基数 一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好 我们可以使用 show index 方法,看到一个索引的基数 Mysql 是怎样得到索引的基数的呢? 采样

一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好
我们可以使用 show index 方法,看到一个索引的基数
采样统计 : 因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。
采样统计的时候,InnoDB 默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数
而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过 1/M 的时候,会自动触发重新做一次索引统计
在 mysql 中,有两种存储索引统计的方式,可以通过设置参数 innodb_stats_persistent 的值来选择:设置为 on 的时候,表示统计信息会持久化存储。这时,默认的 N 是 20,M 是 10。设置为 off 的时候,表示统计信息只存储在内存中。这时,默认的 N 是 8,M 是 16。
analyze table t 命令,可以用来重新统计索引信息
一张email表给email列加索引,语句如下
//挑选一个在你可接受的损失范围的长度即可
mysql> select count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7
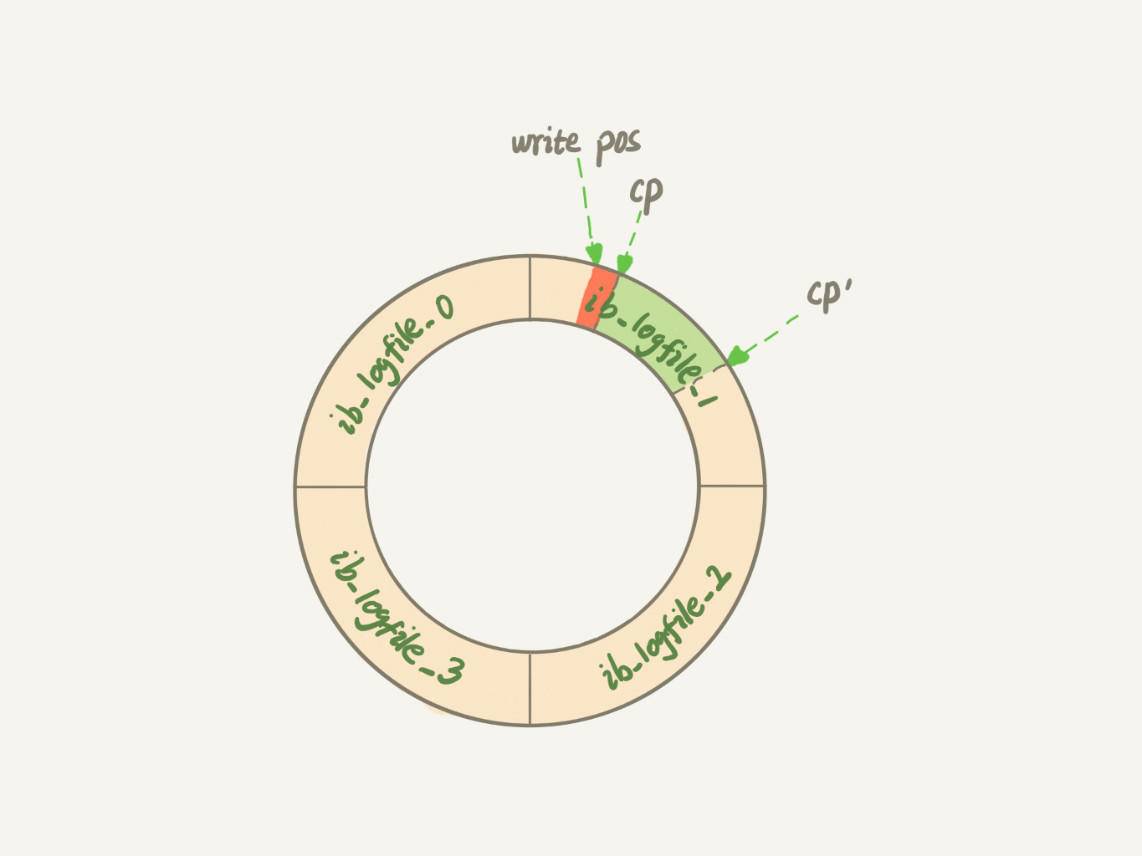
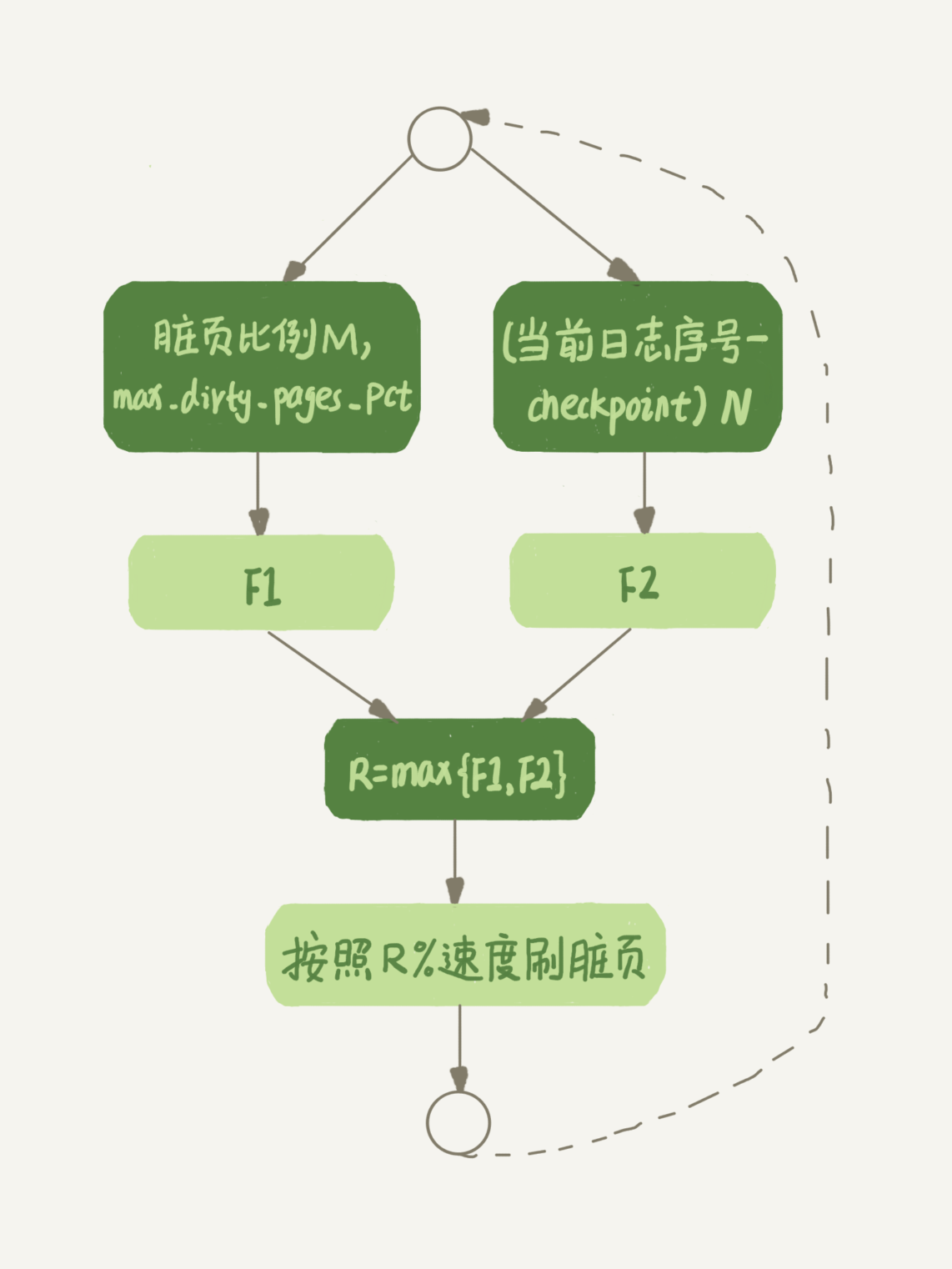
from t;平时执行很快的更新操作,其实就是在写内存和日志,而 Mysql 偶尔“抖”一下的那个瞬间,可能就是在刷脏页(flush) ,一下四种情况
--结束END--
本文标题: 20200617学习笔记
本文链接: https://www.lsjlt.com/news/6684.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
2024-05-11
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0