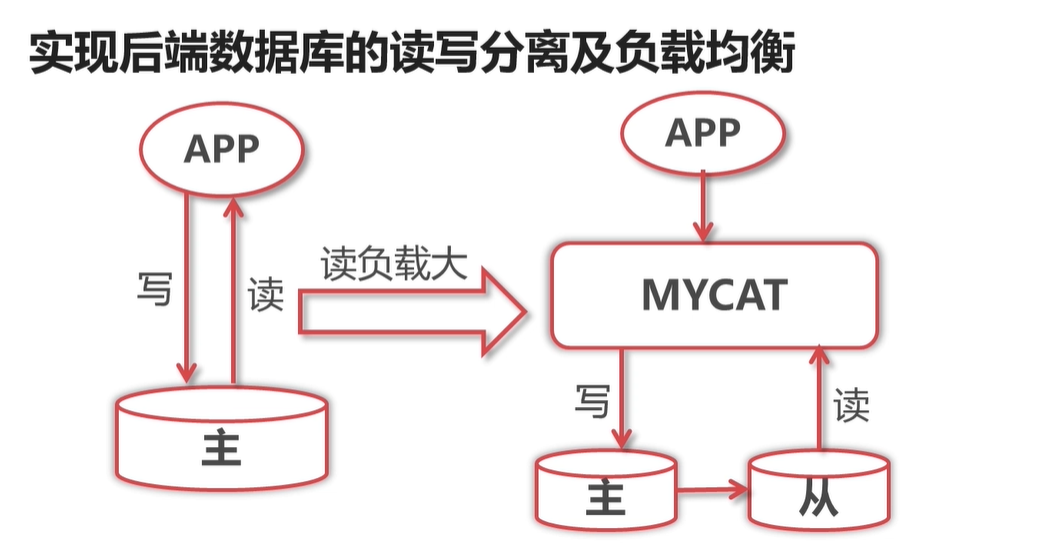
mycat 基础 mycat 作用 当 Mysql 为 1主一从的时候,mycat 支持写DB高可用,即当主挂了,那么可以写入从数据库中 将数据库看出一个蛋糕: 垂直切分,类似 上下切,水

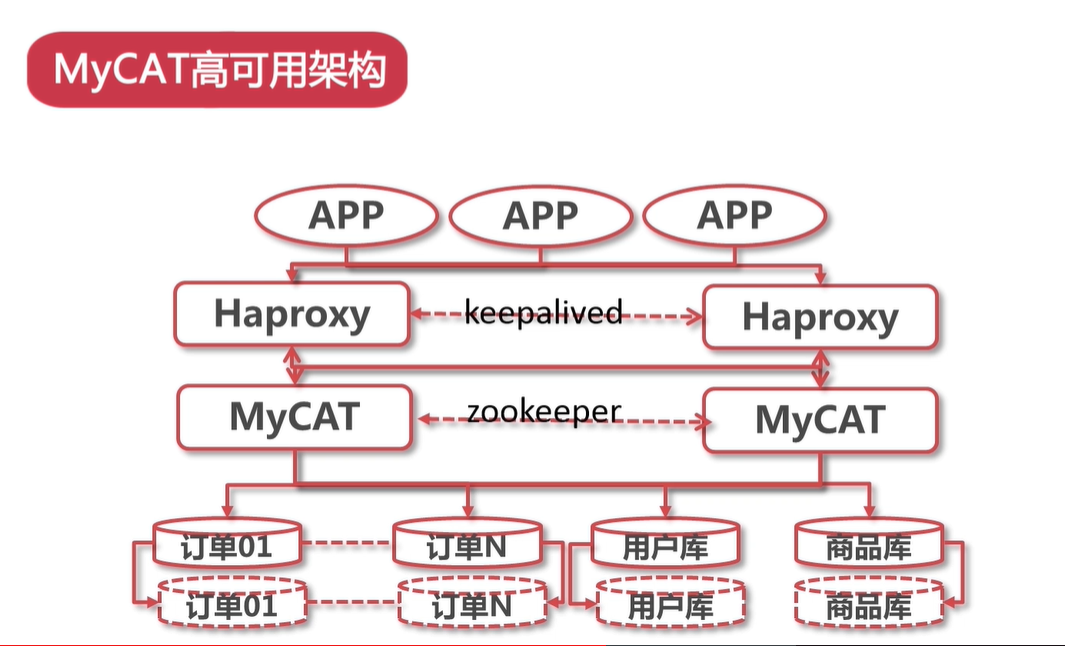




当 Mysql 为 1主一从的时候,mycat 支持写DB高可用,即当主挂了,那么可以写入从数据库中

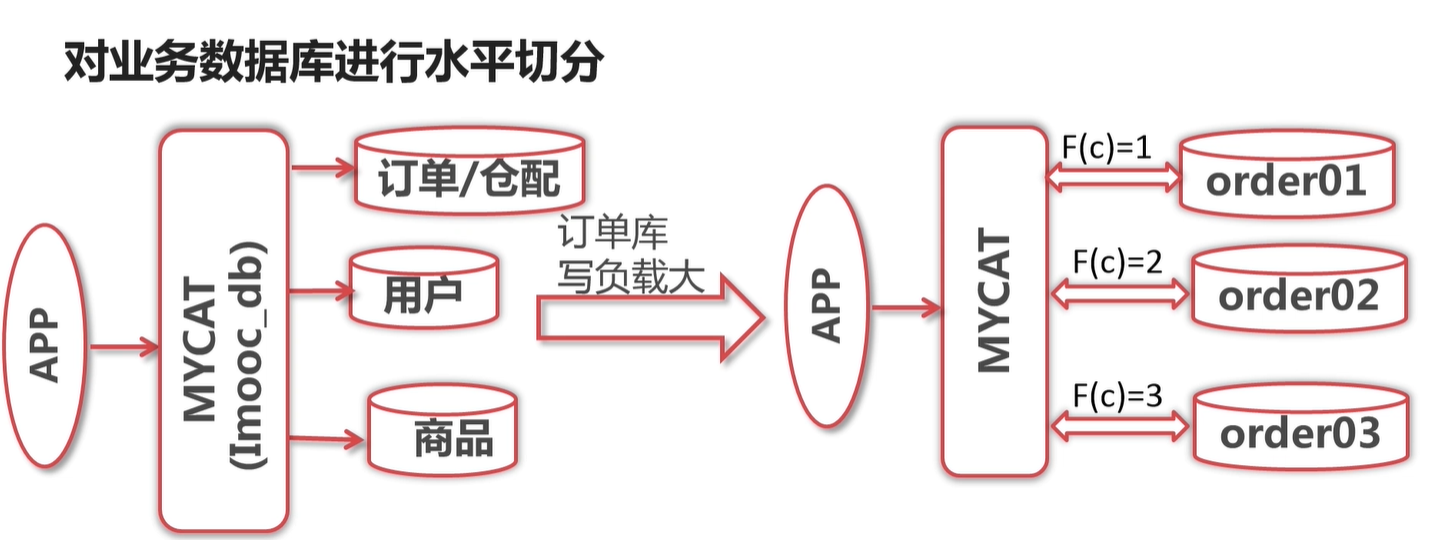
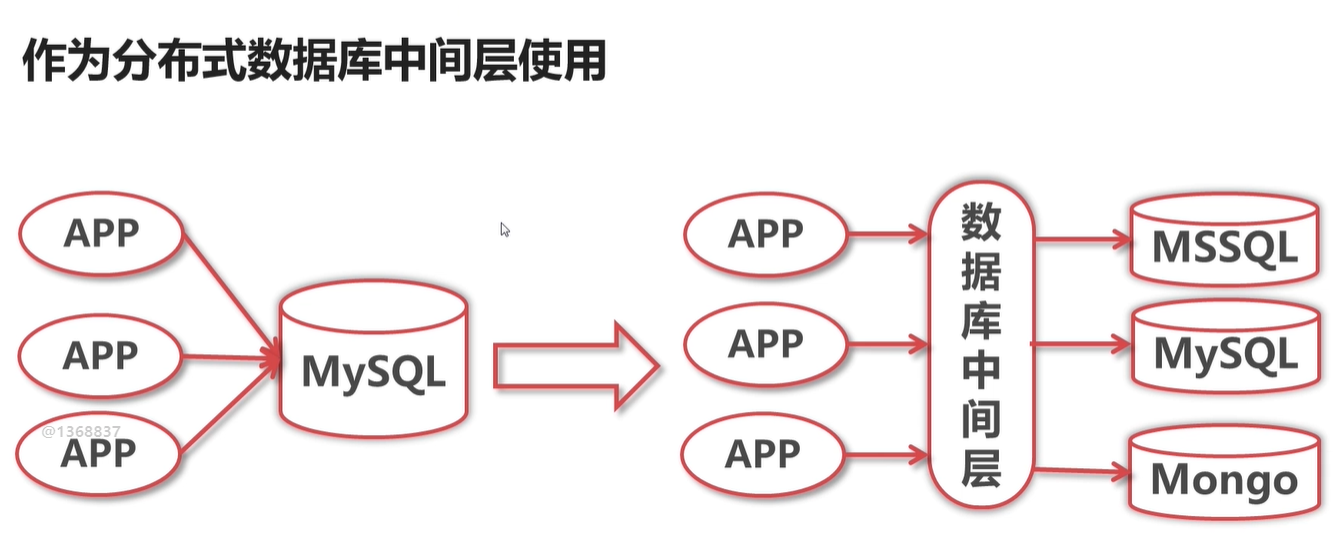
将数据库看出一个蛋糕: 垂直切分,类似 上下切,水平就是 左右切
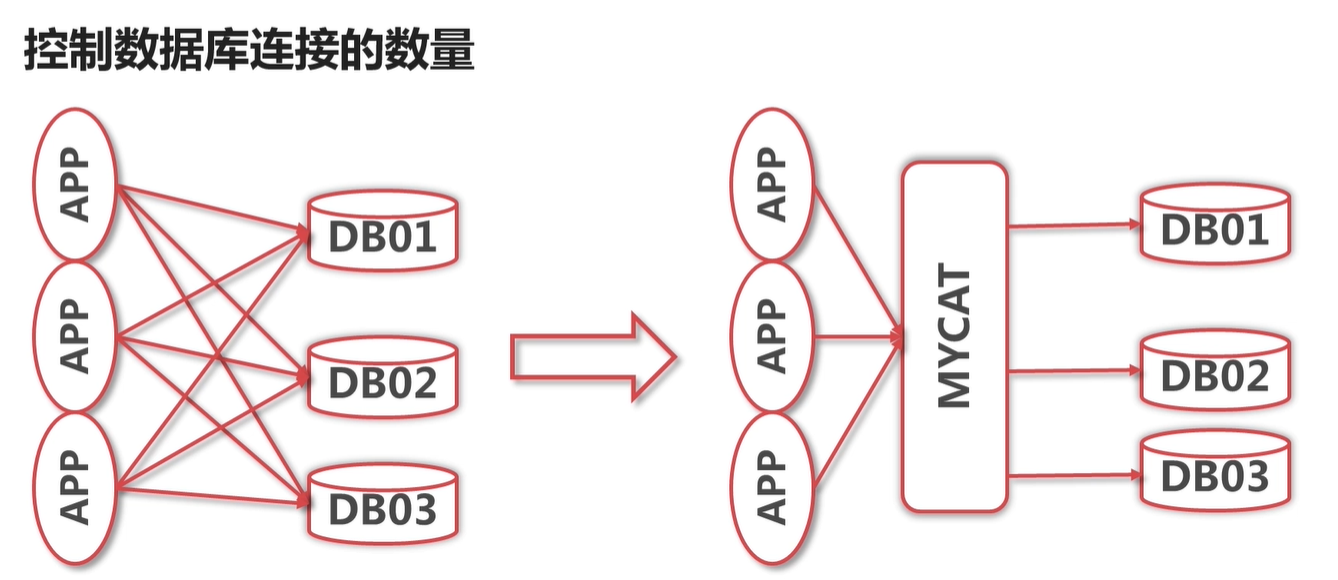
每个数据库库连接数是有限的,如果连接满了之后,那么后续的连接就连接不上了。用了mycat 之后,mycat 有一个 总的连接池,
可以很好的控制连接数量,让应用更加的稳定。

ER关系表就是 mycat 特有的表 。 即用于 将 主表与 子表的 有关联的数据都 存在同一个库里面,比如 订单表与订单明细表
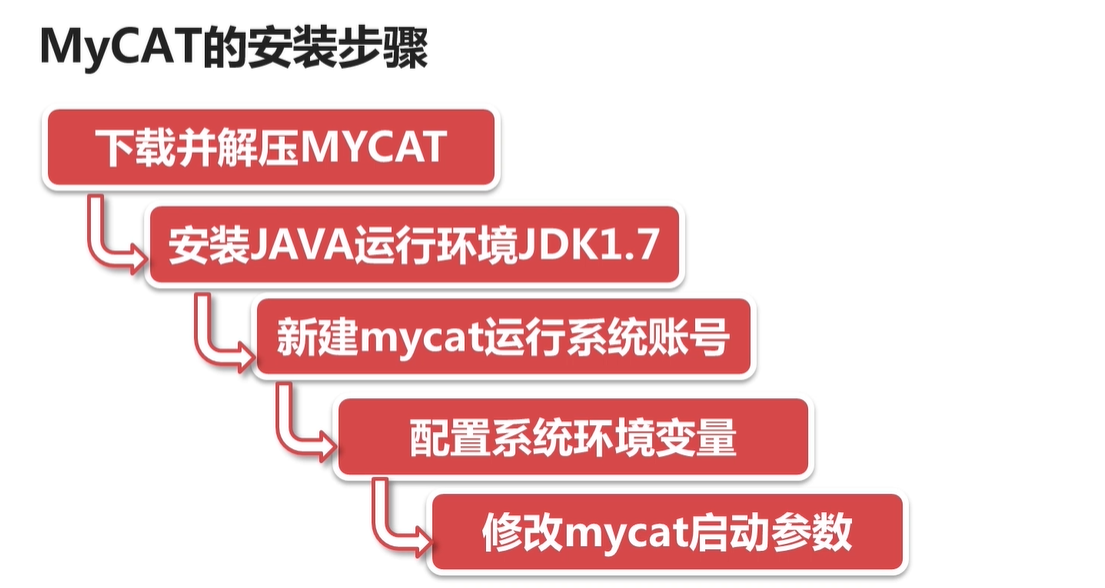
Http://www.mycat.org.cn/
http://dl.mycat.org.cn/1.6.5/Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
下载解压之后, 启动之前可以在 conf 下面进行配置vi wrapper.conf 比如配置内存大小等
wrapper.java.additional.5=-XX:MaxDirectMemorySize=800M

还有就是配置环境变量 如上图
启动: mycat start
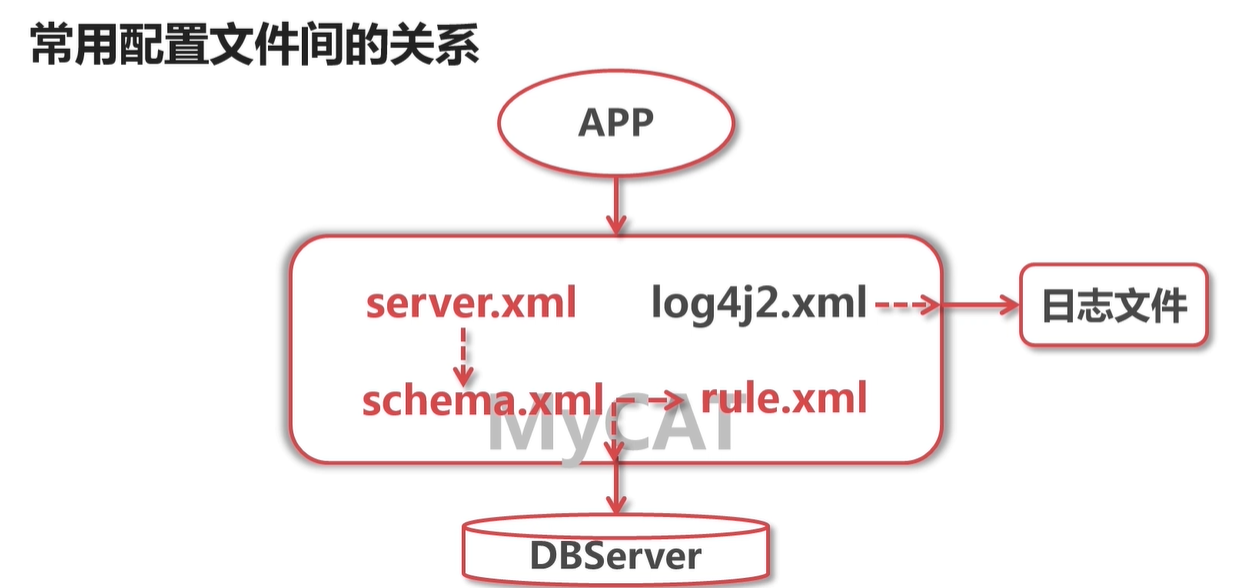



即 配置访问真实数据库的用户名密码等的配置
同一个用户配置多个数据库, 在 schemas 配置多个即可:

授予用户某些表的访问权限:

dml 的值 有1 就是对应的有权限,否则就是没有权限

执行加密,将加密串放入配置文件的密码里面即可。这样密码就不显示明文密码了 。
0 表示通过mycat 访问的都加密,即 前端加密。 如下配置:







property 就是对应分片算法的执行的 参数


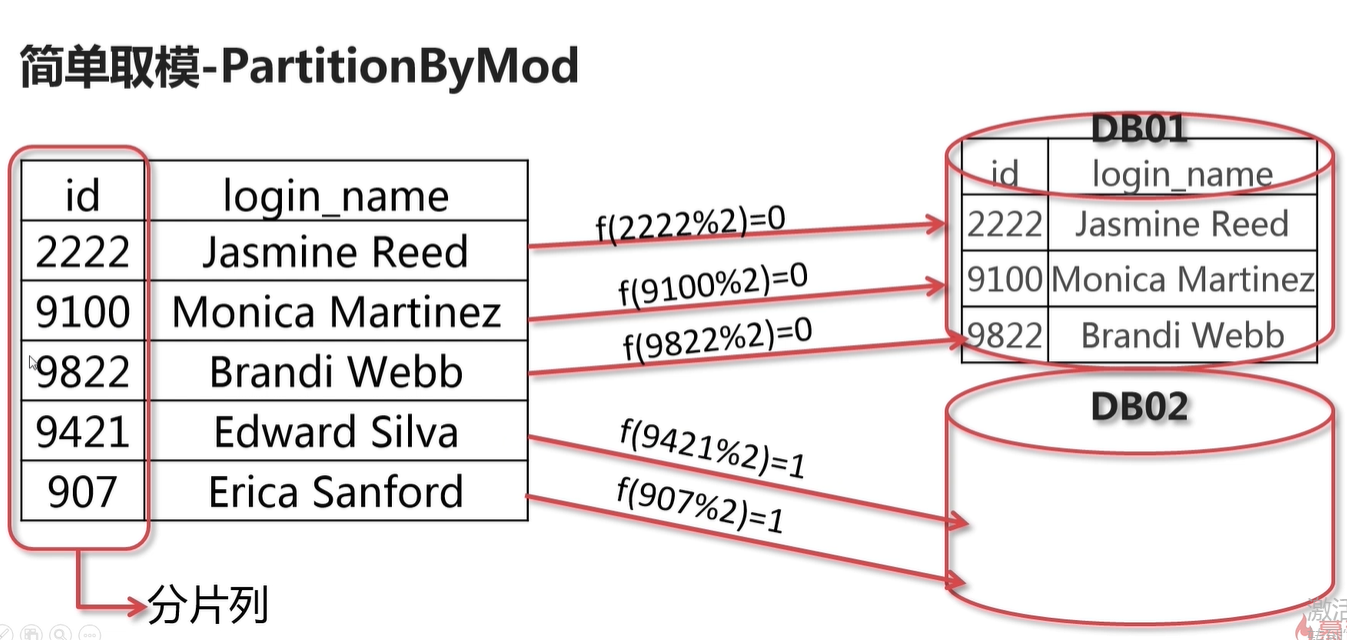



即某些列的值不少整数,因此转为 正数 这样就是 简单的取模算法一样了



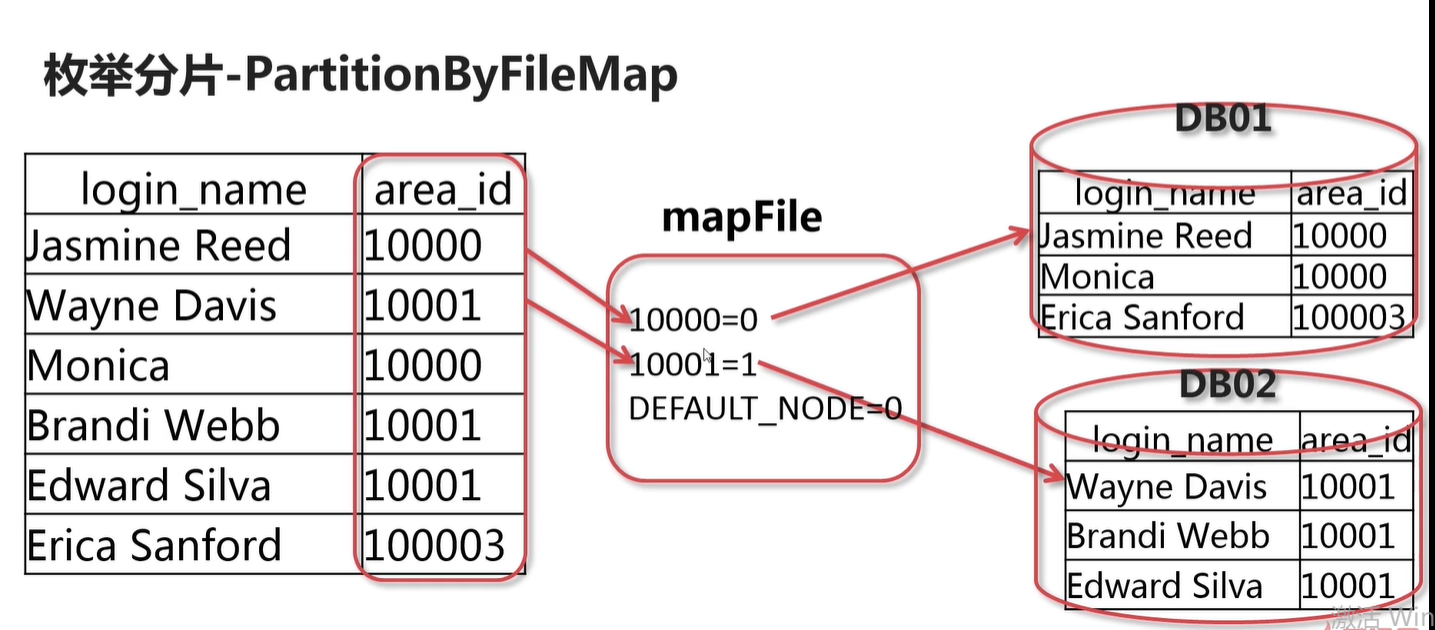
比如:可以用于 按地区 存入不同数据库中

partition-hash-int.txt 位于 conf 目录里面 。数据库索引从0开始




即取 字母的 阿斯特码的值来进行计算的
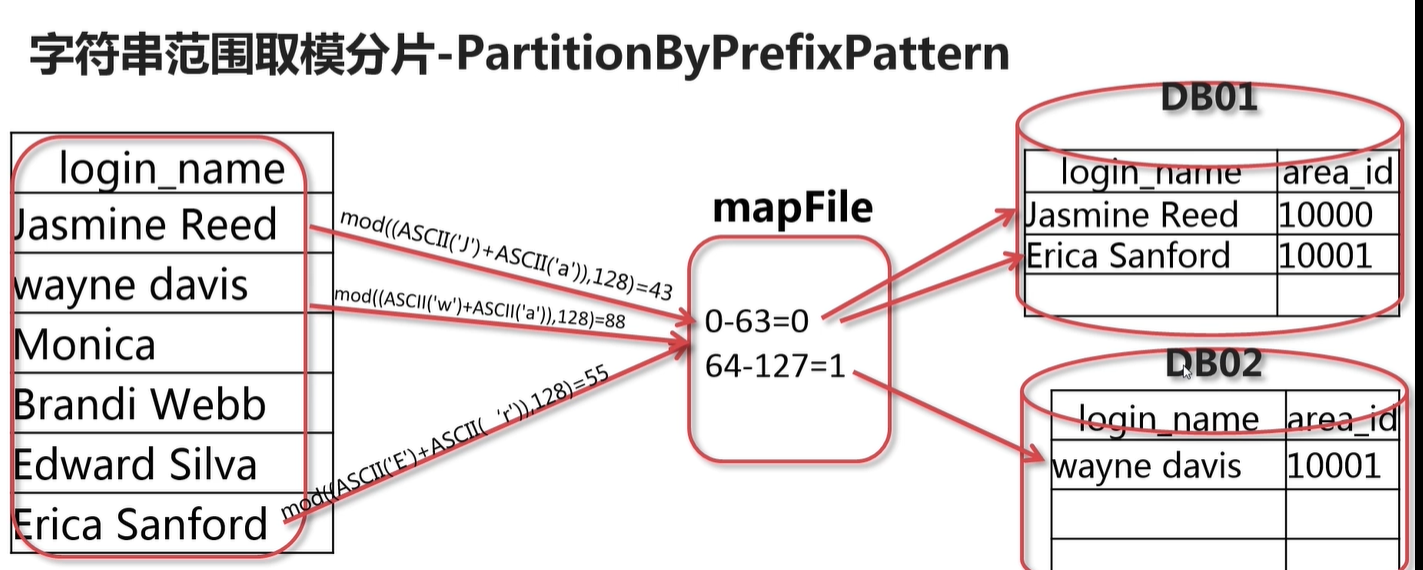

patternValue 取模基数



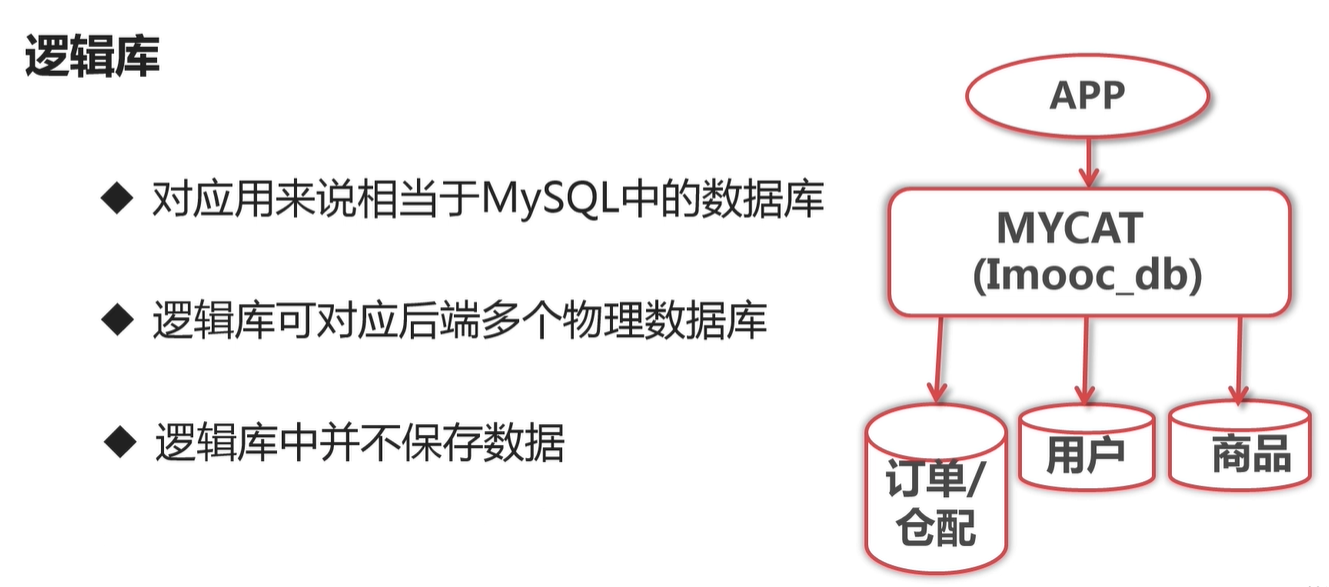
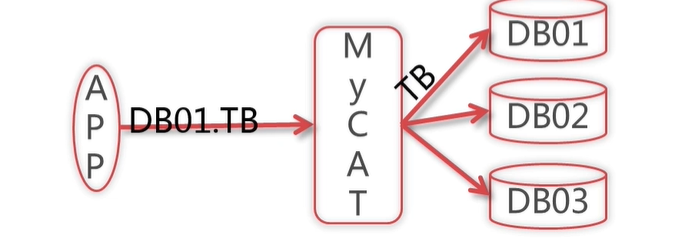
一个逻辑库 可能 对应 多个真实的物理数据库,可以看作为其视图

即如果查询的sql 没有 加上 limit ,那么mycat 会自动加上 limit 来限制返回的行数

mycat 是推荐 checkSQLschema 设置为true的,即mycat 不支持 跨多个 数据库 查询的。比如 select db01.cat, db02.cat
即 可能 库名加上 表名方式查询 可能会报错的 .如果 checkSQLschema=true 那么mycat 会自动将 sql 中带上 库名+表名的 方式 给去调 库名

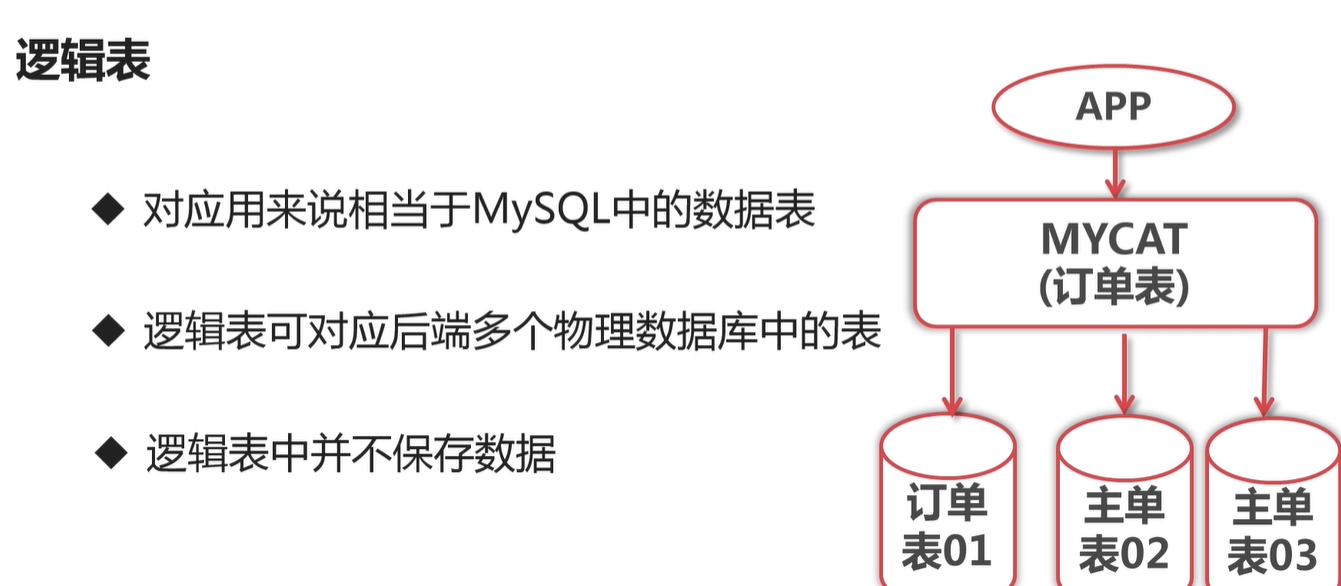
逻辑表的主键 就是对应数据库表的主键名

datanode 多个 以逗号分隔,索引从 0开始, 一旦配置好之后,就不要进行修改了,否则 容易产生数据混乱




dataHost 就是一组的 数据库集群


stand by writeHost 即双主 数据库(比如 互为主从) 这种情况
switchType 开可用 配置 ,1 当数据库某个挂了,自动切换 。 -1 就不自动切换
writeType 写操作类型 : 0,1 。 当是0 就是 所有写请求由第一个 writeHost 来执行,除非第一个挂了,才会切换到其他可以写的 主机上。 1就是随机发生写请求到writeHost . 一般设置为0 ,除非是支持多写的数据库集群类型
心跳检查的语句 。

writehost 一般是 主, readHost 一般是从


这里还不支持加密的密码
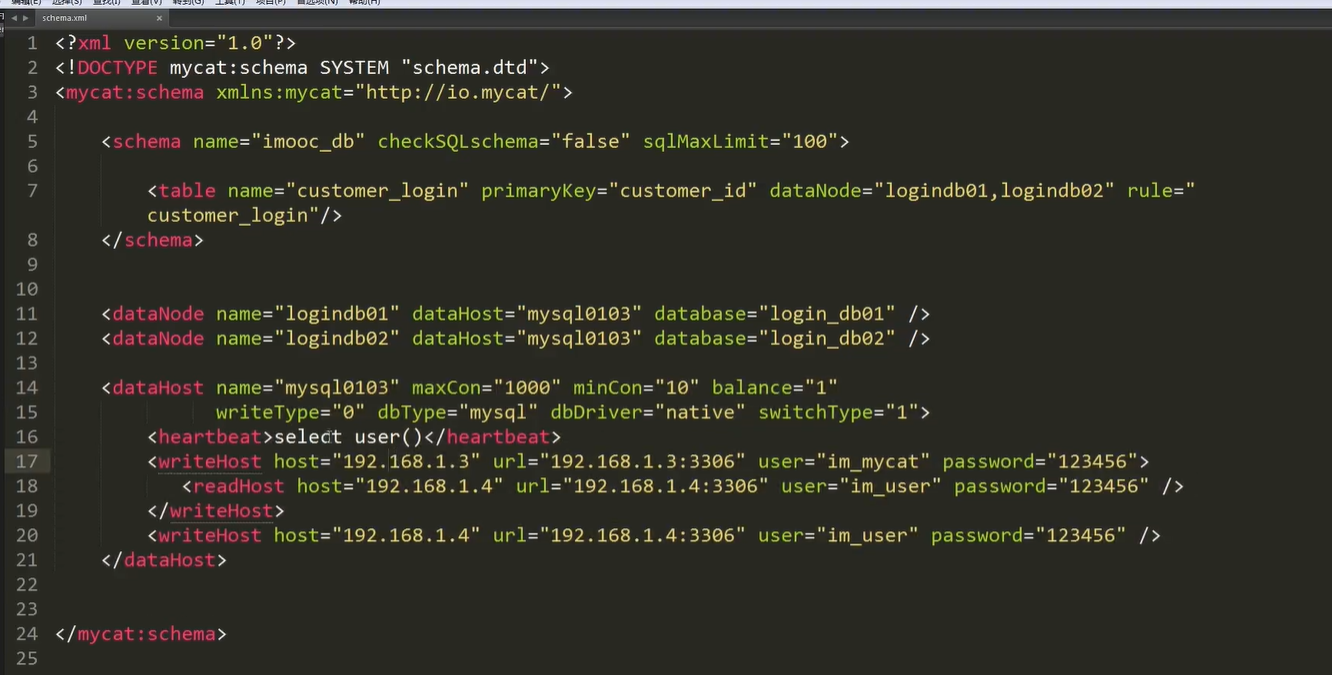
在 dataHost 中,1.3 与1.4 是主从关系, 当 1.3 挂了,那么1.4 就可以处理读写请求了 。否则 1.3 负责写请求,1.4 负责读请求
一般是先垂直分库,后续数据量还是太大就进行水平 分库

一般是 写负载大,才有必要进行垂直分库的


备份

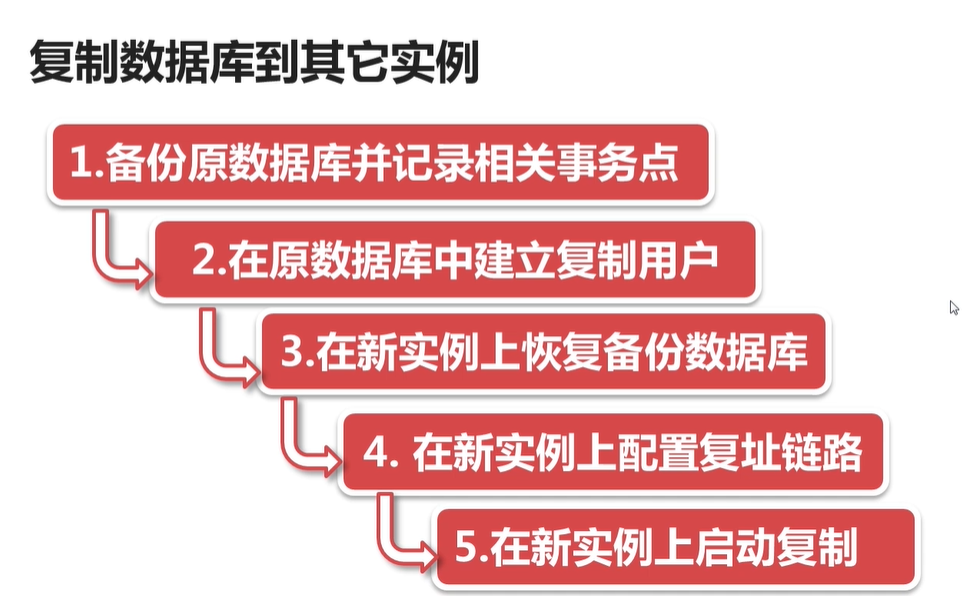
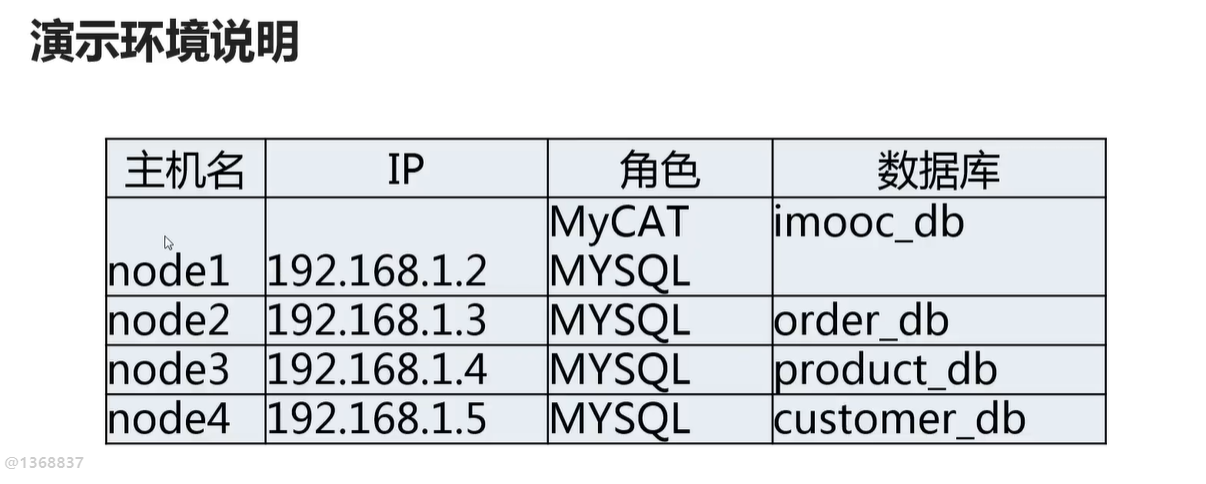
将备份的数据库SQL 在新的 数据库里面比如 order_db 里面 执行。
接着 在原数据库 建立主从同步账号,同步数据到 新的order_db 里面 。 这样可以切换的更快,而不让数据库停止服务太久

接着 在 新的数据库比如 order_db 里面,建立 同步数据传输链路

-- CHANGE MASTER TO MASTER_LOG_FILE="mysql-bin.000001", MASTER_LOG_POS=4532519;
可以在 之前的原数据库的备份sql文件 可以找到
因为 原来的数据库名是 imooc_db 与 新的order_db 名称不一样,要主从同步数据,还得建立 主从复制过滤,

接着启动复制链路


master-data 就是 备份对应 事务级别的数据

schema :
select user()
select user()
select user()
server:
0
1
0
0
2
false
0
0
1
64k
1k
0
384m
8066
9066
300000
0.0.0.0
utf8
123456
imooc_db
启动mycat ,然后就可以 通过 mysql 客户端连接mycat 进行测试查询了
https://blog.csdn.net/qq_35890572/article/details/81162110

但是垂直分库的查询, 是不支持 跨库 多表查询的 。
那么如果要跨库 多表查询,要么就 把表都搞到同一个库里面,
要么 就 配置全局表(比如 字典表,及全局表都存在所有的 数据库里面,mycat 会进行维护的,采用多写方式保证每个库的全局表数据一致) 。

当 配置并启动了 使用了mycat 之后,就得停止 主从同步了
在 order db , product db ,coustomer db 的数据库中,删除 其他不相关的表,比如 order db删除 用户表。
全局表适合于小表,如果是大表,那么维护麻烦,且查询性能也不会高
在 schema.xml 中 配置 region_info 作为全局表 比如
也就是 region_info 表需要在所有的分库里面
UPDATE region_info set region_name="中华" where region_id=1;
经过使用mycat 更新全局表发现 每个 分库的表都更新了,即mycat 维护了全局表




水平切分,一般是 对某个表或者某些相关的表 进行水平切分就解决问题了 。 很少表才需要切分而已(一般是大表,且读写非常频繁的) 。
(某些表数据很大,可以将其数据放入历史表中进行归档即可,就不用水平切分了)
水平切分比垂直切分复杂多了




很少用订单id 去查询订单信息,因此不作为分配键


rule.xml
customer_id
mod-long
2
server.xml
0
1
0
0
2
false
0
0
1
64k
1k
0
384m
8066
9066
300000
0.0.0.0
utf8
123456
imooc_db
schema.xml :
select user()
select user()
select user()
比如订单表分表之后,由于订单id是自增的,因此有id 重复的数据,因此可以采用mycat 的全局自增id 去避免
在server.xml 中
1 这里以数据库的方式来使用
在 mycat 的conf 下面有 dbseq.sql 就是用到 自增功能的建表语句,执行它 。mycat_sequence 就是用到的辅助表
在 schema.xml 中配置 辅助表用到逻辑库
select user()
接着 在conf 下修改 vi sequence_db_conf.properties
#sequence stored in datanode
# 注意 key 使用大写字母
GLOBAL=mycat
ORDER_MASTER=mycat接着在 自增用到的数据库里面 增加一条记录 , name 对应配置文件的key
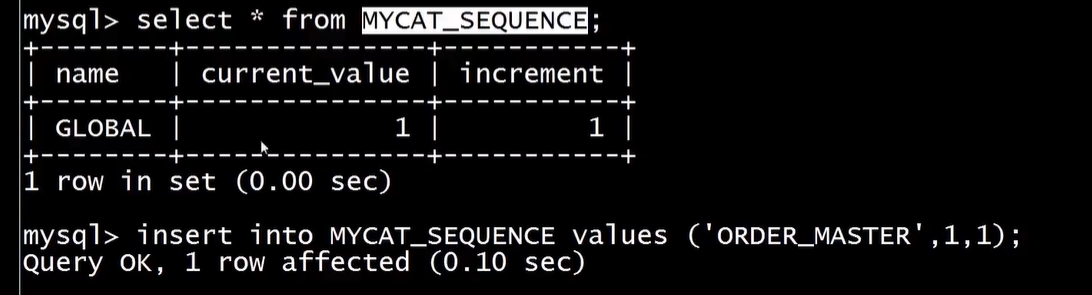
这样自增就取name = ORDER_MASTER 的 这条记录开始了
在 schema.xml 中配置 用到全局自增id的表 autoIncrement="true"
插入订单表数据的时候, order_id 就生效了全局id 了

分片之后,联合查询 不行,因此 得配置 订单的 明细表 order_detail 的ER分片关系才行。即对 order_detail 也得配置分片
在schema.xml 中
当然 order_detail 配置的全局自增方式与 order_master 一样重启之后,测试,就发现 保存 订单明细的时候,会根据 订单id 存入对应的分片库里面,即和 订单表所在的数据存在一起




上图中, 白名单里面的意思就是 规定root 用户只能在 当前机器登录,其他机器不用使用root 登录

一台机器部署多实例mycat : https://blog.csdn.net/tqs314/article/details/102407043

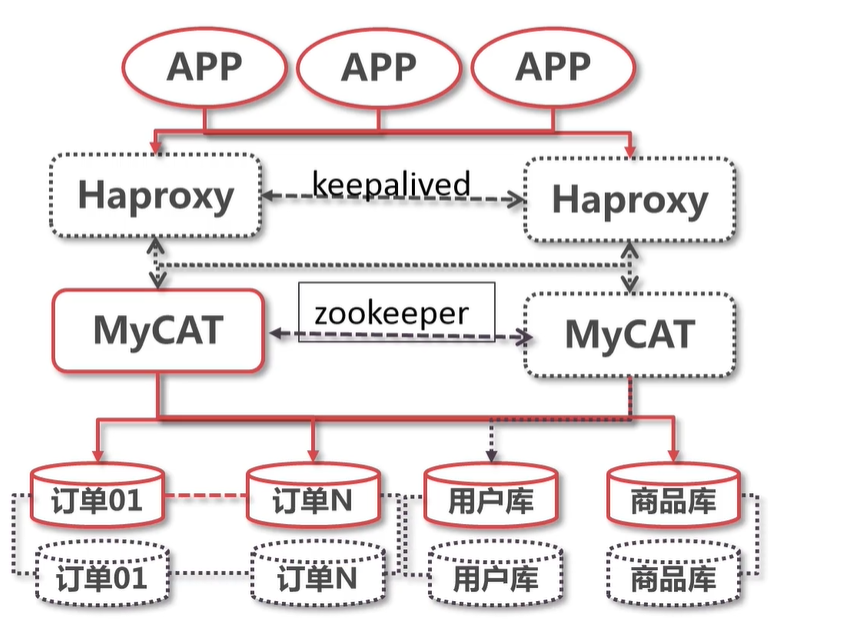



先将之前配置好的mycat 内容 覆盖到 mycat的zkconf 配置内容
在mycat 的bin 下 执行初始化 zk 的数据
./init_zk_data.sh
可以去ZooKeeper查看 是否成功 将信息给加载到了zk

接着在 每台mycat 里面conf配置 myid.properties
loadZk=true # 这样其他mycat 就可以加载zk 上面的配置信息并启动了
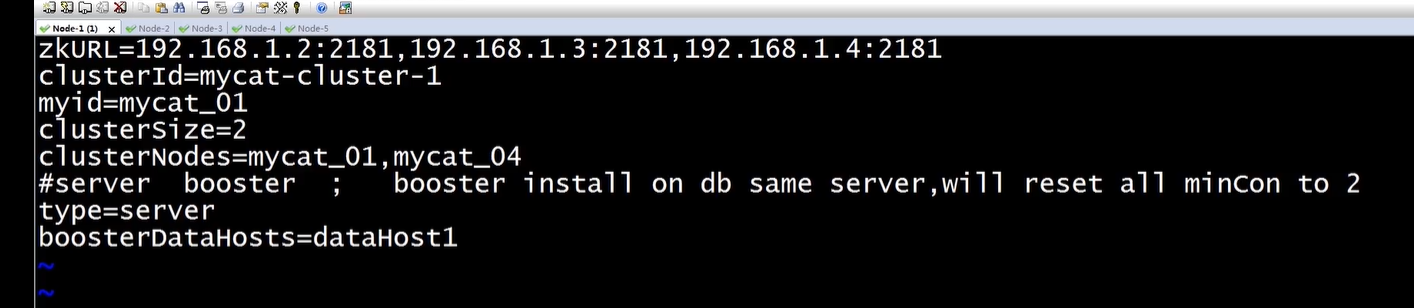
启动全部zk 和mycat
haproxy 与 Nginx 区别
https://www.cnblogs.com/EasonJim/p/7629888.html
https://blog.csdn.net/hellojoy/article/details/80805328
https://www.yht7.com/wenda/detail/456168
https://zhuanlan.zhihu.com/p/115092359


Haproxy 与 Keepalived 一定要部署和mycat 在同一台服务器上。
即 通过keepatlive 提高 的虚假IP 给 前端用户去访问
https://blog.csdn.net/xianglinGChuan/article/details/82218469
https://zhuanlan.zhihu.com/p/23893787

手动安装:
https://jingyan.baidu.com/article/4dc408486bb9e7c8d946f12b.html
https://blog.csdn.net/qq_28710983/article/details/82194404
https://blog.csdn.net/keil_wang/article/details/89712380
https://www.jianshu.com/p/edf2c8c7d83f
开启打印日志 https://www.cnblogs.com/liuxia912/p/11078172.html

上图就是 haproxy 配置的mycat 的负载均衡
haproxy.cfg 完整:
global
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats Socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option abortonclose
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
balance roundrobin
log 127.0.0.1 local0 info
listen admin_status
bind *:48800 ##VIP
stats uri /admin-status ##统计页面
stats auth admin:admin
listen allmycat_service
bind *:8096 ##转发到mycat的应用端口,即mycat的服务端口
mode tcp
option tcplog
balance roundrobin
server mycat_132 10.102.13.2:3306 check port 48700 inter 5s rise 2 fall 3
server mycat_135 10.102.13.5:8066 check port 48700 inter 5s rise 2 fall 3
listen allmycat_admin
bind *:8097 ##转发到mycat的管理端口,及mycat的管理控制台端口
mode tcp
option tcplog
balance roundrobin
server mycat_132 10.102.13.2:9066 check port 48700 inter 5s rise 2 fall 3
server mycat_135 10.102.13.5:9066 check port 48700 inter 5s rise 2 fall 3
这里有一个 检查端口 48700 , 因此安装 yum -y install xinetd
[root@node1 haproxy]# yum install xinetd -y
[root@node1 log]# vi /etc/xinetd.d/mycatchk
service mycatchk
{
flags = REUSE
socket_type = stream
port = 48700
wait = no
user = root
server =/usr/local/bin/mycat_status
log_on_failure += USERID
disable = no
}
###########################################
#增加/usr/local/bin/mycat_status脚本
#########################################
#!/bin/bash
#/usr/local/bin/mycat_status
# This script checks if a mycat server is healthy running on localhost. It will
# return:
#
# "HTTP/1.x 200 OK" (if mycat is running smoothly)
#
# "HTTP/1.x 503 Internal Server Error" (else)
mycat=`/usr/local/mycat/bin/mycat status |grep "not running"| wc -l`
if [ "$mycat" = "0" ];
then
/bin/echo -en "HTTP/1.1 200 OK
"
/bin/echo -en "Content-Type: text/plain
"
/bin/echo -en "Connection: close
"
/bin/echo -en "Content-Length: 40
"
/bin/echo -en "
"
/bin/echo -en "MyCAT Cluster Node is synced.
"
exit 0
else
/bin/echo -en "HTTP/1.1 503 Service Unavailable
"
/bin/echo -en "Content-Type: text/plain
"
/bin/echo -en "Connection: close
"
/bin/echo -en "Content-Length: 44
"
/bin/echo -en "
"
/bin/echo -en "MyCAT Cluster Node is not synced.
"
exit 1
fi
#########################################################
#在/etc/services中加入mycat_status服务
######################################################
[root@node1 bin]# vi /etc/services
mycatchk 48700/tcp # mycat check
#重启xinetd服务
Centos6:[root@node1 bin]# service xinetd restart
centos7:[root@node1 bin]# systemctl restart xinetd
#验证mycatchk服务是否启动成功
[root@node1 bin]# netstat -nltp | grep 48700
#在node1节点绑定VIP
[root@node1 bin]# ifconfig eth0:1 10.102.13.248/24
#启动haproxy
[root@node1 xinetd.d]# haproxy -f /etc/haproxy/haproxy.cfg
#测试通过haproxy连接MyCAT
[root@node3 ~]# mysql -uroot -p -h10.102.13.248 -P8096 https://blog.csdn.net/lzghxjt/article/details/83018710
其实这里不用 xinetd 也是可以的,开发测试而已 . 生产环境一般都是使用 xinetd的
MyCat服务主机(edu-mycat-01、edu-mycat-02)上需要增加mycat服务的状态检测脚本,并开放相应的检测端口,以提供给HAProxy对MyCat的服务状态进行检测判断。可以使用xinetd来实现,通过xinetd,HAProxy可以用httpchk来检测MyCat的存活状态。(xinetd即extended internet daemon,xinetd是新一代的网络守护进程服务程序,又叫超级Internet服务器。经常用来管理多种轻量级Internet服务。xinetd提供类似于inetd+tcp_wrapper的功能,但是更加强大和安全。xinetd为linux系统的基础服务)
如果不配置使用xinetd 那么 配置haproxy 的配置代理需要配置 其他的时间参数,否则会代理失败: 比如 timeout 等相关的参数。
listen mycat # 监控配置
bind 0.0.0.0:8096 #监听端口 , 虚IP, 访问mycat
mode tcp
option tcplog
timeout connect 60s #连接超时
timeout client 30000 #客户端超时,
timeout server 30000
balance roundrobin
server mycat_fz_01 192.168.0.205:8066 check inter 5s rise 2 fall 3 weight 1
server mycat_fz_011 192.168.0.205:8066 check inter 5s rise 2 fall 3 weight 1
接着配置虚IP
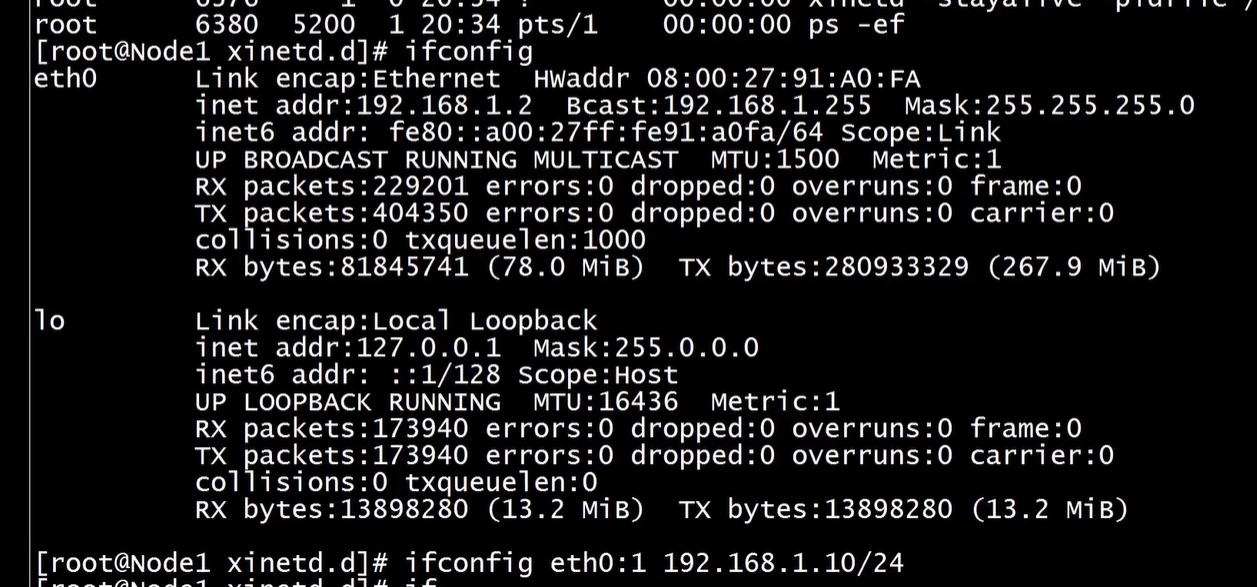
之后就可以重启haproxy 了
其实可以不用配置虚拟IP的, 都配置成 0.0.0.0
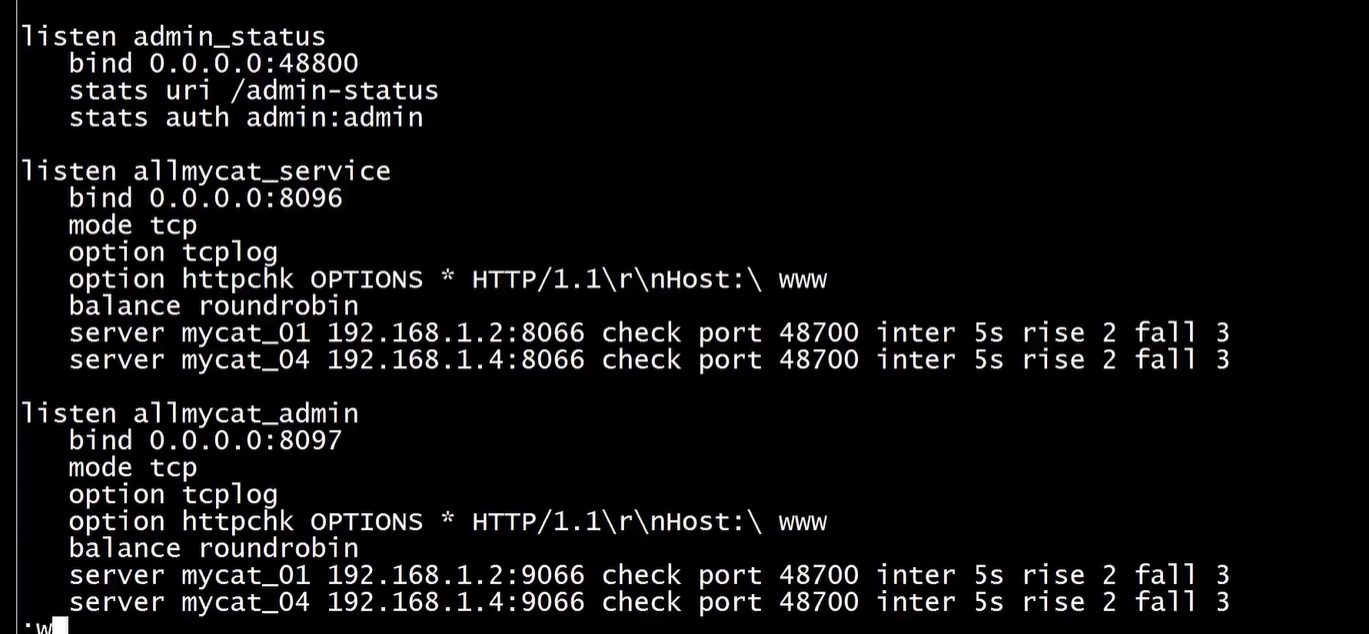
用于 haproxy 的 高可用,即 使用虚IP来访问某一台 haproxy
yum -y install keepalived
配置文件目录 cd /etc/keepalived/
keepalived.conf配置内容:
! Configuration Fileforkeepalived
vrrp_script chk_http_port {
script"/etc/keepalived/check_haproxy.sh" # haproxy 的监控建表
interval 2 # 时间间隔
weight 2
}
vrrp_instance VI_1 {
state MASTER # 这里是master ,另一台服务器的 keepalived 是 slave ,主从配置
interface eth0 # 虚IP网卡
virtual_router_id 51 # 两台的 keepalived id 值必须一致
priority 150 # 优先级, master 的优先级 比较高,值越大 越会优先使用作为master keepalived
advert_int 1
authentication {
auth_type PASS # keepalived 认证方式与密码
auth_pass 1111
}
track_script {
chk_http_port
}
virtual_ipaddress {
192.168.0.105 dev eth0 scope global # 虚IP
}
}check_haproxy.sh : 检查haproxy 是否存活,没有启动就启动。如果启动失败或者haproxy 挂了,那么 虚IP就 就执行另一台的服务器的keepalived 与 haproxy
#!/bin/bash
STARTHAPROXY="/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg"
STOPKEEPALIVED="/etc/init.d/keepalived stop"
#STOPKEEPALIVED="/usr/bin/systemctl stop keepalived"
LOGFILE="/var/log/keepalived-haproxy-state.log"
echo "[check_haproxy status]" >> $LOGFILE
A=`ps -C haproxy --no-header |wc -l`
echo "[check_haproxy status]" >> $LOGFILE
date >> $LOGFILE
if [ $A -eq 0 ];then
echo $STARTHAPROXY >> $LOGFILE
$STARTHAPROXY >> $LOGFILE 2>&1
sleep 5
fi
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
exit 0
else
exit 1
fi
chmod a+x check_haproxy.sh 加上执行权限
启动keepalived
通过 ip addr 可以看到 虚IP已生效。 如果某一台挂了,那么虚IP就切换到另一台服务器了。
mysql 是不能频繁切换虚IP的,会产生数据异常。而haproxy 没有问题,因为它的连接是没有状态的。

主要配置 dataHost 即可
select user()
写, 主
读 , 从
当写挂了, 高可用,配置读作为读写
在 mycat的 conf下的 zkConf 修改配置之后, 执行 bin/init_zk_data.sh 就可以将修改的内容同步到zk 了。
这样其他 mycat 集群机器就可以同步配置了,即滚动应用mycat 配置 . 接着 一台一台启动mycat 即可,这样就不影响使用了


可以通过使用navicat 来连接mycat 来对 mycat 进行管理
重新加载配置:

常用于管理单台的mycat

http://dl.mycat.org.cn/mycat-web-1.0/ 下载 web
tar zxf Mycat-web-1.0-SNAPSHOT-20170102153329-linux.tar.gz
mycat-web/mycat-web/WEB-INF/classes 里面 可以 修改 zookeeper的路径
启动 ./start.sh
端口 8082 : http://192.168.0.205:8082/mycat/
这样就可以对mycat 进行 监控和管理了


以上就是一般的基于内存和网络的优化配置,参考

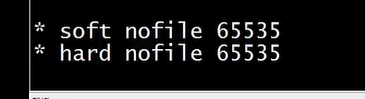
加上 两行即可 ,配置文件的最大打开数量




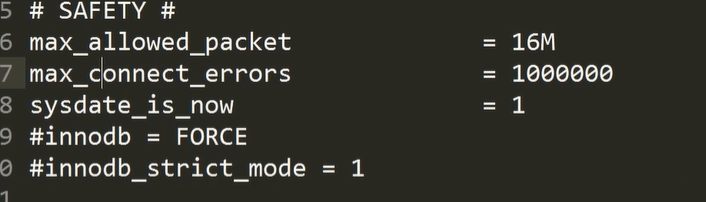
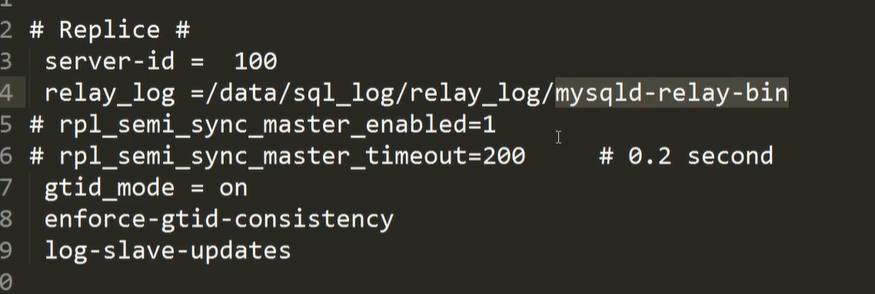
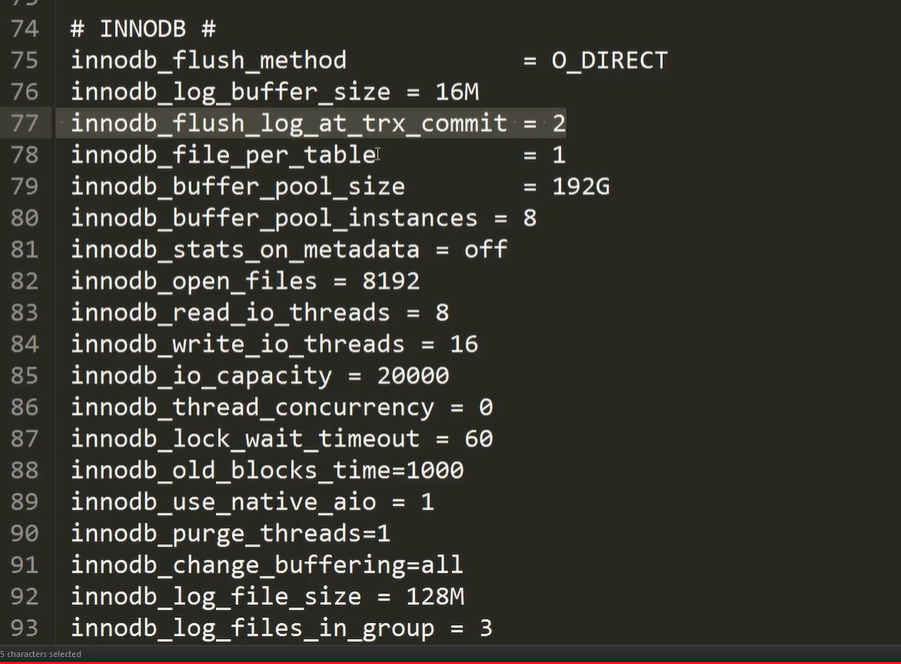
独占机器的mysql 对于 innodb_buffer_pool_size 为内存的 2/3 大小




即 待 update或者delete 带limit的 不支持,否则会出现数据异常
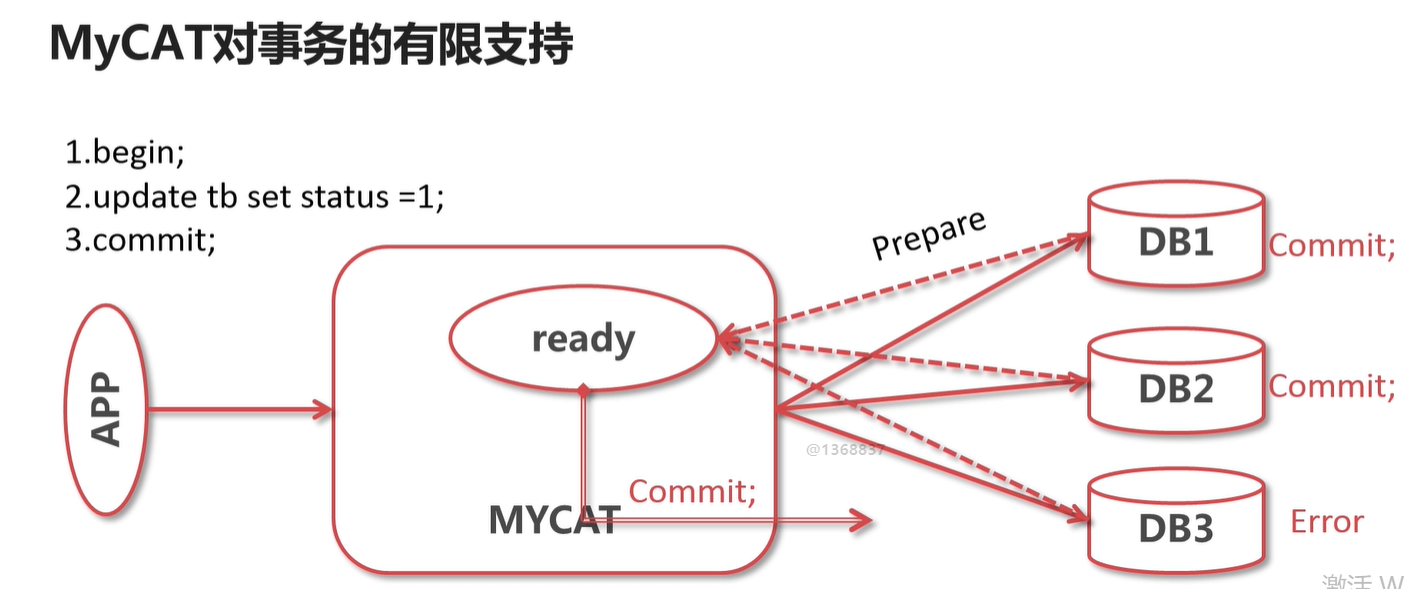

即支持 XA的分布式事务: https://www.cnblogs.com/cxxjohnson/p/9145548.html

--结束END--
本文标题: mycat和mysql搭建高可用企业数据库集群
本文链接: https://www.lsjlt.com/news/7763.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-09
2024-05-09
2024-05-09
2024-05-09
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0