-Tree的基础上演化而来了B+Tree:
B+Tree插入的动态演示,这是一颗最大度是3的B树,依次插入数据1,2,3,4,5,6 效果如下:
从图中我们可以看到在插入元素5的时候发生了拆分,拆分就意味着树的高度有可能会增加,为了尽量减拆分,B+树同样提供了类似于平衡二叉树的旋转(Rotation)功能。旋转发生在Leaf Page已经满,但是其的左右兄弟节点没有满的情况下。这时B+树并不会急于去做拆分页的操作,而是将记录移到所在页的兄弟节点上,如插入5,最后的结果是如下图:
通过上面的介绍我们可以发现,数据结构不停的演化主要还是在降低查询数据时I/O的次数,那B+Tree的树节点到底多大合适呢,mysql默认树节点的大小是16K,通过如下命令可以查询:
mysql> show variables like "innodb_page_size";
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
1 row in set
页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页,每页大小通常为4k,主存和磁盘以页为单位交换数据。而为了尽量减少I/O,磁盘往往不是严格按照需求读取数据,而是每次都会预读,预读发生在物理上连续的空间上,预读的大小一般是页的整倍数。
基于预读原理,Mysql索引的树节点大小也也设计为页的整倍数,即4K的整倍数,考虑到磁盘的预读,所以MySQL默认的树节点大小为4页即16K。
为啥不设置的更大一点呢?从上面我们结构图我们可以发现,并不是所有的树节点都能装满,如果出现未装满的情况就会发生空间浪费;还有就是磁盘预读页数还是有限制的,不会无限读取后面的数据,否则就不叫预读了。
将数据文件和索引文件一起存放的索引就是聚集索引,否则是非聚集索引。
InnoDB会按照主键构造一颗B+树,并且在叶子节点存放一行记录的完整数据,所以InnoDB的主键索引就是一个聚集索引。
一张表只能有一个主键,所以也只能有一个聚集索引。在大多数情况下优化器会选择使用聚集索引,因为使用聚集索引可以直接找到数据。
聚集索引的存储并不是物理上连续的,而是逻辑上连续的。这其中有两点:一是前面说过的页通过双向链表链接,页按照主键的顺序排序;另一点是每个页中的记录也是通过双向链表进行维护的,物理存储上可以同样不按照主键存储。
非聚集索引也称为辅助索引,叶子节点并不存放完整的数据,而是存放key和一个书签(bookmark)。该书签用来告诉InnoDB存储引擎哪里可以找到与索引相对应的行数据。
当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后再通过主键索引来找到一个完整的行记录。例如,在一棵高度为3的辅助索引树中查找数据,那需要对这棵辅助索引树遍历3次找到指定主键,如果聚集索引树的高度同样为3,那么还需要对聚集索引树进行3次查找,最终找到一个完整的行数据所在的页,因此一共需要6次逻辑IO访问以得到最终的一个数据页。
通过上面介绍我们可以发现,当使用辅助索引的时候可能会出现离散读的情况,但是一般的数据库都通过实现预读(read ahead)技术来避免多次的离散读操作。
联合索引其实就是用多个列创建的索引,如:
CREATE TABLE t (
a INT,
b INT,
PRIMARY KEY (a),
KEY idx_a_b (a, b)
) ENGINE = INNODB;
联合索引也是一棵B+Tree,不同的是联合索引的键值的数量不是1,而是大于等于2,如图:
叶子节点是按照(a,b)进行排序后的存储的,所以当我们执行SELECT * FROM TABLE WHERE a=xxx and b=xxx或者SELECT * FROM TABLE WHERE a=xxx是可以使用索引的,因为最前面a这个字段在索引idx_a_b 上是有序的;但是SELECT * FROM TABLE WHERE b=xxx是不可以使用到索引的,主要是因为b在idx_a_b 索引上是无序的,会产生离散读。
覆盖索引就是从辅助索引中就可以得到查询的记录。
使用覆盖索引的一个好处是:
Multi-Range Read优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问。
适用于range,ref,eq_ref类型的查询。
Multi-Range Read优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问。
适用于range,ref,eq_ref类型的查询。
Multi-Range Read优化可以通过参数optimizer_switch中的标记(flag)来控制,当mrr为on时,表示启用Multi-Range Read优化。mrr_cost_based标记表示是否通过costbased的方式来选择是否启用mrr。若将mrr设为on,mrr_cost_based设为off,则总是启用Multi-Range Read优化。
mysql> select @@optimizer_switch;
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| @@optimizer_switch |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set
mysql>set @@optimizer_switch="mrr=no,mrr_cost_based=off";
Query OK, 0 rows affected
参数read_rnd_buffer_size用来控制键值的缓冲区大小,默认是256k;
mysql> SET @@read_rnd_buffer_size=524288;
Query OK, 0 rows affected
mysql> SELECT @@read_rnd_buffer_size;
+------------------------+
| @@read_rnd_buffer_size |
+------------------------+
| 524288 |
+------------------------+
1 row in set
一般情况下,当进行索引查询时,首先根据索引来查找记录,然后再根据WHERE条件来过滤记录。而在支持Index Condition Pushdown后,MySQL数据库会在取出索引的同时,判断是否可以进行WHERE条件的过滤,也就是将WHERE的部分过滤操作放在了存储引擎层。其实就是使用覆盖索引直接来做WHERE条件的过滤。
因为可以直接使用索引来做WHERE条件的过滤,所以就少了去查询聚集索引的IO。
支持range、ref、eq_ref、ref_or_null类型的查询
Index Condition Pushdown优化可以将查询效率在原有MySQL 5.5版本的技术上提高23%。而同时启用Mulit-RangeRead优化后,性能还能有400%的提升!
https://www.cs.usfca.edu/~galles/visualization/AlGorithms.html Https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html https://www.cs.usfca.edu/~galles/visualization/BTree.html
--结束END--
本文标题: MySQL索引原理
本文链接: https://www.lsjlt.com/news/5685.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
2024-05-03
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0