这篇文章主要讲解了“怎么理解nodejs中的流”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么理解nodejs中的流”吧!如何理解流对于流的使用者来说,可
这篇文章主要讲解了“怎么理解nodejs中的流”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么理解nodejs中的流”吧!

对于流的使用者来说,可以将流看作一个数组,我们只需要关注从中获取(消费)和写入(生产)就可以了。
对于流的开发者(使用stream模块创建一个新实例),关注的是如何实现流中的一些方法,通常关注两点,目标资源是谁和如何操作目标资源,确定了后就需要根据流的不同状态和事件来对目标资源进行操作
NodeJs 中所有的流都有缓冲池,缓冲池存在的目的是增加流的效率,当数据的生产和消费都需要时间时,我们可以在下一次消费前提前生产数据存放到缓冲池。但是缓冲池并不是时刻都处于使用状态,例如缓存池为空时,数据生产后就不会放入缓存池而是直接消费。 。
如果数据生产的速度大于数据的消费速度,多余的数据会在某个地方等待。如果数据的生产速度小于进程数据的消费速度,那么数据会在某个地方累计到一定的数量,然后在进行消费。(开发者无法控制数据的生产和消费速度,只能尽量在何时的时机生产数据或者消费数据)
那个数据等待,累计数据,然后发生出去的地方。就是缓冲池。缓冲池通常位于电脑的RAM(内存)中。
举一个常见的缓冲区的例子,我们在观看在线视频的时候,如果你的网速很快,缓冲区总是会被立即填充,然后发送给系统播放,然后立即缓冲下一段视频。观看的过程中,不会有卡顿。如果网速很慢,则会看到loading,表示缓冲区正在被填充,当填充完成后数据被发送给系统,才能看到这段视频。
NodeJs 流的缓存池是一个 Buffer 链表,每一次想缓存池中加入数据都会重新创建一个 Buffer 节点插入到链表尾部。
NodeJs 中对 Stream 是一个实现了 EventEmitter 的抽象接口,所以我会先简单的介绍一下 EventEmitter。
EventEmitter 是一个实现事件发布订阅功能的类,其中常用的几个方法(on, once, off, emit)相信大家都耳熟能详了,就不一一介绍了。
const { EventEmitter } = require('events')
const eventEmitter = new EventEmitter()
// 为 eventA 事件绑定处理函数
eventEmitter.on('eventA', () => {
console.log('eventA active 1');
});
// 为 eventB 事件绑定处理函数
eventEmitter.on('eventB', () => {
console.log('eventB active 1');
});
eventEmitter.once('eventA', () => {
console.log('eventA active 2');
});
// 触发 eventA
eventEmitter.emit('eventA')
// eventA active 1
// eventA active 2值得注意的是, EventEmitter 有两个叫做 newListener 和 removeListener 的事件,当你向一个事件对象中添加任何事件监听函数后,都会触发 newListener(eventEmitter.emit('newListener')),当一个处理函数被移除时同理会触发 removeListener。
还需要注意的是, once 绑定的处理函数只会执行一次,removeListener 将在其执行前被触发,这意味着 once 绑定的监听函数是先被移除才被触发的。
const { EventEmitter } = require('events')
const eventEmitter = new EventEmitter()
eventEmitter.on('newListener', (event, listener)=>{
console.log('newListener', event, listener)
})
eventEmitter.on('removeListener', (event, listener) => {
console.log('removeListener', event, listener)
})
//newListener removeListener[Function(anonymous)]
eventEmitter.on('eventA', () => {
console.log('eventA active 1');
});
//newListener eventA [Function (anonymous)]
function listenerB() { console.log('eventB active 1'); }
eventEmitter.on('eventB', listenerB);
// newListener eventB [Function (anonymous)]
eventEmitter.once('eventA', () => {
console.log('eventA active 2');
});
// newListener eventA [Function (anonymous)]
eventEmitter.emit('eventA')
// eventA active 1
// removeListener eventA [Function: bound onceWrapper] { listener: [Function (anonymous)] }
// eventA active 2
eventEmitter.off('eventB', listenerB)
// removeListener eventB[Function: listenerB]不过这对于我们后面的内容来说并不重要。
Stream 是在 node.js 中处理流数据的抽象接口。Stream 并不是一个实际的接口,而是对所有流的一种统称。实际的接口有 ReadableStream、 WritableStream、ReadWriteStream 这几个。
interface ReadableStream extends EventEmitter {
readable: boolean;
read(size?: number): string | Buffer;
setEncoding(encoding: BufferEncoding): this;
pause(): this;
resume(): this;
isPaused(): boolean;
pipe<T extends WritableStream>(destination: T, options?: { end?: boolean | undefined; }): T;
unpipe(destination?: WritableStream): this;
unshift(chunk: string | Uint8Array, encoding?: BufferEncoding): void;
wrap(oldStream: ReadableStream): this;
[Symbol.asyncIterator](): AsyncIterableIterator<string | Buffer>;
}
interface WritableStream extends EventEmitter {
writable: boolean;
write(buffer: Uint8Array | string, cb?: (err?: Error | null) => void): boolean;
write(str: string, encoding?: BufferEncoding, cb?: (err?: Error | null) => void): boolean;
end(cb?: () => void): this;
end(data: string | Uint8Array, cb?: () => void): this;
end(str: string, encoding?: BufferEncoding, cb?: () => void): this;
}
interface ReadWriteStream extends ReadableStream, WritableStream { }可以看出 ReadableStream 和 WritableStream 都是继承 EventEmitter 类的接口(ts中接口是可以继承类的,因为他们只是在进行类型的合并)。
上面这些接口对应的实现类分别是 Readable、Writable 和 Duplex
NodeJs中的流有4种:
Readable 可读流(实现ReadableStream)
Writable 可写流(实现WritableStream)
Duplex 可读可写流(继承Readable后实现WritableStream)
TransfORM 转换流(继承Duplex)
磁盘写入数据的速度是远低于内存的,我们想象内存和磁盘之间有一个“管道”,“管道”中是“流”,内存的数据流入管道是非常快的,当管道塞满时,内存中就会产生数据背压,数据积压在内存中,占用资源。
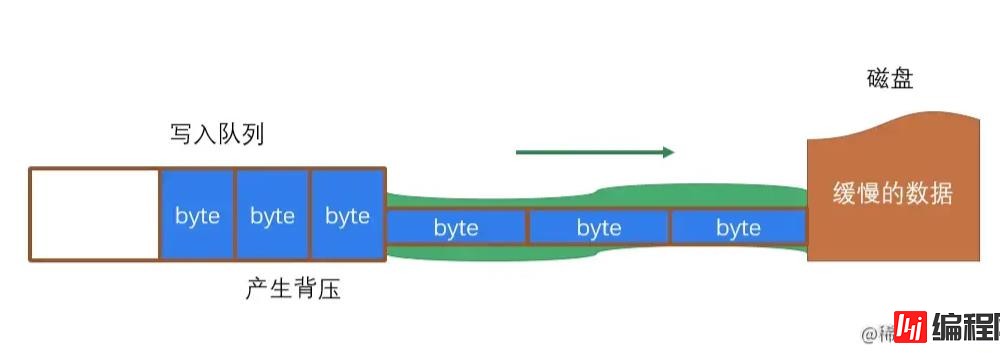
NodeJs Stream 的解决办法是为每一个流的 缓存池(就是图中写入队列)设置一个浮标值,当其中数据量达到这个浮标值后,往缓存池再次 push 数据时就会返回 false,表示当前流中缓存池内容已经达到浮标值,不希望再有数据写入了,这时我们应该立即停止数据的生产,防止缓存池过大产生背压。
可读流(Readable)是流的一种类型,他有两种模式三种状态
两种读取模式:
流动模式:数据会从底层系统读取写入到缓冲区,当缓冲区被写满后自动通过 EventEmitter 尽快的将数据传递给所注册的事件处理程序中
暂停模式:在这种模式下将不会主动触发 EventEmitter 传输数据,必须显示的调用 Readable.read() 方法来从缓冲区中读取数据,read 会触发响应到 EventEmitter 事件。
三种状态:
readableFlowing === null(初始状态)
readableFlowing === false(暂停模式)
readableFlowing === true(流动模式)
初始时流的 readable.readableFlowing 为 null
添加data事件后变为 true 。调用 pause()、unpipe()、或接收到背压或者添加 readable 事件,则 readableFlowing 会被设为 false ,在这个状态下,为 data 事件绑定监听器不会使 readableFlowing 切换到 true。
调用 resume() 可以让可读流的 readableFlowing 切换到 true
移除所有的 readable 事件是使 readableFlowing 变为 null 的唯一方法。
| 事件名 | 说明 |
|---|---|
| readable | 当缓冲区有新的可读取数据时触发(每一个想缓存池插入节点都会触发) |
| data | 每一次消费数据后都会触发,参数是本次消费的数据 |
| close | 流关闭时触发 |
| error | 流发生错误时触发 |
| 方法名 | 说明 |
|---|---|
| read(size) | 消费长度为size的数据,返回null表示当前数据不足size,否则返回本次消费的数据。size不传递时表示消费缓存池中所有数据 |
const fs = require('fs');
const readStreams = fs.createReadStream('./EventEmitter.js', {
highWaterMark: 100// 缓存池浮标值
})
readStreams.on('readable', () => {
console.log('缓冲区满了')
readStreams.read()// 消费缓存池的所有数据,返回结果并且触发data事件
})
readStreams.on('data', (data) => {
console.log('data')
})https://GitHub1s.com/nodejs/node/blob/v16.14.0/lib/internal/streams/readable.js#L527
当 size 为 0 会触发 readable 事件。
当缓存池中的数据长度达到浮标值 highWaterMark 后,就不会在主动请求生产数据,而是等待数据被消费后在生产数据
暂停状态的流如果不调用 read 来消费数据时,后续也不会在触发 data 和 readable,当调用 read 消费时会先判断本次消费后剩余的数据长度是否低于 浮标值,如果低于 浮标值 就会在消费前请求生产数据。这样在 read 后的逻辑执行完成后新的数据大概率也已经生产完成,然后再次触发 readable,这种提前生产下一次消费的数据存放在缓存池的机制也是缓存流为什么快的原因
流动状态下的流有两种情况
生产速度慢于消费速度时:这种情况下每一个生产数据后一般缓存池中都不会有剩余数据,直接将本次生产的数据传递给 data 事件即可(因为没有进入缓存池,所以也不用调用 read 来消费),然后立即开始生产新数据,待上一次数据消费完后新数据才生产好,再次触发 data ,一只到流结束。
生产速度快于消费速度时:此时每一次生产完数据后一般缓存池都还存在未消费的数据,这种情况一般会在消费数据时开始生产下一次消费的数据,待旧数据消费完后新数据已经生产完并且放入缓存池
他们的区别仅仅在于数据生产后缓存池是否还存在数据,如果存在数据则将生产的数据 push 到缓存池等待消费,如果不存在则直接将数据交给 data 而不加入缓存池。
值得注意的是当一个缓存池中存在数据的流从暂停模式进入的流动模式时,会先循环调用 read 来消费数据只到返回 null
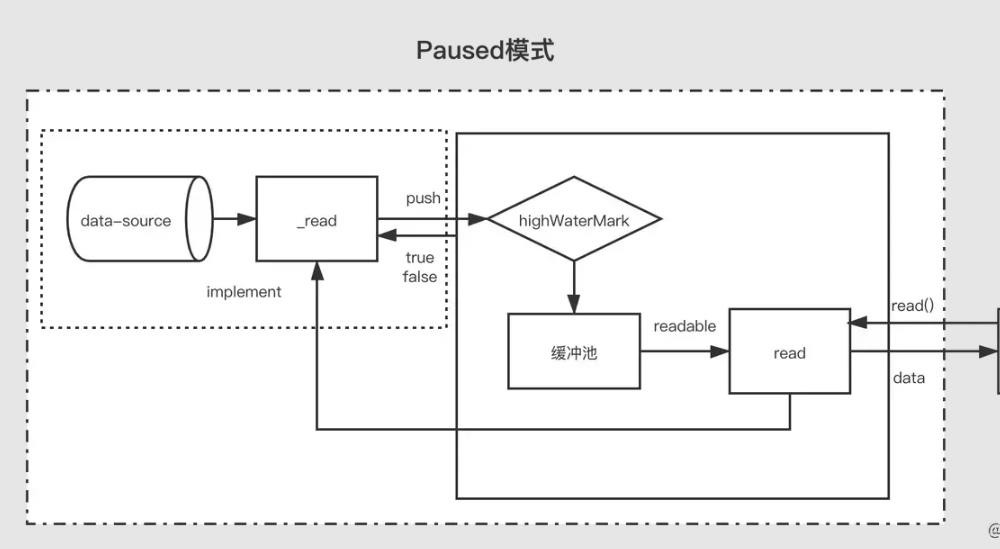
暂停模式下,一个可读流读创建时,模式是暂停模式,创建后会自动调用 _read 方法,把数据从数据源 push 到缓冲池中,直到缓冲池中的数据达到了浮标值。每当数据到达浮标值时,可读流会触发一个 " readable " 事件,告诉消费者有数据已经准备好了,可以继续消费。
一般来说, 'readable' 事件表明流有新的动态:要么有新的数据,要么到达流的尽头。所以,数据源的数据被读完前,也会触发一次 'readable' 事件;
消费者 " readable " 事件的处理函数中,通过 stream.read(size) 主动消费缓冲池中的数据。
const { Readable } = require('stream')
let count = 1000
const myReadable = new Readable({
highWaterMark: 300,
// 参数的 read 方法会作为流的 _read 方法,用于获取源数据
read(size) {
// 假设我们的源数据上 1000 个1
let chunk = null
// 读取数据的过程一般是异步的,例如IO操作
setTimeout(() => {
if (count > 0) {
let chunkLength = Math.min(count, size)
chunk = '1'.repeat(chunkLength)
count -= chunkLength
}
this.push(chunk)
}, 500)
}
})
// 每一次成功 push 数据到缓存池后都会触发 readable
myReadable.on('readable', () => {
const chunk = myReadable.read()//消费当前缓存池中所有数据
console.log(chunk.toString())
})值得注意的是, 如果 read(size) 的 size 大于浮标值,会重新计算新的浮标值,新浮标值是size的下一个二次幂(size <= 2^n,n取最小值)
// hwm 不会大于 1GB.
const MAX_HWM = 0x40000000;
function computeNewHighWaterMark(n) {
if (n >= MAX_HWM) {
// 1GB限制
n = MAX_HWM;
} else {
//取下一个2最高幂,以防止过度增加hwm
n--;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
n++;
}
return n;
}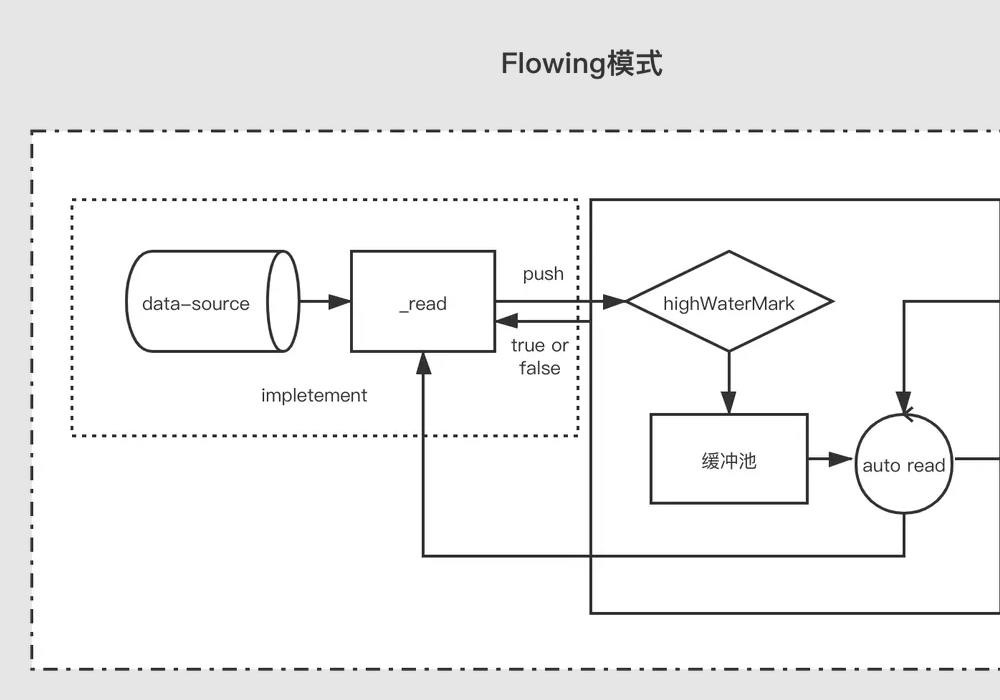
所有可读流开始的时候都是暂停模式,可以通过以下方法可以切换至流动模式:
添加 " data " 事件句柄;
调用 “ resume ”方法;
使用 " pipe " 方法把数据发送到可写流
流动模式下,缓冲池里面的数据会自动输出到消费端进行消费,同时,每次输出数据后,会自动回调 _read 方法,把数据源的数据放到缓冲池中,如果此时缓存池中不存在数据则会直接吧数据传递给 data 事件,不会经过缓存池;直到流动模式切换至其他暂停模式,或者数据源的数据被读取完了( push(null) );
可读流可以通过以下方式切换回暂停模式:
如果没有管道目标,则调用 stream.pause() 。
如果有管道目标,则移除所有管道目标。调用 stream.unpipe() 可以移除多个管道目标。
const { Readable } = require('stream')
let count = 1000
const myReadable = new Readable({
highWaterMark: 300,
read(size) {
let chunk = null
setTimeout(() => {
if (count > 0) {
let chunkLength = Math.min(count, size)
chunk = '1'.repeat(chunkLength)
count -= chunkLength
}
this.push(chunk)
}, 500)
}
})
myReadable.on('data', data => {
console.log(data.toString())
})相对可读流来说,可写流要简单一些。
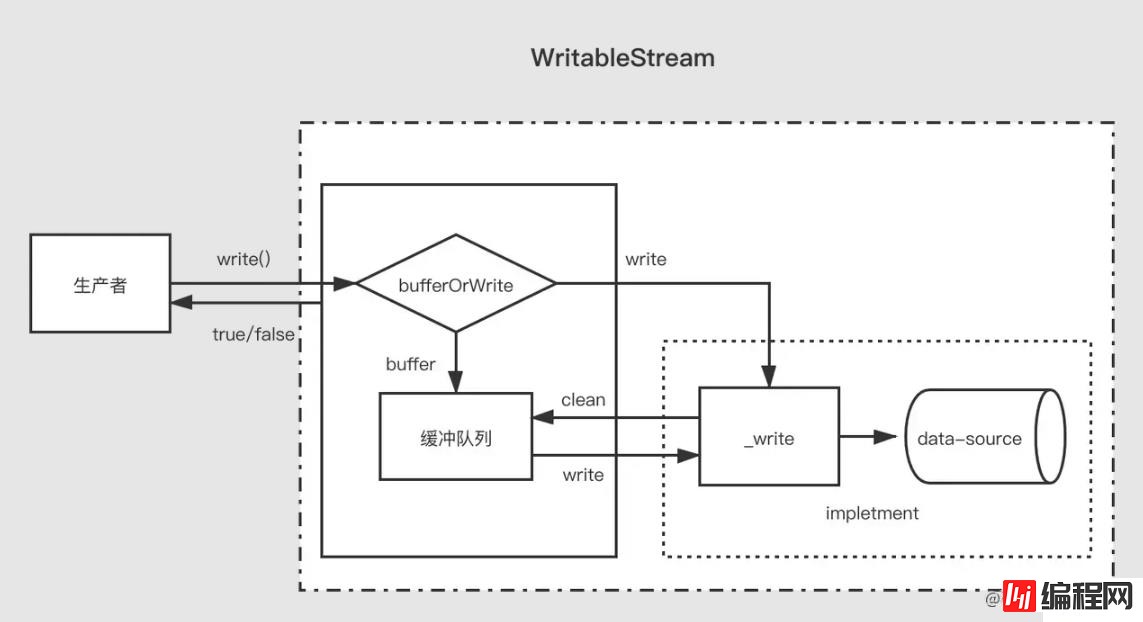
当生产者调用 write(chunk) 时,内部会根据一些状态(corked,writing等)选择是否缓存到缓冲队列中或者调用 _write,每次写完数据后,会尝试清空缓存队列中的数据。如果缓冲队列中的数据大小超出了浮标值(highWaterMark),消费者调用 write(chunk) 后会返回 false,这时候生产者应该停止继续写入。
那么什么时候可以继续写入呢?当缓冲中的数据都被成功 _write 之后,清空了缓冲队列后会触发 drain 事件,这时候生产者可以继续写入数据。
当生产者需要结束写入数据时,需要调用 stream.end 方法通知可写流结束。
const { Writable, Duplex } = require('stream')
let fileContent = ''
const myWritable = new Writable({
highWaterMark: 10,
write(chunk, encoding, callback) {// 会作为_write方法
setTimeout(()=>{
fileContent += chunk
callback()// 写入结束后调用
}, 500)
}
})
myWritable.on('close', ()=>{
console.log('close', fileContent)
})
myWritable.write('123123')// true
myWritable.write('123123')// false
myWritable.end()注意,在缓存池中数据到达浮标值后,此时缓存池中可能存在多个节点,在清空缓存池的过程中(循环调用_read),并不会向可读流一样尽量一次消费长度为浮标值的数据,而是每次消费一个缓冲区节点,即使这个缓冲区长度于浮标值不一致也是如此
const { Writable } = require('stream')
let fileContent = ''
const myWritable = new Writable({
highWaterMark: 10,
write(chunk, encoding, callback) {
setTimeout(()=>{
fileContent += chunk
console.log('消费', chunk.toString())
callback()// 写入结束后调用
}, 100)
}
})
myWritable.on('close', ()=>{
console.log('close', fileContent)
})
let count = 0
function productionData(){
let flag = true
while (count <= 20 && flag){
flag = myWritable.write(count.toString())
count++
}
if(count > 20){
myWritable.end()
}
}
productionData()
myWritable.on('drain', productionData)上述是一个浮标值为 10 的可写流,现在数据源是一个 0——20 到连续的数字字符串,productionData 用于写入数据。
首先第一次调用 myWritable.write("0") 时,因为缓存池不存在数据,所以 "0" 不进入缓存池,而是直接交给 _wirte,myWritable.write("0") 返回值为 true
当执行 myWritable.write("1") 时,因为 _wirte 的 callback 还未调用,表明上一次数据还未写入完,位置保证数据写入的有序性,只能创建一个缓冲区将 "1" 加入缓存池中。后面 2-9 都是如此
当执行 myWritable.write("10") 时,此时缓冲区长度为 9(1-9),还未到达浮标值, "10" 继续作为一个缓冲区加入缓存池中,此时缓存池长度变为 11,所以 myWritable.write("1") 返回 false,这意味着缓冲区的数据已经足够,我们需要等待 drain 事件通知时再生产数据。
100ms过后,_write("0", encoding, callback) 的 callback 被调用,表明 "0" 已经写入完成。然后会检查缓存池中是否存在数据,如果存在则会先调用 _read 消费缓存池的头节点("1"),然后继续重复这个过程直到缓存池为空后触发 drain 事件,再次执行 productionData
调用 myWritable.write("11"),触发第1步开始的过程,直到流结束。
在理解了可读流与可写流后,双工流就好理解了,双工流事实上是继承了可读流然后实现了可写流(源码是这么写的,但是应该说是同时实现了可读流和可写流更加好)。
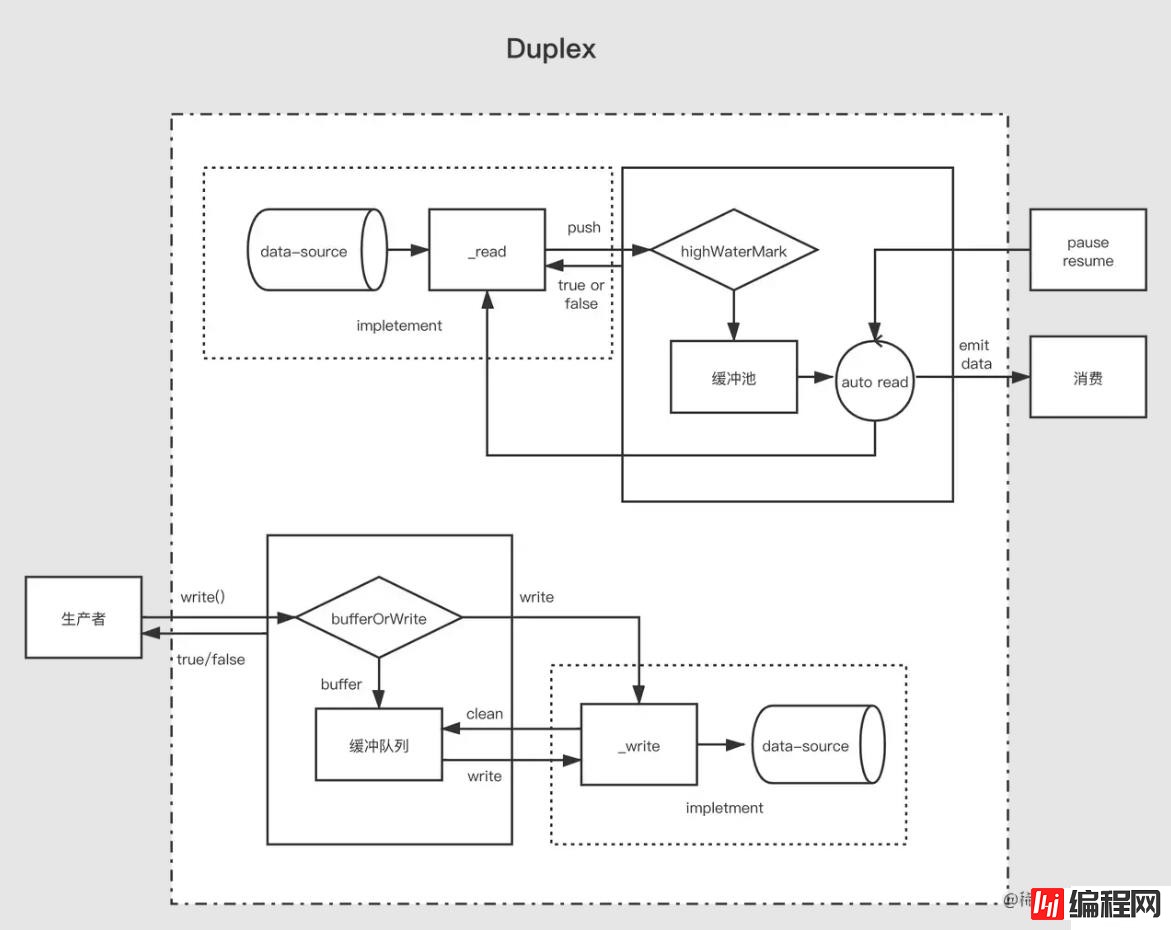
Duplex 流需要同时实现下面两个方法
实现 _read() 方法,为可读流生产数据
实现 _write() 方法,为可写流消费数据
上面两个方法如何实现在上面可写流可读流的部分已经介绍过了,这里需要注意的是,双工流是存在两个独立的缓存池分别提供给两个流,他们的数据源也不一样
以 NodeJs 的标准输入输出流为例:
当我们在控制台输入数据时会触发其 data 事件,这证明他有可读流的功能,每一次用户键入回车相当于调用可读的 push 方法推送生产的数据。
当我们调用其 write 方法时也可以向控制台输出内容,但是不会触发 data 事件,这说明他有可写流的功能,而且有独立的缓冲区,_write 方法的实现内容就是让控制台展示文字。
// 每当用户在控制台输入数据(_read),就会触发data事件,这是可读流的特性
process.stdin.on('data', data=>{
process.stdin.write(data);
})
// 每隔一秒向标准输入流生产数据(这是可写流的特性,会直接输出到控制台上),不会触发data
setInterval(()=>{
process.stdin.write('不是用户控制台输入的数据')
}, 1000)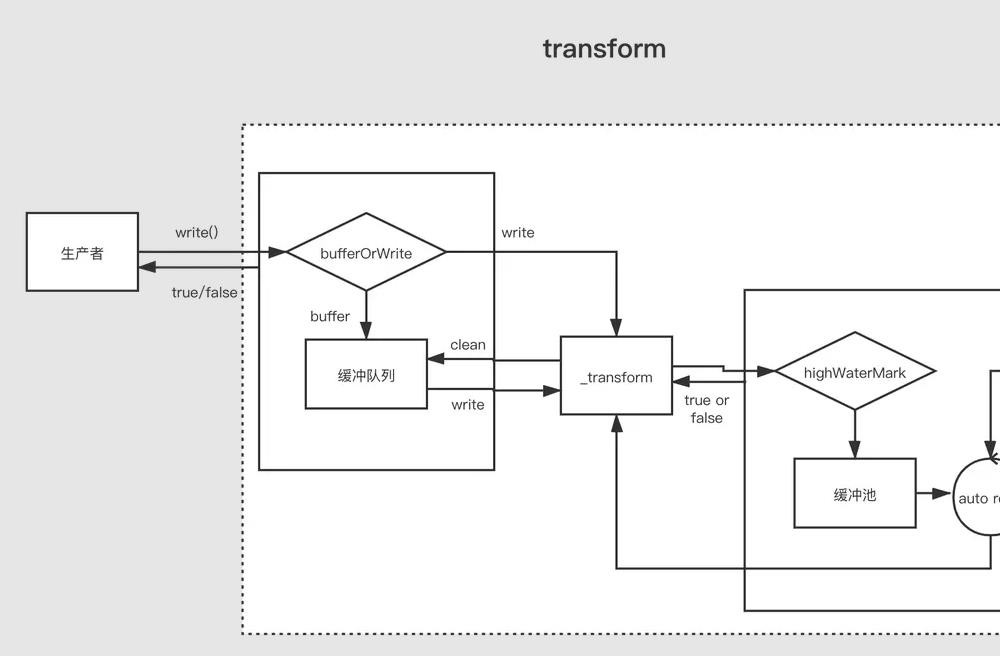
可以将 Duplex 流视为具有可写流的可读流。两者都是独立的,每个都有独立的内部缓冲区。读写事件独立发生。
Duplex Stream ------------------| Read <----- External Source You ------------------| Write -----> External Sink ------------------|
Transform 流是双工的,其中读写以因果关系进行。双工流的端点通过某种转换链接。读取要求发生写入。
Transform Stream --------------|-------------- You Write ----> ----> Read You --------------|--------------
对于创建 Transform 流,最重要的是要实现 _transform 方法而不是 _write 或者 _read。 _transform 中对可写流写入的数据做处理(消费)然后为可读流生产数据。
转换流还经常会实现一个 `_flush` 方法,他会在流结束前被调用,一般用于对流的末尾追加一些东西,例如压缩文件时的一些压缩信息就是在这里加上的const { write } = require('fs')
const { Transform, PassThrough } = require('stream')
const reurce = '1312123213124341234213423428354816273513461891468186499126412'
const transform = new Transform({
highWaterMark: 10,
transform(chunk ,encoding, callback){// 转换数据,调用push将转换结果加入缓存池
this.push(chunk.toString().replace('1', '@'))
callback()
},
flush(callback){// end触发前执行
this.push('<<<')
callback()
}
})
// write 不断写入数据
let count = 0
transform.write('>>>')
function productionData() {
let flag = true
while (count <= 20 && flag) {
flag = transform.write(count.toString())
count++
}
if (count > 20) {
transform.end()
}
}
productionData()
transform.on('drain', productionData)
let result = ''
transform.on('data', data=>{
result += data.toString()
})
transform.on('end', ()=>{
console.log(result)
// >>>0@23456789@0@1@2@3@4@5@6@7@8@920<<<
})管道是将上一个程序的输出作为下一个程序的输入,这是管道在 linux 中管道的作用。NodeJs 中的管道其实也类似,它管道用于连接两个流,上游的流的输出会作为下游的流的输入。
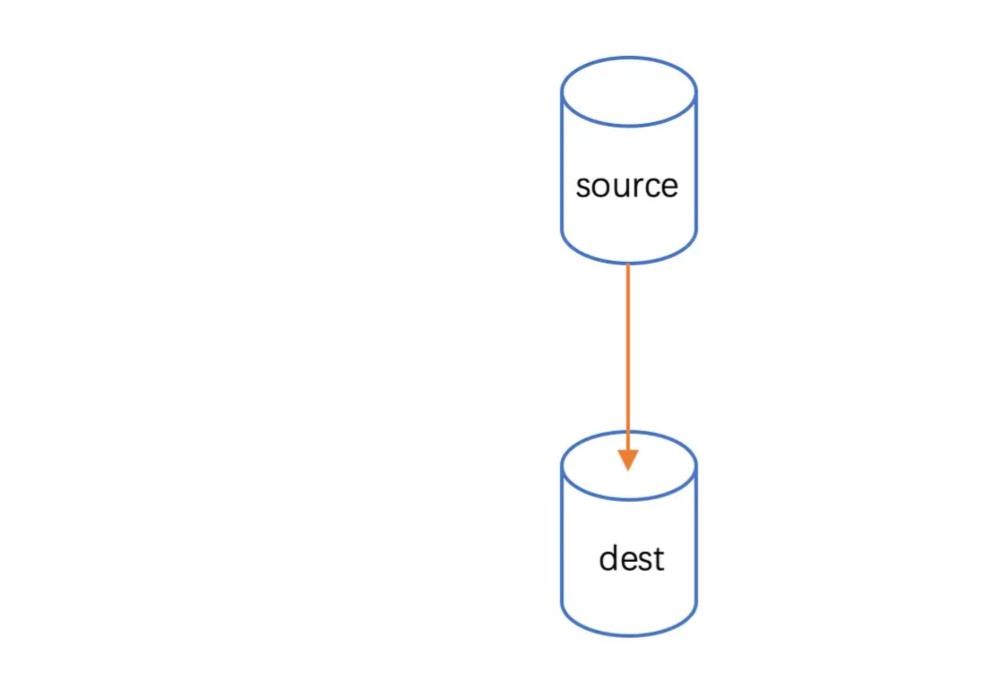
管道 sourec.pipe(dest, options) 要求 sourec 是可读的,dest是可写的。其返回值是 dest。
对于处于管道中间的流既是下一个流的上游也是上一个流的下游,所以其需要时一个可读可写的双工流,一般我们会使用转换流来作为管道中间的流。
Stream.prototype.pipe = function(dest, options) {
const source = this;
function ondata(chunk) {
if (dest.writable && dest.write(chunk) === false && source.pause) {
source.pause();
}
}
source.on('data', ondata);
function ondrain() {
if (source.readable && source.resume) {
source.resume();
}
}
dest.on('drain', ondrain);
// ...后面的代码省略
}pipe 的实现非常清晰,当上游的流发出 data 事件时会调用下游流的 write 方法写入数据,然后立即调用 source.pause() 使得上游变为暂停状态,这主要是为了防止背压。
当下游的流将数据消费完成后会调用 source.resume() 使上游再次变为流动状态。
我们实现一个将 data 文件中所有 1 替换为 @ 然后输出到 result 文件到管道。
const { Transform } = require('stream')
const { createReadStream, createWriteStream } = require('fs')
// 一个位于管道中的转换流
function createTransformStream(){
return new Transform({
transform(chunk, encoding, callback){
this.push(chunk.toString().replace(/1/g, '@'))
callback()
}
})
}
createReadStream('./data')
.pipe(createTransformStream())
.pipe(createWriteStream('./result'))在管道中只存在两个流时,其功能和转换流有点类似,都是将一个可读流与一个可写流串联起来,但是管道可以串联多个流。
感谢各位的阅读,以上就是“怎么理解Nodejs中的流”的内容了,经过本文的学习后,相信大家对怎么理解Nodejs中的流这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是编程网,小编将为大家推送更多相关知识点的文章,欢迎关注!
--结束END--
本文标题: 怎么理解Nodejs中的流
本文链接: https://www.lsjlt.com/news/97719.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-01-12
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0