数据接入 数据的接入可以通过将数据实时写入kafka进行接入,不管是直接的写入还是通过oracle和Mysql的实时接入方式,比如oracle的ogg,mysql的binlog ogg Golden Gate(简称OGG)提


数据的接入可以通过将数据实时写入kafka进行接入,不管是直接的写入还是通过oracle和Mysql的实时接入方式,比如oracle的ogg,mysql的binlog
Golden Gate(简称OGG)提供异构环境下交易数据的实时捕捉、变换、投递。
通过OGG可以实时的将oracle中的数据写入Kafka中。

对生产系统影响小:实时读取交易日志,以低资源占用实现大交易量数据实时复制
以交易为单位复制,保证交易一致性:只同步已提交的数据
高性能
Mysql 的二进制日志 binlog 可以说是 MySQL 最重要的日志,它记录了所有的 DDL 和 DML 语句(除了数据查询语句select、show等),以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。binlog 的主要目的是复制和恢复。
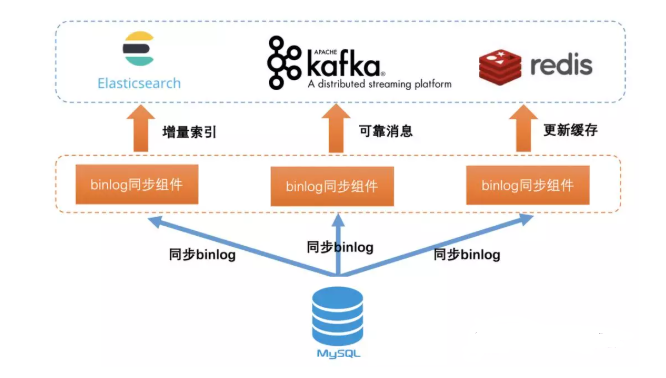
通过这些手段,可以将数据同步到kafka也就是我们的实时系统中来。
Apache Kafka Connector可以方便对kafka数据的接入。
依赖
org.apache.flink flink-connector-kafka_2.11 1.9.0
必须有的:
topic名称
用于反序列化Kafka数据的DeserializationSchema / KafkaDeserializationSchema
配置参数:“bootstrap.servers” “group.id” (kafka0.8还需要 “ZooKeeper.connect”)
val properties = new Properties()properties.setProperty("bootstrap.servers", "localhost:9092")// only required for Kafka 0.8properties.setProperty("zookeeper.connect", "localhost:2181")properties.setProperty("group.id", "test")stream = env .addSource(new FlinkKafkaConsumer[String]("topic", new SimpleStringSchema(), properties)) .print()
在许多情况下,记录的时间戳(显式或隐式)嵌入记录本身。另外,用户可能想要周期性地或以不规则的方式发出水印。
我们可以定义好Timestamp Extractors / Watermark Emitters,通过以下方式将其传递给消费者
val env = StreamExecutionEnvironment.getExecutionEnvironment()val myConsumer = new FlinkKafkaConsumer[String](...)myConsumer.setStartFromEarliest() // start from the earliest record possiblemyConsumer.setStartFromLatest() // start from the latest recordmyConsumer.setStartFromTimestamp(...) // start from specified epoch timestamp (milliseconds)myConsumer.setStartFromGroupOffsets() // the default behaviour//指定位置//val specificStartOffsets = new java.util.HashMap[KafkaTopicPartition, java.lang.Long]()//specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L)//myConsumer.setStartFromSpecificOffsets(specificStartOffsets)val stream = env.addSource(myConsumer)
启用Flink的检查点后,Flink Kafka Consumer将使用主题中的记录,并以一致的方式定期检查其所有Kafka偏移以及其他操作的状态。如果作业失败,Flink会将流式程序恢复到最新检查点的状态,并从存储在检查点中的偏移量开始重新使用Kafka的记录。
如果禁用了检查点,则Flink Kafka Consumer依赖于内部使用的Kafka客户端的自动定期偏移提交功能。
如果启用了检查点,则Flink Kafka Consumer将在检查点完成时提交存储在检查点状态中的偏移量。
val env = StreamExecutionEnvironment.getExecutionEnvironment()env.enableCheckpointing(5000) // checkpoint every 5000 msecs
Flink消费Kafka完整代码:
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaConsumer { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); //构建FlinkKafkaConsumer FlinkKafkaConsumer myConsumer = new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties); //指定偏移量 myConsumer.setStartFromEarliest(); DataStream stream = env .addSource(myConsumer); env.enableCheckpointing(5000); stream.print(); env.execute("Flink Streaming Java API Skeleton"); }
这样数据已经实时的接入我们系统中,可以在Flink中对数据进行处理了,那么如何对标签进行计算呢? 标签的计算过程极大的依赖于数据仓库的能力,所以拥有了一个好的数据仓库,标签也就很容易计算出来了。
数据仓库是指一个面向主题的、集成的、稳定的、随时间变化的数据的集合,以用于支持管理决策的过程。
(1)面向主题
业务数据库中的数据主要针对事物处理任务,各个业务系统之间是各自分离的。而数据仓库中的数据是按照一定的主题进行组织的
(2)集成
数据仓库中存储的数据是从业务数据库中提取出来的,但并不是原有数据的简单复制,而是经过了抽取、清理、转换(ETL)等工作。
业务数据库记录的是每一项业务处理的流水账,这些数据不适合于分析处理,进入数据仓库之前需要经过系列计算,同时抛弃一些分析处理不需要的数据。
(3)稳定
操作型数据库系统中一般只存储短期数据,因此其数据是不稳定的,记录的是系统中数据变化的瞬态。
数据仓库中的数据大多表示过去某一时刻的数据,主要用于查询、分析,不像业务系统中数据库一样经常修改。一般数据仓库构建完成,主要用于访问

OLTP 联机事务处理
OLTP是传统关系型数据库的主要应用,主要用于日常事物、交易系统的处理
1、数据量存储相对来说不大
2、实时性要求高,需要支持事物
3、数据一般存储在关系型数据库(oracle或mysql中)
OLAP 联机分析处理
OLAP是数据仓库的主要应用,支持复杂的分析查询,侧重决策支持
1、实时性要求不是很高,ETL一般都是T+1的数据;
2、数据量很大;
3、主要用于分析决策;
星形模型是最常用的数据仓库设计结构。由一个事实表和一组维表组成,每个维表都有一个维主键。
该模式核心是事实表,通过事实表将各种不同的维表连接起来,各个维表中的对象通过事实表与另一个维表中的对象相关联,这样建立各个维表对象之间的联系
维表:用于存放维度信息,包括维的属性和层次结构;
事实表:是用来记录业务事实并做相应指标统计的表。同维表相比,事实表记录数量很多
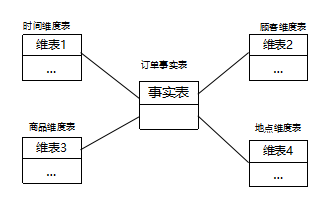
雪花模型是对星形模型的扩展,每一个维表都可以向外连接多个详细类别表。除了具有星形模式中维表的功能外,还连接对事实表进行详细描述的维度,可进一步细化查看数据的粒度
例如:地点维表包含属性集{location_id,街道,城市,省,国家}。这种模式通过地点维度表的city_id与城市维度表的city_id相关联,得到如{101,“解放大道10号”,“武汉”,“湖北省”,“中国”}、{255,“解放大道85号”,“武汉”,“湖北省”,“中国”}这样的记录。
星形模型是最基本的模式,一个星形模型有多个维表,只存在一个事实表。在星形模式的基础上,用多个表来描述一个复杂维,构造维表的多层结构,就得到雪花模型


清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解
脏数据清洗:屏蔽原始数据的异常
屏蔽业务影响:不必改一次业务就需要重新接入数据
数据血缘追踪:简单来讲可以这样理解,我们最终给业务呈现的是能直接使用的一张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
把复杂问题简单化。将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
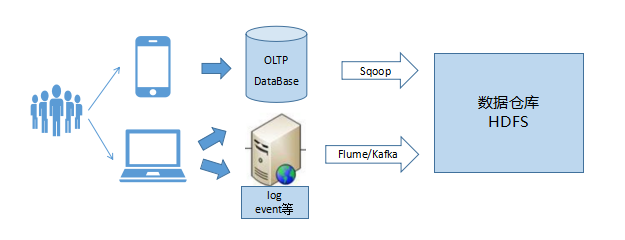
数据仓库的数据直接对接OLAP或日志类数据,
用户画像只是站在用户的角度,对数据仓库数据做进一步的建模加工。因此每天画像标签相关数据的调度依赖上游数据仓库相关任务执行完成。
在了解了数据仓库以后,我们就可以进行标签的计算了。在开发好标签的逻辑以后,将数据写入Hive和druid中,完成实时与离线的标签开发工作。
Flink从1.9开始支持集成Hive,不过1.9版本为beta版,不推荐在生产环境中使用。在最新版Flink1.10版本,标志着对 Blink的整合宣告完成,随着对 Hive 的生产级别集成,Hive作为数据仓库系统的绝对核心,承担着绝大多数的离线数据ETL计算和数据管理,期待Flink未来对Hive的完美支持。
而 HiveCatalog 会与一个 Hive Metastore 的实例连接,提供元数据持久化的能力。要使用 Flink 与 Hive 进行交互,用户需要配置一个 HiveCatalog,并通过 HiveCatalog 访问 Hive 中的元数据。
要与Hive集成,需要在Flink的lib目录下添加额外的依赖jar包,以使集成在Table API程序或SQL Client中的SQL中起作用。或者,可以将这些依赖项放在文件夹中,并分别使用Table API程序或SQL Client 的-C 或-l选项将它们添加到classpath中。本文使用第一种方式,即将jar包直接复制到$FLINK_HOME/lib目录下。本文使用的Hive版本为2.3.4(对于不同版本的Hive,可以参照官网选择不同的jar包依赖),总共需要3个jar包,如下:
org.apache.flink
flink-connector-hive_2.11
1.10.0
provided
org.apache.flink
flink-table-api-java-bridge_2.11
1.10.0
provided
org.apache.hive
hive-exec
${hive.version}
provided
package com.flink.sql.hiveintegration;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
public class FlinkHiveIntegration {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() // 使用BlinkPlanner
.inBatchMode() // Batch模式,默认为StreamingMode
.build();
//使用StreamingMode
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive"; // Catalog名称,定义一个唯一的名称表示
String defaultDatabase = "qfbap_ods"; // 默认数据库名称
String hiveConfDir = "/opt/modules/apache-hive-2.3.4-bin/conf"; // hive-site.xml路径
String version = "2.3.4"; // Hive版本号
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
tableEnv.reGISterCatalog("myhive", hive);
tableEnv.useCatalog("myhive");
// 创建数据库,目前不支持创建hive表
String createDbSql = "CREATE DATABASE IF NOT EXISTS myhive.test123";
tableEnv.sqlUpdate(createDbSql);
}
}
可以将Flink分析好的数据写回kafka,然后在druid中接入数据,也可以将数据直接写入druid,以下为示例代码:
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.8.RELEASE
com.flinkdruid
FlinkDruid
0.0.1-SNAPSHOT
FlinkDruid
Flink Druid Connection
1.8
org.springframework.boot
spring-boot-starter-WEB
org.springframework.boot
spring-boot-starter
org.apache.flink
flink-core
1.9.0
org.apache.flink
flink-clients_2.12
1.9.0
org.springframework.boot
spring-boot-maven-plugin
@SpringBootApplication
public class FlinkDruidApp {
private static String url = "Http://localhost:8200/v1/post/wikipedia";
private static RestTemplate template;
private static HttpHeaders headers;
FlinkDruidApp() {
template = new RestTemplate();
headers = new HttpHeaders();
headers.setAccept(Arrays.asList(MediaType.APPLICATION_JSON));
headers.setContentType(MediaType.APPLICATION_jsON);
}
public static void main(String[] args) throws Exception {
SpringApplication.run(FlinkDruidApp.class, args);
// Creating Flink Execution Environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//Define data source
DataSet data = env.readTextFile("/wikiticker-2015-09-12-sampled.json");
// Trasformation on the data
data.map(x -> {
return httpsPost(x).toString();
}).print();
}
// http post method to post data in Druid
private static ResponseEntity httpsPost(String json) {
HttpEntity requestEntity =
new HttpEntity<>(json, headers);
ResponseEntity response =
template.exchange("http://localhost:8200/v1/post/wikipedia", HttpMethod.POST, requestEntity,
String.class);
return response;
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
标签的开发工作繁琐,需要不断的开发并且优化,但是如何将做好的标签提供出去产生真正的价值呢? 下一章,我们将介绍用户画像产品化,未完待续~
参考文献
《用户画像:方法论与工程化解决方案》
更多实时数据分析相关博文与科技资讯,欢迎关注 “实时流式计算”

--结束END--
本文标题: 实时标签开发——从零开始搭建实时用户画像(五)
本文链接: https://www.lsjlt.com/news/6584.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
2024-05-02
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0