RD:单库数据量太大,数据库扛不住了,我要申请一个数据库从库,读写分离。DBA:数据量多少?RD:5000w左右。DBA:读写吞吐量呢?RD:读QPS约200,写QPS约30左右。 上周在公司听到两个技术同学讨论,感觉对读写分离解决什么问题
![数据库读写分离架构,为什么我不喜欢
[数据库教程]](/upload/202205/01/4adobaar33t.jpg)
上周在公司听到两个技术同学讨论,感觉对读写分离解决什么问题没有弄清楚,有些奔溃。
另,对于互联网某些业务场景,并不是很喜欢数据库读写分离架构,一些浅见见文末。
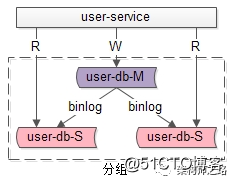
答:一主多从,读写分离,主动同步,是一种常见的数据库架构,一般来说:
答:大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
一句话,分组主要解决“数据库读性能瓶颈”问题,在数据库扛不住读的时候,通常读写分离,通过增加从库线性提升系统读性能。
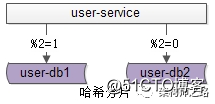
答:水平切分,也是一种常见的数据库架构,一般来说:
答:大部分互联网业务数据量很大,单库容量容易成为瓶颈,如果希望:
一句话总结,水平切分主要解决“数据库数据量大”问题,在数据库容量扛不住的时候,通常水平切分。
对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,如果数据库读写分离:
有潜在的主库从库一致性问题
所以,上述业务场景下,楼主建议使用缓存架构来加强系统读性能,替代数据库主从分离架构。
当然,使用缓存架构的潜在问题:如果缓存挂了,流量全部压到数据库上,数据库会雪崩。不过幸好,云上的缓存一般都提供高可用的服务。
希望这一分钟你有收获。
随手转,谢过。
数据库读写分离架构,为什么我不喜欢
--结束END--
本文标题: 数据库读写分离架构,为什么我不喜欢
本文链接: https://www.lsjlt.com/news/7983.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-04-30
2024-04-30
2024-04-30
2024-04-30
2024-04-30
2024-04-30
2024-04-30
2024-04-30
2024-04-30
2024-04-30
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0