本文主要针对日志数据接入数据仓库场景进行设计, 同时介绍了下在设计接入时的一些细节,针对可能出现的问题进行必要的处理. 背景 主要针对用户流量数据、风控数据、人物画像等数据进行同步至数仓, 制
![[平台建设] 日志数据同步数仓设计](/upload/202205/01/3fgco2rfxqd.jpg)
主要针对用户流量数据、风控数据、人物画像等数据进行同步至数仓, 制定数据传输格式为JSON,将用户数据解析写入Hive中,以T+1形式交付给用户,以便用户后续统计分析.
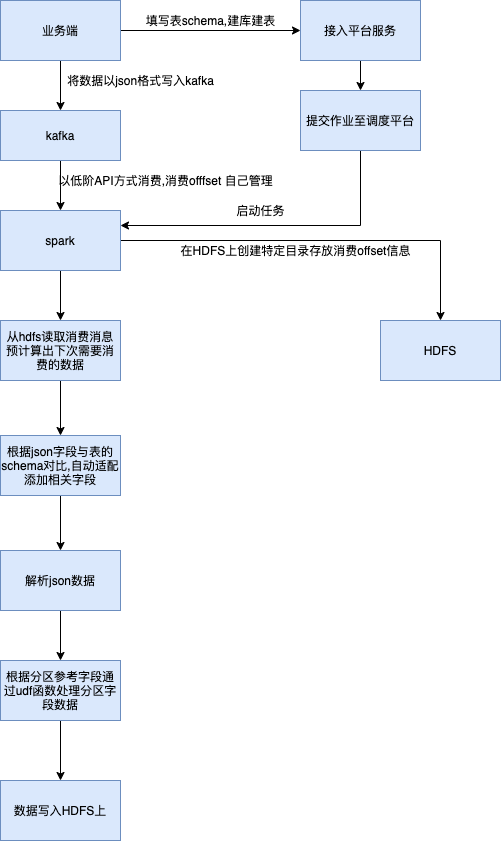
创建工作目录,用于记录kafka消费偏移量, 如果消费完毕将tmp后缀改为success, 第二次消费根据最后一个success后缀文件与kafka 接口计算出下次消费的偏移量数据数据.
任务启动创建lock 文件,避免调度时任务冲突,只有当第一批次任务成功完成时,再删除lock文件
自适应匹配添加字段, 通过数据字段与原始schema对比自动添加字段
在driver端代码内添加必要的日志,如消费的条数, 通过spark累加器计算executor处理失败的条数数据
针对流量数据等需要添加过滤功能, 避免测试数据或者大量的异常数据过来导致任务失败、消耗资源过多等情况,算是一个兜底的方案,
可以根据时间字段过滤特定时间段数据 或者根据某个字段关键字进行过滤
小文件处理, 主要是在写入hdfs时候, 对写入数据进行repartition 操作,根据期望分区文件数(并行度),根据下面的udf函数随机将数据打散写入hdfs文件中
val udf_shuffle_partition = udf((partitions: String) => {
partitions + new Random().nextInt(parallelismPerPartiton)
})
本文主要针对日志数据接入数据仓库场景进行设计, 同时介绍了下在设计接入时的一些细节,针对可能出现的问题进行必要的处理.
本文作者: chaplinthink, 关注领域:大数据、基础架构、系统设计, 一个热爱学习、分享的大数据工程师--结束END--
本文标题: [平台建设] 日志数据同步数仓设计
本文链接: https://www.lsjlt.com/news/9056.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
2024-05-08
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作


0