Python 官方文档:入门教程 => 点击学习
目录项目地址所用到的技术开始编写爬虫项目地址 https://GitHub.com/aliyoge/fund_crawler_py 所用到的技术 IP代理池 多线程 爬虫 sql
https://GitHub.com/aliyoge/fund_crawler_py
首先,开始分析天天基金网的一些数据。经过抓包分析,可知: ./fundcode_search.js包含所有基金代码的数据。
根据基金代码,访问地址: fundgz.1234567.com.cn/js/ + 基金代码 + .js可以获取基金实时净值和估值信息。
根据基金代码,访问地址: fundf10.eastmoney.com/FundArcHivesDatas.aspx?type=jjcc&code= + 基金代码 + &topline=10&year=2021&month=3可以获取第一季度该基金所持仓的股票。
由于这些地址具有反爬机制,多次访问将会失败的情况。所以需要搭建IP代理池,用于反爬。搭建很简单,只需要将proxy_pool这个项目跑起来就行了。
# 通过这个方法就能获取代理
def get_proxy():
return requests.get("Http://127.0.0.1:5010/get/").JSON()搭建完IP代理池后,我们开始着手多线程爬取数据的工作。使用多线程,需要考虑到数据的读写顺序问题。这里使用python中的队列queue存储基金代码,不同线程分别从这个queue中获取基金代码,并访问指定基金的数据。因为queue的读取和写入是阻塞的,所以可确保该过程不会出现读取重复和读取丢失基金代码的情况。
# 获取所有基金代码
fund_code_list = get_fund_code()
fund_len = len(fund_code_list)
# 创建一个队列
fund_code_queue = queue.Queue(fund_len)
# 写入基金代码数据到队列
for i in range(fund_len):
# fund_code_list[i]也是list类型,其中该list中的第0个元素存放基金代码
fund_code_queue.put(fund_code_list[i][0])
现在开始编写获取所有基金的代码。
# 获取所有基金代码
def get_fund_code():
...
# 访问网页接口
req = requests.get("http://fund.eastmoney.com/js/fundcode_search.js",
timeout=5,
headers=header)
# 解析出基金代码存入list中
...
return fund_code_list
接下来是从队列中取出基金代码,同时获取基金详情和基金持仓的股票。
# 当队列不为空时
while not fund_code_queue.empty():
# 从队列读取一个基金代码
# 读取是阻塞操作
fund_code = fund_code_queue.get()
...
try:
# 使用该基金代码进行基金详情和股票持仓请求
...
获取基金详情
# 使用代理访问
req = requests.get(
"http://fundgz.1234567.com.cn/js/" + str(fund_code) + ".js",
proxies={"http": "http://{}".fORMat(proxy)},
timeout=3,
headers=header,
)
# 解析返回数据
...
获取持仓股票信息
# 获取股票投资明细
req = requests.get(
"http://fundf10.eastmoney.com/FundArchivesDatas.aspx?type=jjcc&code="
+ str(fund_code) + "&topline=10&year=2021&month=3",
proxies={"http": "http://{}".format(proxy)},
timeout=3,
headers=header,
)
# 解析返回数据
...
准备一个数据库,用于存储数据和对数据进行筛选分析。这里推荐一个方便的云数据库,一键创建,一键查询,十分方便,而且是免费的哦。前往MemFireDB注册一个账号就能使用。注册邀请码:6mxJl6、6mYjGY;

创建好数据库后,点击连接信息填入代码中,用于连接数据库。

# 初始化数据库连接:
engine = create_engine(
'postgresql+psycopg2://username:passWord@ip:5433/dbname')将数据写入数据库中。
with get_session() as s:
# create fund
...
if (create):
s.add(fund)
s.commit()
到这里,大部分工作已经完成了,我们在main函数中开启线程,开始爬取。
# 在一定范围内,线程数越多,速度越快
for i in range(50):
t = threading.Thread(target=get_fund_data, name="LoopThread" + str(i))
t.start()
等到爬虫运行完成之后,我们打开MemFireDB,点击对应数据库的SQL查询按钮,就可以查看我们爬取的数据。哇!我们获取到了6432条数据。

接下来让我们来看看这些基金最喜欢买哪些股票吧。输入SQL语句select poscode, posname, count(*) as count, cast(sum(poscost) as int) from fund group by poscode, posname order by count desc limit 10;
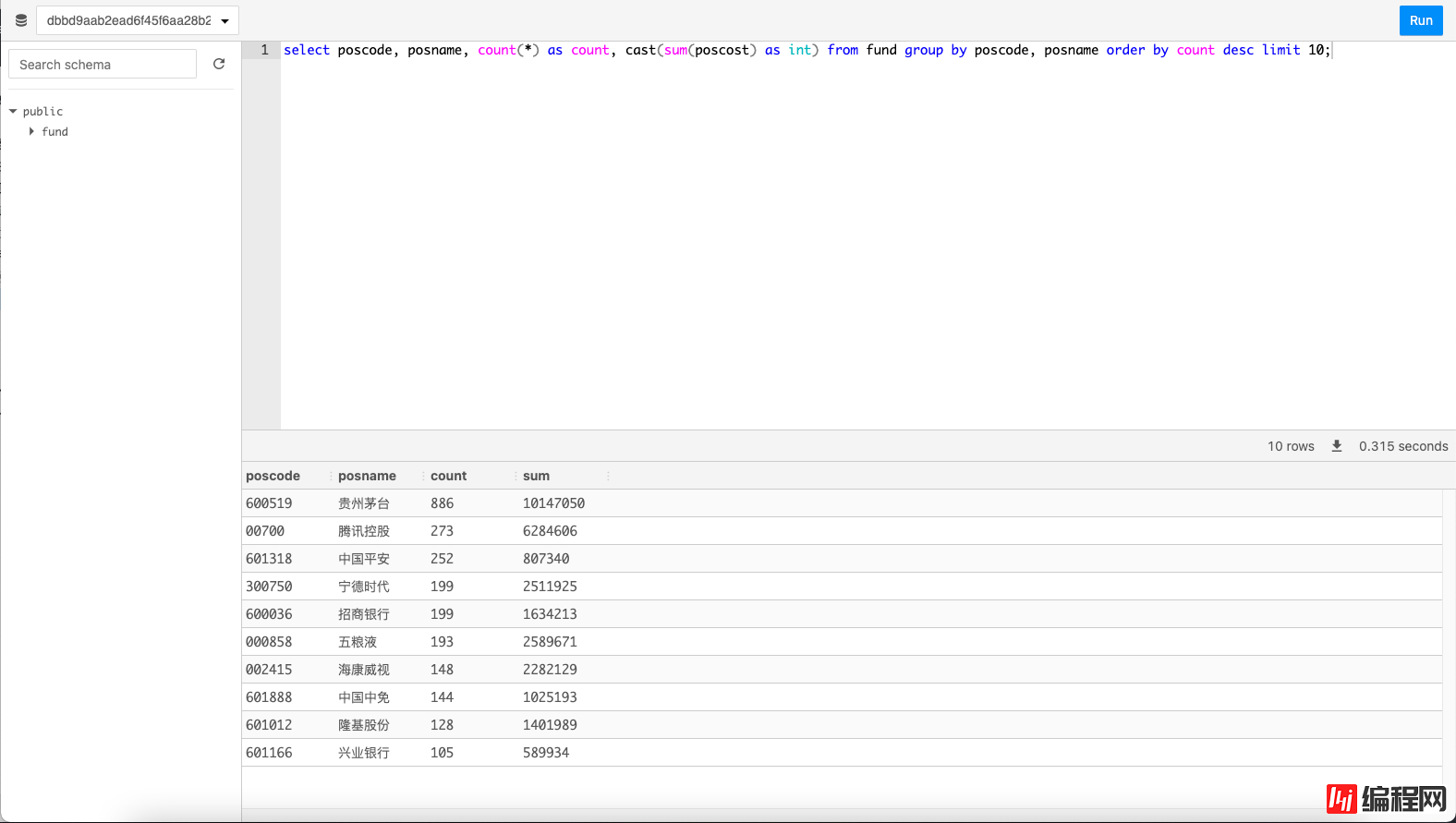
它就是茅台!
--结束END--
本文标题: python 简单的股票基金爬虫
本文链接: https://www.lsjlt.com/news/10885.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
下载Word文档到电脑,方便收藏和打印~
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作




0