本篇内容介绍了“如何用node.js编写内存效率高的应用程序”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
本篇内容介绍了“如何用node.js编写内存效率高的应用程序”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
问题:大文件复制
如果有人被要求用 nodejs 写一段文件复制的程序,那么他会迅速写出下面这段代码:
const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; fs.readFile(fileName, (err, data) => { if (err) throw err; fs.writeFile(destPath || 'output', data, (err) => { if (err) throw err; }); console.log('New file has been created!'); });这段代码简单地根据输入的文件名和路径,在尝试对文件读取后把它写入目标路径,这对于小文件来说是不成问题的。
现在假设我们有一个大文件(大于4 GB)需要用这段程序来进行备份。就以我的一个达 7.4G 的超高清4K 电影为例子好了,我用上述的程序代码把它从当前目录复制到别的目录。
$ node basic_copy.js cartoonMovie.mkv ~/Documents/bigMovie.mkv然后在 ubuntu(linux )系统下我得到了这段报错:
/home/shobarani/Workspace/basic_copy.js:7 if (err) throw err; ^ RangeError: File size is greater than possible Buffer: 0x7fffffff bytes at FSReqWrap.readFileAfterStat [as oncomplete] (fs.js:453:11)正如你看到的那样,由于 NodeJS 最大只允许写入 2GB 的数据到它的缓冲区,导致了错误发生在读取文件的过程中。为了解决这个问题,当你在进行 I/O 密集操作的时候(复制、处理、压缩等),最好考虑一下内存的情况。
NodeJS 中的 Streams 和 Buffers
为了解决上述问题,我们需要一个办法把大文件切成许多文件块,同时需要一个数据结构去存放这些文件块。一个 buffer 就是用来存储二进制数据的结构。接下来,我们需要一个读写文件块的方法,而 Streams 则提供了这部分能力。
Buffers(缓冲区)
我们能够利用 Buffer 对象轻松地创建一个 buffer。
let buffer = new Buffer(10); # 10 为 buffer 的体积 console.log(buffer); # prints <Buffer 00 00 00 00 00 00 00 00 00 00>在新版本的 NodeJS (>8)中,你也可以这样写。
let buffer = new Buffer.alloc(10); console.log(buffer); # prints <Buffer 00 00 00 00 00 00 00 00 00 00>如果我们已经有了一些数据,比如数组或者别的数据集,我们可以为它们创建一个 buffer。
let name = 'Node JS DEV'; let buffer = Buffer.from(name); console.log(buffer) # prints <Buffer 4e 6f 64 65 20 4a 53 20 44 45 5>Buffers 有一些如 buffer.toString() 和 buffer.toJSON() 之类的重要方法,能够深入到其所存储的数据当中去。
我们不会为了优化代码而去直接创建原始 buffer。NodeJS 和 V8 引擎在处理 streams 和网络 Socket 的时候就已经在创建内部缓冲区(队列)中实现了这一点。
Streams(流)
简单来说,流就像 NodeJS 对象上的任意门。在计算机网络中,入口是一个输入动作,出口是一个输出动作。我们接下来将继续使用这些术语。
流的类型总共有四种:
可读流(用于读取数据)
可写流(用于写入数据)
双工流(同时可用于读写)
转换流(一种用于处理数据的自定义双工流,如压缩,检查数据等)
下面这句话可以清晰地阐述为什么我们应该使用流。
Stream api (尤其是 stream.pipe() 方法)的一个重要目标是将数据缓冲限制在可接受的水平,这样不同速度的源和目标就不会阻塞可用内存。
我们需要一些办法去完成任务而不至于压垮系统。这也是我们在文章开头就已经提到过的。
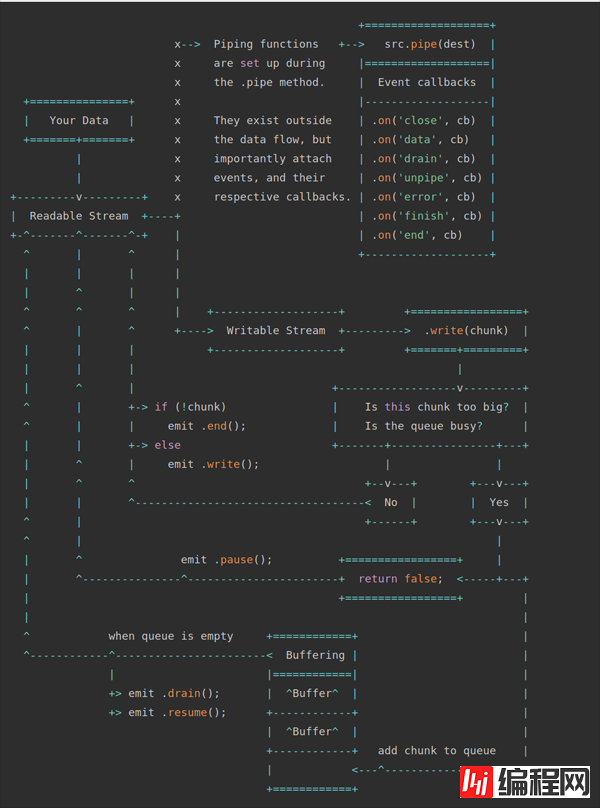
上面的示意图中我们有两个类型的流,分别是可读流和可写流。.pipe() 方法是一个非常基本的方法,用于连接可读流和可写流。如果你不明白上面的示意图,也没关系,在看完我们的例子以后,你可以回到示意图这里来,那个时候一切都会显得理所当然。管道是一种引人注目的机制,下面我们用两个例子来说明它。
解法1(简单地使用流来复制文件)
让我们设计一种解法来解决前文中大文件复制的问题。首先我们要创建两个流,然后执行接下来的几个步骤。
鸿蒙官方战略合作共建——HarmonyOS技术社区
监听来自可读流的数据块
把数据块写进可写流
跟踪文件复制的进度
我们把这段代码命名为 streams_copy_basic.js
const stream = require('stream'); const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; const readabale = fs.createReadStream(fileName); const writeable = fs.createWriteStream(destPath || "output"); fs.stat(fileName, (err, stats) => { this.fileSize = stats.size; this.counter = 1; this.fileArray = fileName.split('.'); try { this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1]; } catch(e) { console.exception('File name is invalid! please pass the proper one'); } process.stdout.write(`File: ${this.duplicate} is being created:`); readabale.on('data', (chunk)=> { let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100; process.stdout.clearLine(); // clear current text process.stdout.cursorTo(0); process.stdout.write(`${Math.round(percentageCopied)}%`); writeable.write(chunk); this.counter += 1; }); readabale.on('end', (e) => { process.stdout.clearLine(); // clear current text process.stdout.cursorTo(0); process.stdout.write("Successfully finished the operation"); return; }); readabale.on('error', (e) => { console.log("Some error occured: ", e); }); writeable.on('finish', () => { console.log("Successfully created the file copy!"); }); });在这段程序中,我们接收用户传入的两个文件路径(源文件和目标文件),然后创建了两个流,用于把数据块从可读流运到可写流。然后我们定义了一些变量去追踪文件复制的进度,然后输出到控制台(此处为 console)。与此同时我们还订阅了一些事件:
data:当一个数据块被读取时触发
end:当一个数据块被可读流所读取完的时候触发
error:当读取数据块的时候出错时触发
运行这段程序,我们可以成功地完成一个大文件(此处为7.4 G)的复制任务。
$ time node streams_copy_basic.js cartoonMovie.mkv ~/Documents/4kdemo.mkv然而,当我们通过任务管理器观察程序在运行过程中的内存状况时,依旧有一个问题。
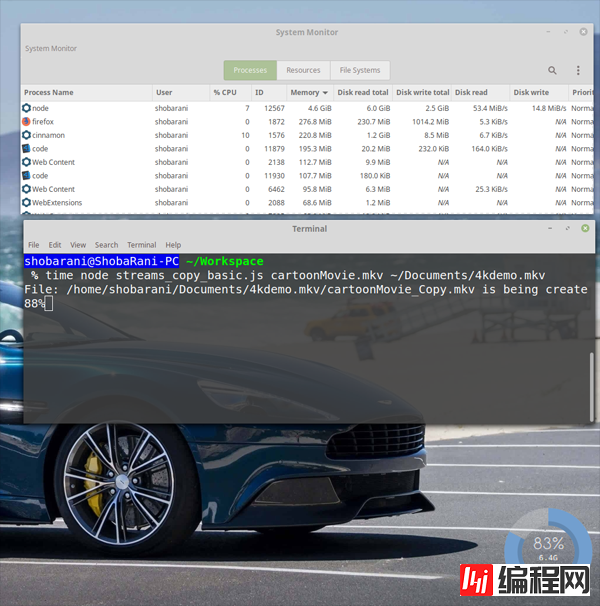
4.6GB?我们的程序在运行时所消耗的内存,在这里是讲不通的,以及它很有可能会卡死其他的应用程序。
发生了什么?
如果你有仔细观察上图中的读写率,你会发现一些端倪。
Disk Read: 53.4 MiB/s
Disk Write: 14.8 MiB/s
这意味着生产者正在以更快的速度生产,而消费者无法跟上这个速度。计算机为了保存读取的数据块,将多余的数据存储到机器的RAM中。这就是RAM出现峰值的原因。
上述代码在我的机器上运行了3分16秒……
17.16s user 25.06s system 21% cpu 3:16.61 total解法2(基于流和自动背压的文件复制)
为了克服上述问题,我们可以修改程序来自动调整磁盘的读写速度。这个机制就是背压。我们不需要做太多,只需将可读流导入可写流即可,NodeJS 会负责背压的工作。
让我们将这个程序命名为 streams_copy_efficient.js
const stream = require('stream'); const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; const readabale = fs.createReadStream(fileName); const writeable = fs.createWriteStream(destPath || "output"); fs.stat(fileName, (err, stats) => { this.fileSize = stats.size; this.counter = 1; this.fileArray = fileName.split('.'); try { this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1]; } catch(e) { console.exception('File name is invalid! please pass the proper one'); } process.stdout.write(`File: ${this.duplicate} is being created:`); readabale.on('data', (chunk) => { let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100; process.stdout.clearLine(); // clear current text process.stdout.cursorTo(0); process.stdout.write(`${Math.round(percentageCopied)}%`); this.counter += 1; }); readabale.pipe(writeable); // Auto pilot ON! // In case if we have an interruption while copying writeable.on('unpipe', (e) => { process.stdout.write("Copy has failed!"); }); });在这个例子中,我们用一句代码替换了之前的数据块写入操作。
readabale.pipe(writeable); // Auto pilot ON!这里的 pipe 就是所有魔法发生的原因。它控制了磁盘读写的速度以至于不会阻塞内存(RAM)。
运行一下。
$ time node streams_copy_efficient.js cartoonMovie.mkv ~/Documents/4kdemo.mkv我们复制了同一个大文件(7.4 GB),让我们来看看内存利用率。
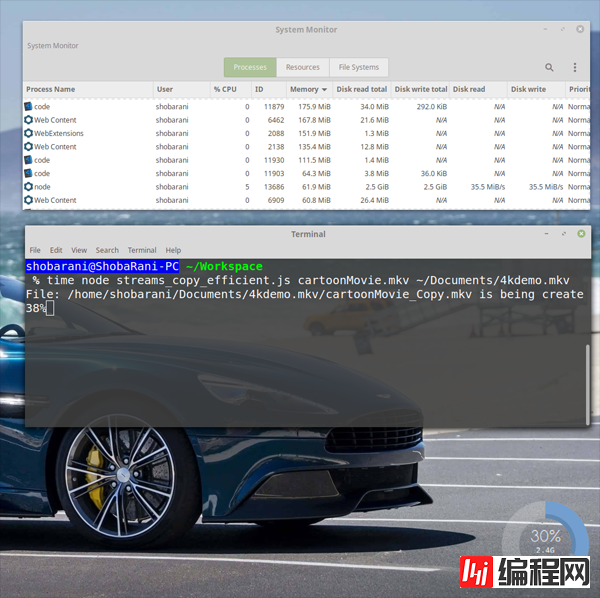
震惊!现在 Node 程序仅仅占用了61.9 MiB 的内存。如果你观察到读写速率的话:
Disk Read: 35.5 MiB/s
Disk Write: 35.5 MiB/s
在任意给定的时间内,因为背压的存在,读写速率得以保持一致。更让人惊喜的是,这段优化后的程序代码整整比之前的快了13秒。
12.13s user 28.50s system 22% cpu 3:03.35 total由于 NodeJS 流和管道,内存负载减少了98.68%,执行时间也减少了。这就是为什么管道是一个强大的存在。
61.9 MiB 是由可读流创建的缓冲区大小。我们还可以使用可读流上的 read 方法为缓冲块分配自定义大小。
const readabale = fs.createReadStream(fileName); readable.read(no_of_bytes_size);除了本地文件的复制以外,这个技术还可以用于优化许多 I/O 操作的问题:
处理从卡夫卡到数据库的数据流
处理来自文件系统的数据流,动态压缩并写入磁盘
更多……
“如何用Node.js编写内存效率高的应用程序”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注编程网网站,小编将为大家输出更多高质量的实用文章!
--结束END--
本文标题: 如何用Node.js编写内存效率高的应用程序
本文链接: https://www.lsjlt.com/news/81004.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0