这篇文章主要讲解了“PolarDB数据库性能实例分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“PolarDB数据库性能实例分析”吧!赛题概览比赛总体分成
这篇文章主要讲解了“PolarDB数据库性能实例分析”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“PolarDB数据库性能实例分析”吧!
比赛总体分成了初赛和复赛两个阶段,整体要求实现一个简化、高效的 kv 存储引擎
初赛要求支持 Write、Read 接口。
public abstract void write(byte[] key, byte[] value);public abstract byte[] read(byte[] key);复赛在初赛题目基础上,还需要额外实现一个 Range 接口。
public abstract void range(byte[] lower, byte[] upper, AbstractVisitor visitor);程序评测逻辑 分为2个阶段: 1)Recover 正确性评测: 此阶段评测程序会并发写入特定数据(key 8B、value 4KB)同时进行任意次 kill -9 来模拟进程意外退出(参赛引擎需要保证进程意外退出时数据持久化不丢失),接着重新打开 DB,调用 Read、Range 接口来进行正确性校验
2)性能评测
随机写入:64 个线程并发随机写入,每个线程使用 Write 各写 100 万次随机数据(key 8B、value 4KB)
随机读取:64 个线程并发随机读取,每个线程各使用 Read 读取 100 万次随机数据
顺序读取:64 个线程并发顺序读取,每个线程各使用 Range 有序(增序)遍历全量数据 2 次 注: 2.2 阶段会对所有读取的 kv 校验是否匹配,如不通过则终止,评测失败; 2.3 阶段除了对迭代出来每条的 kv校 验是否匹配外,还会额外校验是否严格字典序递增,如不通过则终止,评测失败。
语言限定:c++ & JAVA,一起排名
关于文件 io 操作的一些基本常识,我已经在专题文章中进行了介绍,如果你没有浏览那篇文章,建议先行浏览一下:文件IO操作的一些最佳实践。再回归赛题,先对赛题中的几个关键词来进行解读。
key 为固定的 8 字节,因此可使用 long 来表示。
value 为 4kb,这节省了我们很大的工作量,因为 4kb 的整数倍落盘是非常磁盘 IO 友好的。
value 为 4kb 的另一个好处是我们再内存做索引时,可以使用 int 而不是 long,来记录数据的逻辑偏移量:LogicOffset = PhysicalOffset / 4096,可以将 offset 的内存占用量减少一半。
首先赛题明确表示会进行 kill -9 并验证数据的一致性,这加大了我们在内存中做 write buffer 的难度。但它并没有要求断电不丢失,这间接地阐释了一点:我们可以使用 pageCache 来做写入缓存,在具体代码中我使用了 PageCache 来充当数据和索引的写入缓冲(两者策略不同)。同时这点也限制了参赛选手,不能使用 aiO 这样的异步落盘方式。
赛题分为了随机写,随机读,顺序读三个阶段,每个阶段都会重新 open,且不会发生随机写到一半校验随机读这样的行为,所以我们在随机写阶段不需要在内存维护索引,而是直接落盘。随机读和顺序读阶段,磁盘均存在数据,open 阶段需要恢复索引,可以使用多线程并发恢复。
同时,赛题还有存在一些隐性的测评细节没有披露给大家,但通过测试,我们可以得知这些信息。
虽然我们可以使用 PageCache,但评测程序在每个阶段之后都使用脚本清空了 PageCache,并且将这部分时间也算进了最终的成绩之中,所以有人感到奇怪:三个阶段的耗时相加比输出出来的成绩要差,其实那几秒便是清空 PageCache 的耗时。
#清理 pagecache (页缓存)
sysctl -w vm.drop_caches=1
#清理 dentries(目录缓存)和 inodes
sysctl -w vm.drop_caches=2
#清理pagecache、dentries和inodes
sysctl -w vm.drop_caches=3这一点启发我们,不能毫无节制的使用 PageCache,也正是因为这一点,一定程度上使得 Direct IO 这一操作成了本次竞赛的银弹。
这一个隐性条件可谓是本次比赛的关键,因为它涉及到 Range 部分的架构设计。本次比赛的 key 共计 6400w,但是他们的分布都是均匀的,在《文件IO操作的一些最佳实践》 一文中我们已经提到了数据分区的好处,可以大大减少顺序读写的锁冲突,而 key 的分布均匀这一特性,启发我们在做数据分区时,可以按照 key 的搞 n 位来做 hash,从而确保 key 两个分区之间整体有序(分区内部无序)。实际我尝试了将数据分成 1024、2048 个分区,效果最佳。
赛题要求 64 个线程 Range 两次全量的数据,限时 1h,这也启发了我们,如果不对数据进行缓存,想要在 1h 内完成比赛是不可能的,所以,我们的架构设计应该尽量以 Range 为核心,兼顾随机写和随机读。Range 部分也是最容易拉开差距的一个环节。
首先需要明确的是,随机写指的是 key 的写入是随机的,但我们可以根据 key hash,将随机写转换为对应分区文件的顺序写。
public class HighTenPartitioner implements Partitionable {
@Override
public int getPartition(byte[] key) {
return ((key[0] & 0xff) << 2) | ((key[1] & 0xff) >> 6);
}
}明确了高位分区的前提再来看整体的架构就变得明朗了
全局视角
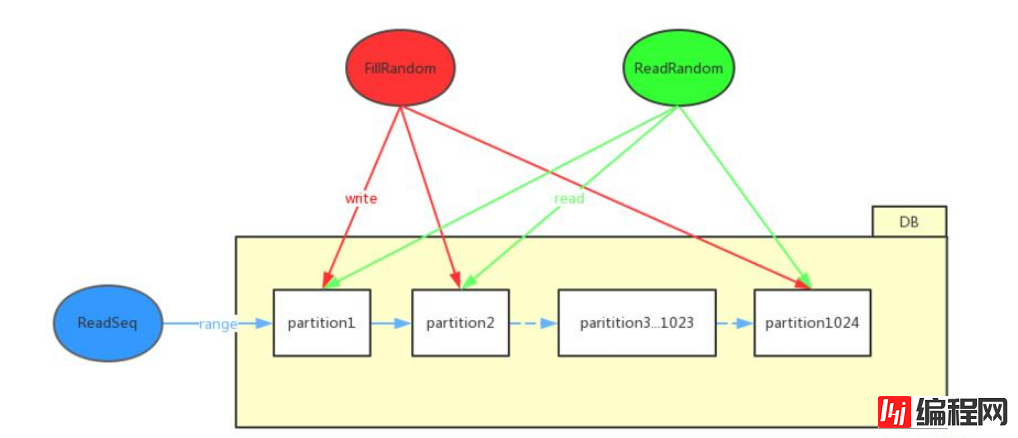
分区视角
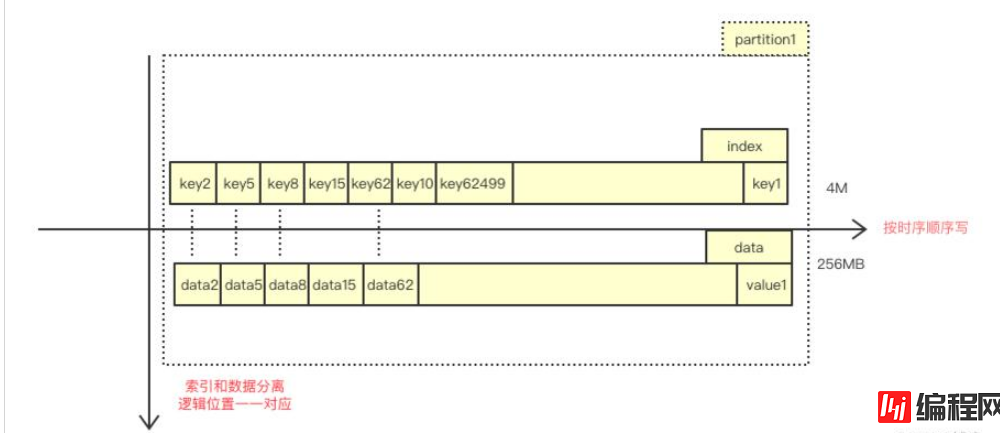
内存视角
内存中仅仅维护有序的 key[1024][625000] 数组和 offset[1024][625000] 数组。
上述两张图对整体的架构进行了一个很好的诠释,利用数据分布均匀的特性,可以将全局数据 hash 成 1024 个分区,在每个分区中存放两类文件:索引文件和数据文件。在随机写入阶段,根据 key 获得该数据对应分区位置,并按照时序,顺序追加到文件末尾,将全局随机写转换为局部顺序写。利用索引和数据一一对应的特性,我们也不需要将 data 的逻辑偏移量落盘,在 recover 阶段可以按照恢复 key 的次序,反推出 value 的逻辑偏移量。
在 range 阶段,由于我们事先按照 key 的高 10 为做了分区,所以我们可以认定一个事实,patition(N) 中的任何一个数据一定大于 partition(N-1) 中的任何一个数据,于是我们可以采用大块读,将一个 partition 整体读进内存,供 64 个 visit 线程消费。到这儿便奠定了整体的基调:读盘线程负责按分区读盘进入内存,64 个 visit 线程负责消费内存,按照 key 的次序随机访问内存,进行 Visitor 的回调。
介绍完了整体架构,我们分阶段来看一下各个阶段的一些细节优化点,有一些优化在各个环节都会出现,未避免重复,第二次出现的同一优化点我就不赘述了,仅一句带过。
主要看数据落盘,后讨论索引落盘。磁盘 IO 类型的比赛,第一步便是测量磁盘的 IOPS 以及多少个线程一次读写多大的缓存能够打满 IO,在固定 64 线程写入的前提下,16kb,64kb 均可以达到最理想 IOPS,所以理所当然的想到,可以为每一个分区分配一个写入缓存,凑齐 4 个 value 落盘。但是此次比赛,要做到 kill -9 不丢失数据,不能简单地在内存中分配一个 ByteBuffer.allocate(4096*4);, 而是可以考虑使用 mmap 内存映射出一片写入缓冲,凑齐 4 个刷盘,这样在 kill -9 之后,PageCache 不会丢失。实测 16kb 落盘比 4kb 落盘要快 6s 左右。
索引文件的落盘则没有太大的争议,由于 key 的数据量为固定的 8B,所以 mmap 可以发挥出它写小数据的优势,将 pageCache 利用起来,实测 mmap 相比 filechannel 写索引要快 3s 左右,相信如果把 polardb 这块盘换做其他普通的 ssd,这个数值还要增加。
一开始审题不清,在随机写之后误以为会立刻随机读,实际上每个阶段都是独立的,所以不需要在写入时维护内存索引;其次,之前的架构图中也已经提及,不需要写入连带 key+offset 一起写入文件,recover 阶段可以按照恢复索引的顺序,反推出 data 的逻辑偏移,因为我们的 key 和 data 在同一个分区内的位置是一一对应的。
recover 阶段的逻辑实际上包含在程序的 open 接口之中,我们需要再数据库引擎启动时,将索引从数据文件恢复到内存之中,在这之中也存在一些细节优化点。
由于 1024 个分区的存在,我们可以使用 64 个线程 (经验值) 并发地恢复索引,使用快速排序对 key[1024][62500] 数组和 offset[1024][62500] 进行 sort,之后再 compact,对 key 进行去重。需要注意的一点是,不要使用结构体,将 key 和 offset 封装在一起,这会使得排序和之后的二分效率非常低,这之中涉及到 CPU 缓存行的知识点,不了解的读者可以翻阅我之前的博客: 《CPU Cache 与缓存行》
// wrongpublic class KeyOffset { long key; int offset;}整个 recover 阶段耗时为 1s,跟 cpp 选手交流后发现恢复流程比之慢了 600ms,这中间让我觉得比较诡异,加载索引和排序不应该这么慢才对,最终也没有优化成功。
随机读流程没有太大的优化点,优化空间实在有限,实现思路便是先根据 key 定位到分区,之后在有序的 key 数据中二分查找到 key/offset,拿到 data 的逻辑偏移和分区编号,便可以愉快的随机读了,随机读阶段没有太大的优化点,但仍然比 cpp 选手慢了 2-3s,可能是语言无法越过的差距。
Range 环节是整个比赛的大头,也是拉开差距的分水岭。前面我们已经大概提到了 Range 的整体思路是一个生产者消费者模型,n 个生成者负责从磁盘读数据进入内存(n 作为变量,通过 benchmark 来确定多少合适,最终实测 n 为 4 时效果最佳),64 个消费者负责调用 visit 回调,来验证数据,visit 过程就是随机读内存的过程。在 Range 阶段,剩余的内存还有大概 1G 左右,所以我分配了 4 个堆外缓冲,一个 256M,从而可以缓存 4 个分区的数据,并且,我为每一个分区分配了一个读盘线程,负责 load 数据进入缓存,供 64 个消费者消费。
具体的顺序读架构可以参见下图:
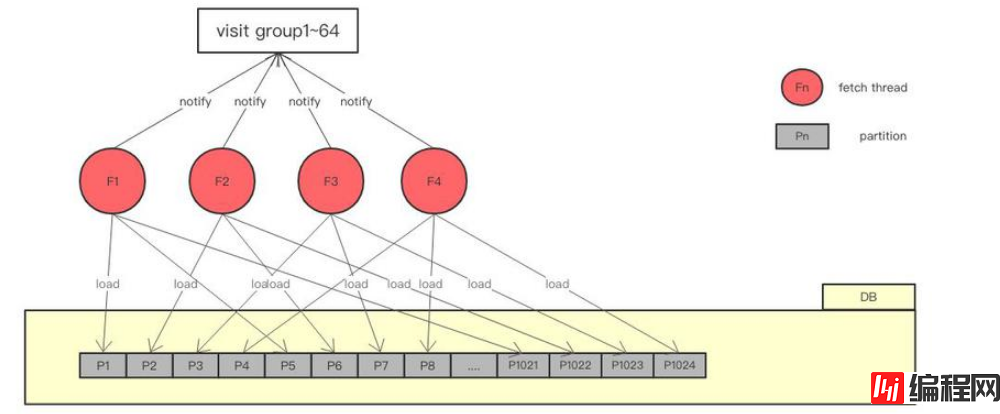
大体来看,便是 4 个 fetch 线程负责读盘,fetch thread n 负责 partitionNo%4==n 编号的分区,完成后通知 visit 消费。这中间充斥着比较多的互斥等待逻辑,并未在图中体现出来,大体如下:
fetch thread 1~4 加载磁盘数据进入缓存是并发的
visit group 1~64 访问同一个 buffer 是并发的
visit group 1~64 访问不同 partition 对应的 buffer 是按照次序来进行的(打到全局有序)
加载 partitonN 会阻塞 visit bufferN,visit bufferN 会阻塞加载 partitionN+4(相当于复用4块缓存)
大块的加载读进缓存,最大程度复用,是 ReadSeq 部分的关键。顺序读两轮的成绩在 196~198s 左右,相比 C++ 又慢了 4s 左右。
这儿是个分水岭,介绍完了整体架构和四个阶段的细节实现,下面就是介绍下具体的优化点了。
由于这次比赛将 drop cache 的时间算进了测评程序之中,所以在不必要的地方应当尽量避免 pageCache,也就是说除了写索引之外,其他阶段不应该出现 pageCache。这对于 Java 选手来说可能是不小的障碍,因为 Java 原生没有提供 Direct IO,需要自己封装一套 JNA 接口,封装这套接口借鉴了开源框架 jaydio 的思路,感谢@尘央的协助,大家可以在文末的代码中看到实现细节。这一点可以说是拦住了一大票 Java 选手。
Direct IO 需要注意的两个细节:
分配的内存需要对齐,对应 jna 方法:posix_memalign
写入的数据需要对齐通常是 pageSize 的整数倍,实际使用了 pread 的 O_DIRECT
这一点在《文件IO操作的一些最佳实践》中有所提及,堆外内存的两大好处是减少了一份内存拷贝,并且对 GC 友好,在 Direct IO 的实现中,应该配备一套堆外内存的接口,才能发挥出最大的功效。尤其在 Range 阶段,一个缓存区的大小便对应一个 partition 数据分区的大小:256M,大块的内存,更加适合用 DirectByteBuffer 装载。
-server -Xms2560m -Xmx2560m -XX:MaxDirectMemorySize=1024m -XX:NewRatio=4 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:-UseBiasedLocking众所周知 newRatio 控制的是 young 区和 old 区大小的比例,官方推荐参数为 -XX:NewRatio=1,很多不注意的 Java 选手可能没有意识去修改它,会在无形中被 gc 拖累。经过和@阿杜的讨论,最终得出的结论:
young 区过大,对象在年轻代待得太久,多次拷贝
old 区过小,会频繁触发 old 区的 cms gc
在比赛中这显得尤为重要, -XX:NewRatio=4 放大老年代可以有效的减少 cms gc 的次数,将 126 次 cms gc,下降到最终的 5 次。
无论是 apache 的 ObjectPool 还是 Netty 中的 Recycler,还是 RingBuffer 中预先分配的对象,都在传达一种思想,对于那些反复需要 new 出来的东西,都可以池化,分配内存再回收,这也是一笔不小的开销。在此次比赛的场景下,没必要大费周章地动用对象池,直接一个 ThreadLocal 即可搞定,事实上我对 key/value 的写入和读取都进行了 ThreadLocal 的缓存,做到了永远不再循环中分配对象。
无论是网络 IO 还是磁盘 IO,io worker 线程的时间片都显得尤为的可贵,在我的架构中,range 阶段主要分为了两类线程:64 个 visit 线程并发随机读内存,4 个 io 线程并发读磁盘。木桶效应,我们很容易定位到瓶颈在于 4 个 io 线程,在 wait/notify 的模型中,为了尽可能的减少 io 线程的时间片流失,可以考虑使用 while(true) 进行轮询,而 visit 线程则可以 sleep(1us) 避免 cpu 空转带来的整体性能下降,由于评测机拥有 64 core,所以这样的分配算是较为合理的,为此我实现了一个简单粗暴的信号量。
public class LoopQuerySemaphore {
private volatile boolean permit;
public LoopQuerySemaphore(boolean permit) {
this.permit = permit;
}
// for 64 visit thread
public void acquire() throws InterruptedException {
while (!permit) {
Thread.sleep(0,1);
}
permit = false;
}
// for 4 fetch thread
public void acquireNoSleep() throws InterruptedException {
while (!permit) {
}
permit = false;
}
public void release() {
permit = true;
}
}
正确的在 IO 中 acquireNoSleep,在 Visit 中 acquire,可以让成绩相比使用普通的阻塞 Semaphore 提升 6s 左右。
线上机器的抖动在所难免,避免 IO 线程的切换也并不仅仅能够用依靠 while(true) 的轮询,一个 CPU 级别的优化便是腾出 4 个核心专门给 IO 线程使用,完全地避免 IO 线程的时间片争用。在 Java 中这也不难实现,依赖万能的 GitHub,我们可以轻松地实现 Affinity。
使用方式:
try (final AffinityLock al2 = AffinityLock.acquireLock()) { // do fetch ...}这个方式可以让你的代码快 1~2 s,并且保持测评的稳定性。
感谢各位的阅读,以上就是“PolarDB数据库性能实例分析”的内容了,经过本文的学习后,相信大家对PolarDB数据库性能实例分析这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: PolarDB数据库性能实例分析
本文链接: https://www.lsjlt.com/news/70878.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-21
2024-05-16
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0