这篇文章主要介绍如何使用Nadam进行梯度下降优化,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!梯度下降是一种优化算法,遵循目标函数的负梯度以定位函数的最小值。梯度下降的局限性在于,
这篇文章主要介绍如何使用Nadam进行梯度下降优化,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
梯度下降是一种优化算法,遵循目标函数的负梯度以定位函数的最小值。
梯度下降的局限性在于,如果梯度变为平坦或大曲率,搜索的进度可能会减慢。可以将动量添加到梯度下降中,该下降合并了一些惯性以进行更新。可以通过合并预计的新位置而非当前位置的梯度(称为Nesterov的加速梯度(NAG)或Nesterov动量)来进一步改善此效果。
梯度下降的另一个限制是,所有输入变量都使用单个步长(学习率)。对梯度下降的扩展,如自适应运动估计(Adam)算法,该算法对每个输入变量使用单独的步长,但可能会导致步长迅速减小到非常小的值。Nesterov加速的自适应矩估计或Nadam是Adam算法的扩展,该算法结合了Nesterov动量,可以使优化算法具有更好的性能。
在本教程中,您将发现如何从头开始使用Nadam进行梯度下降优化。完成本教程后,您将知道:
梯度下降是一种优化算法,它使用目标函数的梯度来导航搜索空间。
纳丹(Nadam)是亚当(Adam)版本的梯度下降的扩展,其中包括了内斯特罗夫的动量。
如何从头开始实现Nadam优化算法并将其应用于目标函数并评估结果。
本教程分为三个部分:他们是:
梯度下降
梯度下降是一种优化算法。它在技术上称为一阶优化算法,因为它明确利用了目标目标函数的一阶导数。
一阶导数,或简称为“导数”,是目标函数在特定点(例如,点)上的变化率或斜率。用于特定输入。
如果目标函数采用多个输入变量,则将其称为多元函数,并且可以将输入变量视为向量。反过来,多元目标函数的导数也可以视为向量,通常称为梯度。
梯度:多元目标函数的一阶导数。
对于特定输入,导数或梯度指向目标函数最陡峭的上升方向。梯度下降是指一种最小化优化算法,该算法遵循目标函数的下坡梯度负值来定位函数的最小值。
梯度下降算法需要一个正在优化的目标函数和该目标函数的导数函数。目标函数f()返回给定输入集合的分数,导数函数f'()给出给定输入集合的目标函数的导数。梯度下降算法需要问题中的起点(x),例如输入空间中的随机选择点。
假设我们正在最小化目标函数,然后计算导数并在输入空间中采取一步,这将导致目标函数下坡运动。首先通过计算输入空间中要移动多远的距离来进行下坡运动,计算方法是将步长(称为alpha或学习率)乘以梯度。然后从当前点减去该值,以确保我们逆梯度移动或向下移动目标函数。
x(t)= x(t-1)–step* f'(x(t))在给定点的目标函数越陡峭,梯度的大小越大,反过来,在搜索空间中采取的步伐也越大。使用步长超参数来缩放步长的大小。
步长:超参数,用于控制算法每次迭代相对于梯度在搜索空间中移动多远。
如果步长太小,则搜索空间中的移动将很小,并且搜索将花费很长时间。如果步长太大,则搜索可能会在搜索空间附近反弹并跳过最优值。
现在我们已经熟悉了梯度下降优化算法,接下来让我们看一下Nadam算法。
Nadam优化算法
Nesterov加速的自适应动量估计或Nadam算法是对自适应运动估计(Adam)优化算法的扩展,添加了Nesterov的加速梯度(NAG)或Nesterov动量,这是一种改进的动量。更广泛地讲,Nadam算法是对梯度下降优化算法的扩展。Timothy Dozat在2016年的论文“将Nesterov动量整合到Adam中”中描述了该算法。尽管论文的一个版本是在2015年以同名斯坦福项目报告的形式编写的。动量将梯度的指数衰减移动平均值(第一矩)添加到梯度下降算法中。这具有消除嘈杂的目标函数和提高收敛性的影响。Adam是梯度下降的扩展,它增加了梯度的第一和第二矩,并针对正在优化的每个参数自动调整学习率。NAG是动量的扩展,其中动量的更新是使用对参数的预计更新量而不是实际当前变量值的梯度来执行的。在某些情况下,这样做的效果是在找到最佳位置时减慢了搜索速度,而不是过冲。
纳丹(Nadam)是对亚当(Adam)的扩展,它使用NAG动量代替经典动量。让我们逐步介绍该算法的每个元素。Nadam使用衰减步长(alpha)和一阶矩(mu)超参数来改善性能。为了简单起见,我们暂时将忽略此方面,并采用恒定值。首先,对于搜索中要优化的每个参数,我们必须保持梯度的第一矩和第二矩,分别称为m和n。在搜索开始时将它们初始化为0.0。
m = 0
n = 0
该算法在从t = 1开始的时间t内迭代执行,并且每次迭代都涉及计算一组新的参数值x,例如。从x(t-1)到x(t)。如果我们专注于更新一个参数,这可能很容易理解该算法,该算法概括为通过矢量运算来更新所有参数。首先,计算当前时间步长的梯度(偏导数)。
g(t)= f'(x(t-1))接下来,使用梯度和超参数“ mu”更新第一时刻。
m(t)=mu* m(t-1)+(1 –mu)* g(t)然后使用“ nu”超参数更新第二时刻。
n(t)= nu * n(t-1)+(1 – nu)* g(t)^ 2接下来,使用Nesterov动量对第一时刻进行偏差校正。
mhat =(mu * m(t)/(1 – mu))+((1 – mu)* g(t)/(1 – mu))然后对第二个时刻进行偏差校正。注意:偏差校正是Adam的一个方面,它与在搜索开始时将第一时刻和第二时刻初始化为零这一事实相反。
nhat = nu * n(t)/(1 – nu)最后,我们可以为该迭代计算参数的值。
x(t)= x(t-1)– alpha /(sqrt(nhat)+ eps)* mhat其中alpha是步长(学习率)超参数,sqrt()是平方根函数,eps(epsilon)是一个较小的值,如1e-8,以避免除以零误差。
回顾一下,该算法有三个超参数。他们是:
alpha:初始步长(学习率),典型值为0.002。 mu:第一时刻的衰减因子(Adam中的beta1),典型值为0.975。 nu:第二时刻的衰减因子(Adam中的beta2),典型值为0.999。就是这样。接下来,让我们看看如何在python中从头开始实现该算法。
娜达姆(Nadam)的梯度下降
在本节中,我们将探索如何使用Nadam动量实现梯度下降优化算法。
二维测试问题
首先,让我们定义一个优化函数。我们将使用一个简单的二维函数,该函数将每个维的输入平方,并定义有效输入的范围(从-1.0到1.0)。下面的Objective()函数实现了此功能
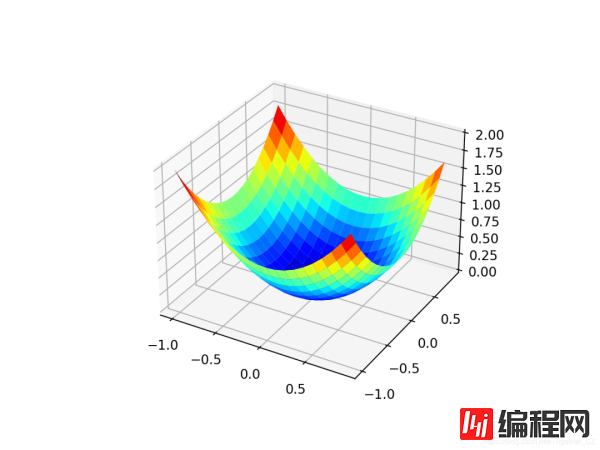
# objective function def objective(x, y): return x**2.0 + y**2.0我们可以创建数据集的三维图,以了解响应面的曲率。下面列出了绘制目标函数的完整示例。
# 3D plot of the test function from numpy import arange from numpy import meshgrid from matplotlib import pyplot # objective function def objective(x, y): return x**2.0 + y**2.0 # define range for input r_min, r_max = -1.0, 1.0 # sample input range unifORMly at 0.1 increments xaxis = arange(r_min, r_max, 0.1) yaxis = arange(r_min, r_max, 0.1) # create a mesh from the axis x, y = meshgrid(xaxis, yaxis) # compute targets results = objective(x, y) # create a surface plot with the jet color scheme figure = pyplot.figure() axis = figure.GCa(projection='3d') axis.plot_surface(x, y, results, cmap='jet') # show the plot pyplot.show()运行示例将创建目标函数的三维表面图。我们可以看到全局最小值为f(0,0)= 0的熟悉的碗形状。
我们还可以创建函数的二维图。这在以后要绘制搜索进度时会很有帮助。下面的示例创建目标函数的轮廓图。
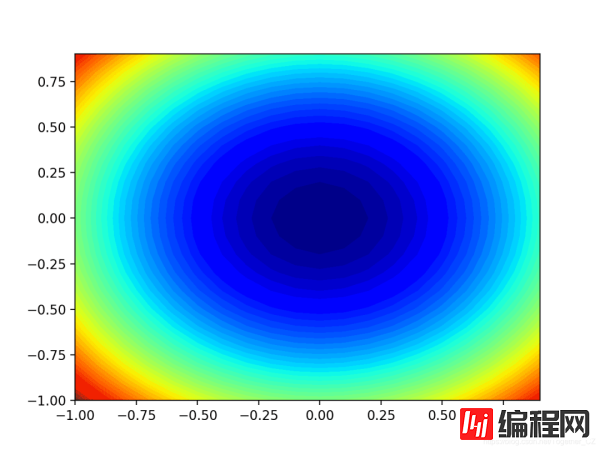
# contour plot of the test function from numpy import asarray from numpy import arange from numpy import meshgrid from matplotlib import pyplot # objective function def objective(x, y): return x**2.0 + y**2.0 # define range for input bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # sample input range uniformly at 0.1 increments xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # create a mesh from the axis x, y = meshgrid(xaxis, yaxis) # compute targets results = objective(x, y) # create a filled contour plot with 50 levels and jet color scheme pyplot.contourf(x, y, results, levels=50, cmap='jet') # show the plot pyplot.show()运行示例将创建目标函数的二维轮廓图。我们可以看到碗的形状被压缩为以颜色渐变显示的轮廓。我们将使用该图来绘制在搜索过程中探索的特定点。
现在我们有了一个测试目标函数,让我们看一下如何实现Nadam优化算法。
Nadam的梯度下降优化
我们可以将Nadam的梯度下降应用于测试问题。首先,我们需要一个函数来计算此函数的导数。
x ^ 2的导数在每个维度上均为x * 2。
f(x)= x ^ 2 f'(x)= x * 2derived()函数在下面实现了这一点。
# derivative of objective function def derivative(x, y): return asarray([x * 2.0, y * 2.0])接下来,我们可以使用Nadam实现梯度下降优化。首先,我们可以选择问题范围内的随机点作为搜索的起点。假定我们有一个数组,该数组定义搜索范围,每个维度一行,并且第一列定义最小值,第二列定义维度的最大值。
# generate an initial point x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1])接下来,我们需要初始化力矩矢量。
# initialize decaying moving averages m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])]然后,我们运行由“ n_iter”超参数定义的算法的固定迭代次数。
... # run iterations of gradient descent for t in range(n_iter): ...第一步是计算当前参数集的导数。
... # calculate gradient g(t) g = derivative(x[0], x[1])接下来,我们需要执行Nadam更新计算。为了提高可读性,我们将使用命令式编程样式来一次执行一个变量的这些计算。在实践中,我建议使用NumPy向量运算以提高效率。
... # build a solution one variable at a time for i in range(x.shape[0]): ...首先,我们需要计算力矩矢量。
# m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i]然后是第二个矩向量。
# nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2然后是经过偏差校正的内斯特罗夫动量。
# mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu))偏差校正的第二时刻。
# nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu)最后更新参数。
# x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat然后,针对要优化的每个参数重复此操作。在迭代结束时,我们可以评估新的参数值并报告搜索的性能。
# evaluate candidate point score = objective(x[0], x[1]) # report progress print('>%d f(%s) = %.5f' % (t, x, score))我们可以将所有这些结合到一个名为nadam()的函数中,该函数采用目标函数和派生函数的名称以及算法超参数,并返回在搜索及其评估结束时找到的最佳解决方案。
# gradient descent alGorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): # generate an initial point x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # initialize decaying moving averages m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # run the gradient descent for t in range(n_iter): # calculate gradient g(t) g = derivative(x[0], x[1]) # build a solution one variable at a time for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # evaluate candidate point score = objective(x[0], x[1]) # report progress print('>%d f(%s) = %.5f' % (t, x, score)) return [x, score]然后,我们可以定义函数和超参数的界限,并调用函数执行优化。在这种情况下,我们将运行该算法进行50次迭代,初始alpha为0.02,μ为0.8,nu为0.999,这是经过一点点反复试验后发现的。
# seed the pseudo random number generator seed(1) # define range for input bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # define the total iterations n_iter = 50 # steps size alpha = 0.02 # factor for average gradient mu = 0.8 # factor for average squared gradient nu = 0.999 # perform the gradient descent search with nadam best, score = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu)运行结束时,我们将报告找到的最佳解决方案。
# summarize the result print('Done!') print('f(%s) = %f' % (best, score))综合所有这些,下面列出了适用于我们的测试问题的Nadam梯度下降的完整示例。
# gradient descent optimization with nadam for a two-dimensional test function from math import sqrt from numpy import asarray from numpy.random import rand from numpy.random import seed # objective function def objective(x, y): return x**2.0 + y**2.0 # derivative of objective function def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # gradient descent algorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): # generate an initial point x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # initialize decaying moving averages m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # run the gradient descent for t in range(n_iter): # calculate gradient g(t) g = derivative(x[0], x[1]) # build a solution one variable at a time for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # evaluate candidate point score = objective(x[0], x[1]) # report progress print('>%d f(%s) = %.5f' % (t, x, score)) return [x, score] # seed the pseudo random number generator seed(1) # define range for input bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # define the total iterations n_iter = 50 # steps size alpha = 0.02 # factor for average gradient mu = 0.8 # factor for average squared gradient nu = 0.999 # perform the gradient descent search with nadam best, score = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) print('Done!') print('f(%s) = %f' % (best, score))运行示例将优化算法和Nadam应用于我们的测试问题,并报告算法每次迭代的搜索性能。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到在大约44次搜索迭代后找到了接近最佳的解决方案,输入值接近0.0和0.0,评估为0.0。
>40 f([ 5.07445337e-05 -3.32910019e-03]) = 0.00001 >41 f([-1.84325171e-05 -3.00939427e-03]) = 0.00001 >42 f([-6.78814472e-05 -2.69839367e-03]) = 0.00001 >43 f([-9.88339249e-05 -2.40042096e-03]) = 0.00001 >44 f([-0.00011368 -0.00211861]) = 0.00000 >45 f([-0.00011547 -0.00185511]) = 0.00000 >46 f([-0.0001075 -0.00161122]) = 0.00000 >47 f([-9.29922627e-05 -1.38760991e-03]) = 0.00000 >48 f([-7.48258406e-05 -1.18436586e-03]) = 0.00000 >49 f([-5.54299505e-05 -1.00116899e-03]) = 0.00000 Done! f([-5.54299505e-05 -1.00116899e-03]) = 0.000001可视化的Nadam优化
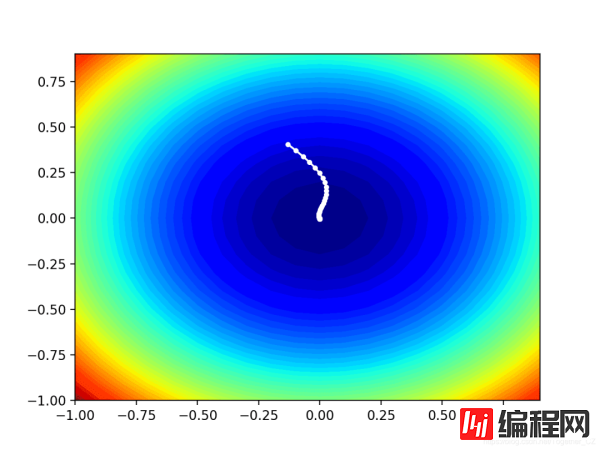
我们可以在域的等高线上绘制Nadam搜索的进度。这可以为算法迭代过程中的搜索进度提供直观的认识。我们必须更新nadam()函数以维护在搜索过程中找到的所有解决方案的列表,然后在搜索结束时返回此列表。下面列出了具有这些更改的功能的更新版本。
# gradient descent algorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): solutions = list() # generate an initial point x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # initialize decaying moving averages m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # run the gradient descent for t in range(n_iter): # calculate gradient g(t) g = derivative(x[0], x[1]) # build a solution one variable at a time for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # evaluate candidate point score = objective(x[0], x[1]) # store solution solutions.append(x.copy()) # report progress print('>%d f(%s) = %.5f' % (t, x, score)) return solutions然后,我们可以像以前一样执行搜索,这一次将检索解决方案列表,而不是最佳的最终解决方案。
# seed the pseudo random number generator seed(1) # define range for input bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # define the total iterations n_iter = 50 # steps size alpha = 0.02 # factor for average gradient mu = 0.8 # factor for average squared gradient nu = 0.999 # perform the gradient descent search with nadam solutions = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu)然后,我们可以像以前一样创建目标函数的轮廓图。
# sample input range uniformly at 0.1 increments xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # create a mesh from the axis x, y = meshgrid(xaxis, yaxis) # compute targets results = objective(x, y) # create a filled contour plot with 50 levels and jet color scheme pyplot.contourf(x, y, results, levels=50, cmap='jet')最后,我们可以将在搜索过程中找到的每个解决方案绘制成一条由一条线连接的白点。
# plot the sample as black circles solutions = asarray(solutions) pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w')综上所述,下面列出了对测试问题执行Nadam优化并将结果绘制在轮廓图上的完整示例。
# example of plotting the nadam search on a contour plot of the test function from math import sqrt from numpy import asarray from numpy import arange from numpy import product from numpy.random import rand from numpy.random import seed from numpy import meshgrid from matplotlib import pyplot from mpl_toolkits.mplot3d import Axes3D # objective function def objective(x, y): return x**2.0 + y**2.0 # derivative of objective function def derivative(x, y): return asarray([x * 2.0, y * 2.0]) # gradient descent algorithm with nadam def nadam(objective, derivative, bounds, n_iter, alpha, mu, nu, eps=1e-8): solutions = list() # generate an initial point x = bounds[:, 0] + rand(len(bounds)) * (bounds[:, 1] - bounds[:, 0]) score = objective(x[0], x[1]) # initialize decaying moving averages m = [0.0 for _ in range(bounds.shape[0])] n = [0.0 for _ in range(bounds.shape[0])] # run the gradient descent for t in range(n_iter): # calculate gradient g(t) g = derivative(x[0], x[1]) # build a solution one variable at a time for i in range(bounds.shape[0]): # m(t) = mu * m(t-1) + (1 - mu) * g(t) m[i] = mu * m[i] + (1.0 - mu) * g[i] # n(t) = nu * n(t-1) + (1 - nu) * g(t)^2 n[i] = nu * n[i] + (1.0 - nu) * g[i]**2 # mhat = (mu * m(t) / (1 - mu)) + ((1 - mu) * g(t) / (1 - mu)) mhat = (mu * m[i] / (1.0 - mu)) + ((1 - mu) * g[i] / (1.0 - mu)) # nhat = nu * n(t) / (1 - nu) nhat = nu * n[i] / (1.0 - nu) # x(t) = x(t-1) - alpha / (sqrt(nhat) + eps) * mhat x[i] = x[i] - alpha / (sqrt(nhat) + eps) * mhat # evaluate candidate point score = objective(x[0], x[1]) # store solution solutions.append(x.copy()) # report progress print('>%d f(%s) = %.5f' % (t, x, score)) return solutions # seed the pseudo random number generator seed(1) # define range for input bounds = asarray([[-1.0, 1.0], [-1.0, 1.0]]) # define the total iterations n_iter = 50 # steps size alpha = 0.02 # factor for average gradient mu = 0.8 # factor for average squared gradient nu = 0.999 # perform the gradient descent search with nadam solutions = nadam(objective, derivative, bounds, n_iter, alpha, mu, nu) # sample input range uniformly at 0.1 increments xaxis = arange(bounds[0,0], bounds[0,1], 0.1) yaxis = arange(bounds[1,0], bounds[1,1], 0.1) # create a mesh from the axis x, y = meshgrid(xaxis, yaxis) # compute targets results = objective(x, y) # create a filled contour plot with 50 levels and jet color scheme pyplot.contourf(x, y, results, levels=50, cmap='jet') # plot the sample as black circles solutions = asarray(solutions) pyplot.plot(solutions[:, 0], solutions[:, 1], '.-', color='w') # show the plot pyplot.show()运行示例将像以前一样执行搜索,但是在这种情况下,将创建目标函数的轮廓图。
在这种情况下,我们可以看到在搜索过程中找到的每个解决方案都显示一个白点,从最优点开始,逐渐靠近图中心的最优点。
以上是“如何使用Nadam进行梯度下降优化”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注编程网VUE频道!
--结束END--
本文标题: 如何使用Nadam进行梯度下降优化
本文链接: https://www.lsjlt.com/news/80304.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0