本文小编为大家详细介绍“怎么用node抓取小说章节”,内容详细,步骤清晰,细节处理妥当,希望这篇“怎么用node抓取小说章节”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。准备用e
本文小编为大家详细介绍“怎么用node抓取小说章节”,内容详细,步骤清晰,细节处理妥当,希望这篇“怎么用node抓取小说章节”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。

准备用electron制作一个小说阅读工具练练手,那么首先要解决的就是数据问题,也就是小说的文本。
这里准备使用nodejs对小说网站进行爬虫爬取,尝试爬下一本小说,数据就不存放数据库了,先使用txt作为文本存储
在node中对于网站的请求,本身就存在Http和https库,内部含有request请求方法。
实例:
request = https.request(TestUrl, { encoding:'utf-8' }, (res)=>{
let chunks = ''
res.on('data', (chunk)=>{
chunks += chunk
})
res.on('end',function(){
console.log('请求结束');
})
})但是也就到此为止了,只是存取了一个html的文本数据,并不能够对内部元素进行提取之类的工作(也可以正则拿,但是太过复杂)。
我将访问到的数据通过fs.writeFile方法存储起来了,这只是整个网页的html
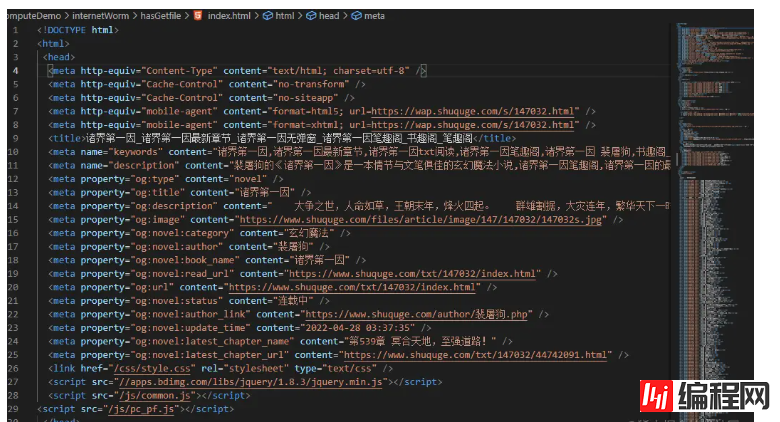
但是我想要的还有各个章节中的内容,这样一来就需要获取章节的超链接,组成超链接链表进去爬取
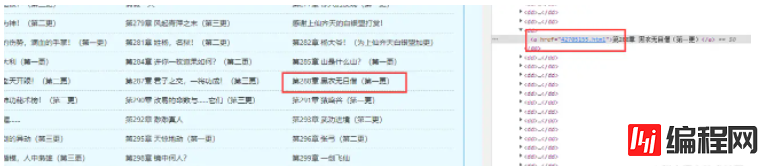
在文档中,可以使用示例进行调试
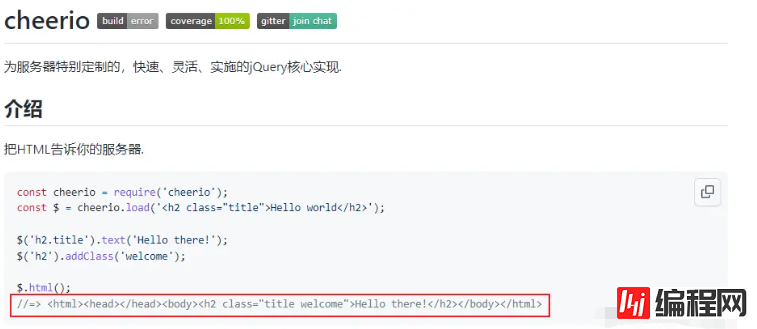
cheerio解析html时,获取dom节点的方式与Jquery相似。
根据之前获取到的书籍首页的html,查找自己想要的dom节点数据
const fs = require('fs')
const cheerio = require('cheerio');
// 引入读取方法
const { getFile, writeFun } = require('./requestNovel')
let hasIndexPromise = getFile('./hasGetfile/index.html');
let bookArray = [];
hasIndexPromise.then((res)=>{
let htmlstr = res;
let $ = cheerio.load(htmlstr);
$(".listmain dl dd a").map((index, item)=>{
let name = $(item).text(), href = 'https://www.shuquge.com/txt/147032/' + $(item).attr('href')
if (index > 11){
bookArray.push({ name, href })
}
})
// console.log(bookArray)
writeFun('./hasGetfile/hrefList.txt', JSON.stringify(bookArray), 'w')
})打印一下信息
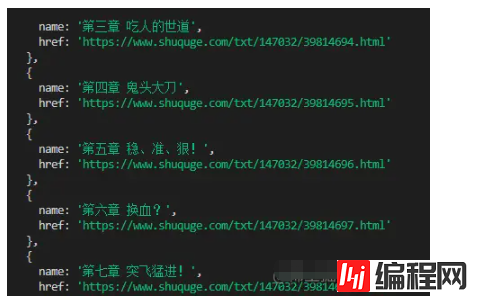
可以同时将这些信息也存储起来
现在章节数和章节的链接都有了,那么就可以获取章节的内容了。
因为批量爬取最后需要IP代理,这里还没准备,暂时先写获取某一章节小说的内容方法
爬取某一章节的内容其实也比较简单:
// 爬取某一章节的内容方法
function getOneChapter(n) {
return new Promise((resolve, reject)=>{
if (n >= bookArray.length) {
reject('未能找到')
}
let name = bookArray[n].name;
request = https.request(bookArray[n].href, { encoding:'gbk' }, (res)=>{
let html = ''
res.on('data', chunk=>{
html += chunk;
})
res.on('end', ()=>{
let $ = cheerio.load(html);
let content = $("#content").text();
if (content) {
// 写成txt
writeFun(`./hasGetfile/${name}.txt`, content, 'w')
resolve(content);
} else {
reject('未能找到')
}
})
})
request.end();
})
}
getOneChapter(10)
这样,就可以根据上面的方法,来创造一个调用接口,传入不同的章节参数,获取当前章节的数据
const express = require('express');
const IO = express();
const { getAllChapter, getOneChapter } = require('./readIndex')
// 获取章节超链接链表
getAllChapter();
IO.use('/book',function(req, res) {
// 参数
let query = req.query;
if (query.n) {
// 获取某一章节数据
let promise = getOneChapter(parseInt(query.n - 1));
promise.then((d)=>{
res.json({ d: d })
}, (d)=>{
res.json({ d: d })
})
} else {
res.json({ d: 404 })
}
})
//服务器本地主机的数字
IO.listen('7001',function(){
console.log("启动了。。。");
})读到这里,这篇“怎么用node抓取小说章节”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注编程网node.js频道。
--结束END--
本文标题: 怎么用node抓取小说章节
本文链接: https://www.lsjlt.com/news/97647.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
2022-06-04
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0